集成学习是一大类模型融合策略和方法的统称,其中包含多种集成学习的思想。
Boosting
Boosting方法训练基分类器时采用串行的方式,各个基分类器之间有依赖。
它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重。测试时,根据各层分类器的结果的加权得到最终结果。
Boosting的过程很类似于人类学习的过程 (如图) ,我们学习新知识的过程往往是迭代式的,第一遍学习的时候,我们会记住一部分知识,但往往也会犯一些错误,对于这些错误,我们的印象会很深。第二遍学习的时候,就会针对犯过错误的知识加强学习,以减少类似的错误发生。不断循环往复,直到犯错误的次数减少到很低的程度。

Boosting算法的实现:
import util
import numpy as np
import sys
import random
PRINT = True
random.seed(42)
np.random.seed(42)
def small_classify(y):
classifier, data = y
return classifier.classify(data)
class AdaBoostClassifier:
"""
AdaBoost classifier.
Note that the variable 'datum' in this code refers to a counter of features
(not to a raw samples.Datum).
"""
def __init__( self, legalLabels, max_iterations, weak_classifier, boosting_iterations):
self.legalLabels = legalLabels
self.boosting_iterations = boosting_iterations
self.classifiers = [weak_classifier(legalLabels, max_iterations) for _ in range(self.boosting_iterations)]
self.alphas = [0]*self.boosting_iterations
def train( self, trainingData, trainingLabels):
"""
The training loop trains weak learners with weights sequentially.
The self.classifiers are updated in each iteration and also the self.alphas
"""
self.features = trainingData[0].keys()
size_sampled_data = int(len(trainingData))
sampled_weights = [(1.0/size_sampled_data)] * size_sampled_data
for i in range(self.boosting_iterations):
self.classifiers[i].train(trainingData, trainingLabels, sampled_weights)
error = 0
for j in range(len(trainingData)):
if self.classifiers[i].classify([trainingData[j]])[0] != trainingLabels[j]:
error = error + sampled_weights[j]
for j in range(len(trainingData)):
if self.classifiers[i].classify([trainingData[j]])[0] == trainingLabels[j]:
sampled_weights[j] = sampled_weights[j] * (error/ (1 - error))
# Normalize the sampled_weight list
sum_of_weights = sum(sampled_weights)
for p in range(len(sampled_weights)):
sampled_weights[p] = sampled_weights[p] / sum_of_weights
self.alphas[i] = np.log((1 - error) / error)
#print "training loop: ", i
def classify( self, data):
"""
Classifies each datum as the label that most closely matches the prototype vector
for that label. This is done by taking a polling over the weak classifiers already trained.
See the assignment description for details.
Recall that a datum is a util.counter.
The function should return a list of labels where each label should be one of legaLabels.
"""
prediction = []
for i in range(len(data)):
guesses = []
for j in range(self.boosting_iterations):
guesses.append(self.classifiers[j].classify([data[i]])[0] * self.alphas[j])
prediction.append(int(np.sign(sum(guesses))))
return prediction
Bagging
Bagging与Boosting的串行训练方式不同,Bagging方法在训练过程中,各基分类器之间无强依赖,可以进行并行训练。其中很著名的算法之一是基于决策树基分类器的随机森林 (Random Forest) 。为了让基分类器之间互相独立,将训练集分为若干子集 (当训练样本数量较少时,子集之间可能有交叠)。Bagging方法更像是一个集体决策的过程,每个个体都进行单独学习,学习的内容可以相同,也可以不同,也可以部分重叠。但由于个体之间存在差异性,最终做出的判断不会完全一致。在最终做决策时,每个个体单独作出判断,再通过投票的方式做出最后的集体决策 (如图)。

我们再从消除基分类器的偏差和方差的角度来理解Boosting和Bagging方法的差异。基分类器,有时又被称为弱分类器,因为基分类器的错误率要大于集成分类器。基分类器的错误,是偏差和方差两种错误之和。偏差主要是由于分类器的表达能力有限导致的系统性错误,表现在训练误差不收敛。方差是由于分类器对于样本分布过于敏感,导致在训练样本数较少时,产生过拟合。
Boosting方法是通过逐步聚焦于基分类器分错的样本,减小集成分类器的偏差。Bagging方法则是采取分而治之的策略,通过对训练样本多次采样,并分别训练出多个不同模型,然后做综合,来减小集成分类器的方差。假设所有基分类器出错的概率是独立的,在某个测试样本上,用简单多数投票方法来集成结果,超过半数基分类器出错的概率会随着基分类器的数量增加而下降。
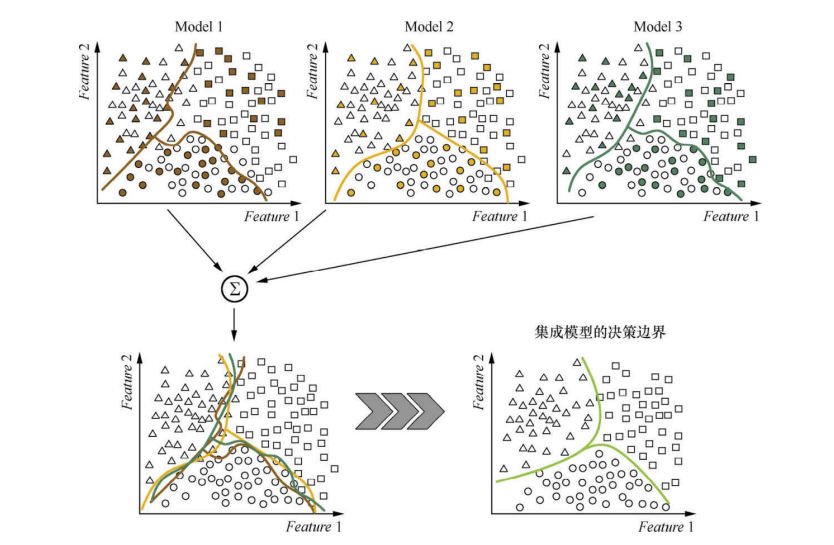
下图是Bagging算法的示意图,Model 1、Model 2、Model 3都是用训练集的个子集训练出来的,单独来看,它们的决策边界都很曲折,有过拟合的倾向。集成之后的模型(红线所示) 的决策边界就比各个独立的模型平滑了,这是由于集成的加权投票方法,减小了方差。
Bagging算法的实现:
import util
import numpy as np
import sys
import random
PRINT = True
random.seed(42)
np.random.seed(42)
class BaggingClassifier:
"""
Bagging classifier.
Note that the variable 'datum' in this code refers to a counter of features
(not to a raw samples.Datum).
"""
def __init__( self, legalLabels, max_iterations, weak_classifier, ratio, num_classifiers):
self.ratio = ratio
self.num_classifiers = num_classifiers
self.classifiers = [weak_classifier(legalLabels, max_iterations) for _ in range(self.num_classifiers)]
def train( self, trainingData, trainingLabels):
"""
The training loop samples from the data "num_classifiers" time. Size of each sample is
specified by "ratio". So len(sample)/len(trainingData) should equal ratio.
"""
self.features = trainingData[0].keys()
sample_size = int(self.ratio * len(trainingData))
for i in range(self.num_classifiers):
random_integers = np.random.randint(len(trainingData), size = sample_size)
sampled_data = []
sampled_labels = []
for choosen_element in random_integers:
sampled_data.append(trainingData[choosen_element])
sampled_labels.append(trainingLabels[choosen_element])
self.classifiers[i].train(sampled_data, sampled_labels, None)
def classify( self, data):
"""
Classifies each datum as the label that most closely matches the prototype vector
for that label. This is done by taking a polling over the weak classifiers already trained.
See the assignment description for details.
Recall that a datum is a util.counter.
The function should return a list of labels where each label should be one of legaLabels.
"""
prediction = []
for i in range(len(data)):
guesses = []
for j in range(self.num_classifiers):
guesses.append(self.classifiers[j].classify([data[i]])[0])
prediction.append(int(np.sign(sum(guesses))))
return prediction
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)