广告推荐算法系列文章:
- 莫比乌斯: 百度的下一代query-ad匹配算法
- 百度凤巢分布式层次GPU参数服务器架构
- DIN: 阿里点击率预估之深度兴趣网络
- 基于Delaunay图的快速最大内积搜索算法
- DIEN: 阿里点击率预估之深度兴趣进化网络
- EBR: Facebook基于向量的检索
- 阿里巴巴电商推荐之十亿级商品embedding
Overall
这篇文章所介绍的模型,用于在用户没有输入搜索词来表达意图的时候,给用户推荐商品的场景。这里的收费方式一般是CPC,即Cost per Click,每次点击收费,提高CTR能直接提高收入,同时改进用户体验。
在DIN: 阿里点击率预估之深度兴趣网络中,我们介绍了Attention在阿里点击率预估中应用,重点则是针对某个候选广告,用attention对用户行为序列进行权重计算,得到用户针对这个候选广告的兴趣向量,然后去做点击率预估。
上面的做法能够捕捉到用户多样的兴趣,但是缺点就是用户行为序列中的条目是被等价对待的,并没有考虑到用户兴趣的漂移。
比如,随着风潮的变化,用户喜欢的衣服风格可能发生变化;类似的,用户在某个时间段会关注一类书籍,但是过了这个时间段,可能会关注其他类型的书籍,或者其他商品比如衣服。
综上,用户的兴趣有如下特点:
- 多样性,用户感兴趣的商品会有很多种类。
- 进化性,用户的兴趣会随着时间发生变化,包括在某种商品内的细粒度变化,或者不同种商品间的变化等。
所以,在论文[1]中,对用户的行为序列进行了建模,从而能捕捉到用户兴趣的漂移。
BaseModel
在介绍模型的改进之前,再来回顾一下基础模型。经典的CTR预估模型是Embedding + MLP。
对于阿里的广告点击率预估问题来说,有四大类特征:
- 用户信息: 例如性别,年龄等。
- 用户行为序列: 用户看过的商品序列。
- 广告: ad_id, shop_id等等
- 上下文: 时间,地点等。
大部分是离散特征,可以用one-hot进行编码表达。而对于商品来说,因为商品数目太多,使用one-hot不现实,所以使用密集编码,即给每个商品一个向量编码,然后对于用户行为序列中的每一个商品,取得对应的编码,将所有的商品向量编码拼接起来,得到行为序列的编码。
得到的Embedding之后,就可以将数据输入给MLP多层神经网络进行处理了。使用的损失函数为:

DIEN
DIEN,全称是Deep Interest Evolution Network,即用户兴趣进化网络。这个算法中用两层架构来抽取和使用用户兴趣特征:
- Interest Extractor Layer: 从用户行为序列中提取信息
- Interest Evolving Layer: 从用户行为序列中找到目标相关的兴趣,对其进行建模
兴趣抽取层
使用LSTM的变种GRU对用户行为序列进行建模。GRU可以达到和LSTM类似的结果但速度更快。

其中,σ是sigmoid操作,而◦是内积操作。
但是如果只用上面BaseModel的损失函数的话,是无法将GRU训练好的。因为最后的target只是针对一种兴趣的,所以GRU建模的序列上得不到足够的监督信息。为了解决这个问题,提出了一种辅助损失函数用来帮助训练GRU。
方法就是使用行为序列中的下一个行为来作为当前步隐含状态的监督信息,这是正例;另外还采样了一个其他的行为来作为负例。而行为都是embedding好的,所以和普通的GRU训练不同,在这里我们将行为embedding和隐含状态做内积然后再计算损失函数,计算公式如下:

其中,ebi是正例,带帽的ebi则是负例。
有了这个辅助损失后,就可以较好的用GRU建模行为序列。
最后的损失函数则是 L = Ltarget + alpha * Laux。
兴趣进化层
上面使用的GRU的隐含信息可以组成一个兴趣序列,而根据预测目标的不同,我们需要从兴趣序列中拿到不同的信息,这时候,attention机制就粉墨登场了。
Attention是在目标和GRU的每一个隐含状态间进行计算。计算公式如下,即在目标和隐含状态间用矩阵去做乘法,然后再做归一化。

基于上面的attention计算公式,我们再构建一个GRU来处理兴趣进化,提出了三种方法来构建这个GRU。
-
AIGRU: GRU + Attention Input
将抽取层的GRU的隐含状态乘以attention权重作为下一个GRU的输入。这种方法表现不是特别好,因为即使权重为0,输入给GRU后依然会改变GRU的隐含状态,影响兴趣进化的学习。
-
AGRU: Attention based GRU
用attention得到的权重来改变GRU中隐含状态的更新方式。

-
AUGRU: GRU with attention update gate
AGRU的一个变种,上面的AGRU用一个scalar替代了GRU的参数向量来做加权,使得GRU的能力变弱,这里做了改进,用权重来更新GRU的参数向量,然后用更新过的向量去更新GRU隐含状态。

显然,从描述中看,最后一种更全面,效果会更好。
算法架构
有了上面的两层,就得到了整个架构:

实验结果
在公开数据集上的实验,可以看到,DIEN能够带来1.9%和5.6%的提升。

在阿里工业数据集上的实验,相对于DIN,提升~1.2%
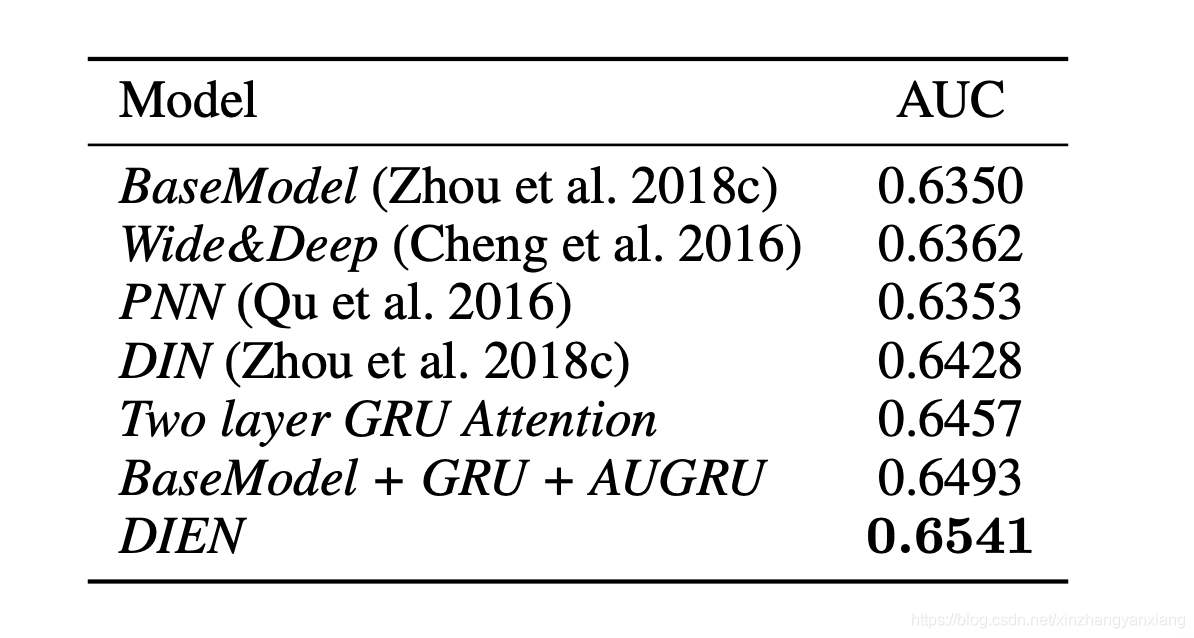
不同设计方案和辅助损失的作用实验,可以看到加上GRU后,相对于BaseModel能带来1.7%~2%的提升,加上辅助损失后,可以带来3.6%的提升。

线上实验,我看到了白花花的银子。

在线服务
在Online Serving上,采用了多种技术来进行优化:
- Element parallel GPU & kernel fusion
- Batching: 相近的request在一起执行来提高效率
- 基于Rocket的模型压缩,例如可以将GRU的隐含状态从128压缩到32。
第一条和第三条不太懂,后续关注。
总结
论文[1]用户行为序列进行建模,捕捉了用户兴趣进化信息,从而能提高CTR。技术上,使用GRU对序列建模,使用辅助损失来对GRU更好的训练,类似DIN,使用attention来对序列进行筛选,只对目标相关的兴趣进行序列建模,总体上,提升CTR达到20.7%,相当大的impact了。
码字不易,欢迎关注微信公众号【雨石记】。

参考文献
- [1]. Zhou, Guorui, et al. “Deep interest evolution network for click-through rate prediction.” Proceedings of the AAAI conference on artificial intelligence. Vol. 33. 2019.
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)