参考:Tensorflow教程-猫狗大战数据集
测试一张图片
获取一张图片
函数:def get_one_image(train):
- 输入参数:train,训练图片的路径
- 返回参数:image,从训练图片中随机抽取一张图片
n = len(train)
ind = np.random.randint(0, n)
img_dir = train[ind]
image = Image.open(img_dir)
plt.imshow(image)
image = image.resize([208, 208])
image = np.array(image)
return image
测试图片
函数:def evaluate_one_image():
with tf.Graph().as_default():
BATCH_SIZE = 1
N_CLASSES = 2
image = tf.cast(image_array, tf.float32)
image = tf.image.per_image_standardization(image)
image = tf.reshape(image, [1, 208, 208, 3])
logit = model.inference(image, BATCH_SIZE, N_CLASSES)
logit = tf.nn.softmax(logit)
x = tf.placeholder(tf.float32, shape=[208, 208, 3])
# you need to change the directories to yours.
logs_train_dir = 'D:/Study/Python/Projects/Cats_vs_Dogs/Logs/train'
saver = tf.train.Saver()
with tf.Session() as sess:
print("Reading checkpoints...")
ckpt = tf.train.get_checkpoint_state(logs_train_dir)
if ckpt and ckpt.model_checkpoint_path:
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
saver.restore(sess, ckpt.model_checkpoint_path)
print('Loading success, global_step is %s' % global_step)
else:
print('No checkpoint file found')
prediction = sess.run(logit, feed_dict={x: image_array})
max_index = np.argmax(prediction)
if max_index==0:
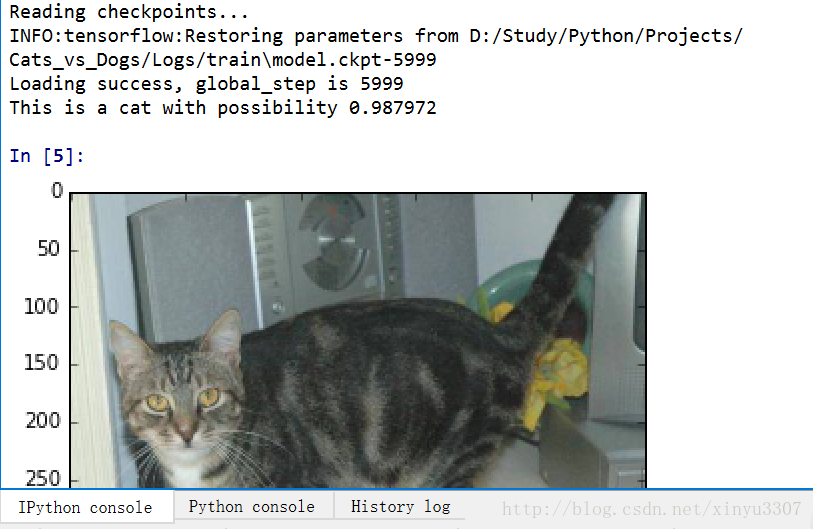
print('This is a cat with possibility %.6f' %prediction[:, 0])
else:
print('This is a dog with possibility %.6f' %prediction[:, 1])
训练过程中按步骤测试图片
在获取文件时,取出训练图片的20%作为测试数据
函数:def get_files(file_dir, ratio):中修改
#所有的img和lab的list
all_image_list = temp[:, 0]
all_label_list = temp[:, 1]
#将所得List分为两部分,一部分用来训练tra,一部分用来测试val
#ratio是测试集的比例
n_sample = len(all_label_list)
n_val = math.ceil(n_sample*ratio) #测试样本数
n_train = n_sample - n_val # 训练样本数
tra_images = all_image_list[0:n_train]
tra_labels = all_label_list[0:n_train]
tra_labels = [int(float(i)) for i in tra_labels]
val_images = all_image_list[n_train:-1]
val_labels = all_label_list[n_train:-1]
val_labels = [int(float(i)) for i in val_labels]
return tra_images,tra_labels,val_images,val_labels
函数:def get_files(file_dir, ratio):中修改
获取train和validation的batch
train_batch, train_label_batch = input_train_val_split.get_batch(train,
train_label,
IMG_W,
IMG_H,
BATCH_SIZE,
CAPACITY)
val_batch, val_label_batch = input_train_val_split.get_batch(val,
val_label,
IMG_W,
IMG_H,
BATCH_SIZE,
CAPACITY)
每隔200步,测试一批,同时记录log
if step % 200 == 0 or (step + 1) == MAX_STEP:
val_images, val_labels = sess.run([val_batch, val_label_batch])
val_loss, val_acc = sess.run([loss, acc],
feed_dict=)
print('** Step %d, val loss = %.2f, val accuracy = %.2f%% **' %(step, val_loss, val_acc*100.0))
summary_str = sess.run(summary_op)
val_writer.add_summary(summary_str, step)
结果
这张图片是猫的概率为0.987972,所用模型的训练步骤是6000步
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)