在过去的十年中,深度学习的一个持续的趋势是向更深更大的网络发展。尽管硬件性能迅速提高,但先进的深度学习模型仍在不断挑战GPU RAM的极限。因此,即使在今天,人们仍然希望找到一种方法来训练更大的模型,同时消耗更少的内存。这样做可以让我们更快地进行训练,使用更大的批处理大小,从而实现更高的GPU利用率。
在本文中,我们探讨了为深度神经网络优化内存分配的技术。我们讨论了几个备选解决方案。虽然我们的建议并非详尽无遗,但这些解决方案是有益的,可以让我们介绍主要的设计问题。
1 计算图
首先,让我们回顾一下计算图的概念。计算图描述了深度网络中操作之间的(数据流)依赖关系。图中执行的操作可以是细粒度的,也可以是粗粒度的。下图显示了两个计算图示例。

计算图的概念被显式地编码在像Theano和CGT这样的包中。在其他库中,计算图隐式地显示为网络配置文件。这些库的主要区别在于它们如何计算梯度。主要有两种方法:在同一图上执行反向传播,或者显式地表示反向路径来计算所需的梯度。

Caffe、CXXNet和Torch等库采用了前一种方法,在原始图形上执行支持。像Theano和CGT这样的库采用后一种方法,显式地表示向后路径。在这个讨论中,我们采用显式的反向路径方法,因为它具有一些易于优化的优点。
但是,我们应该强调的是,选择显式的向后路径方法并不局限于符号库,比如Theano和CGT。我们还可以使用显式的反向路径来计算基于层的库(它将前向和后向连接在一起)的梯度。下图展示了如何做到这一点。基本上,我们引入一个反向节点,它链接到图的正向节点并调用该层。在反向操作中调用layer.backward。
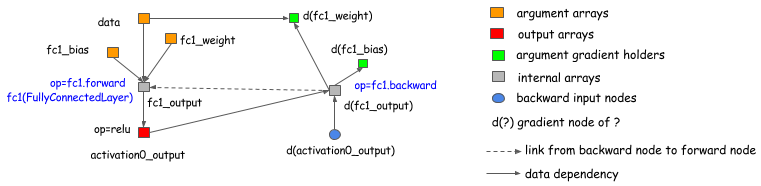
这个讨论几乎适用于所有现有的深度学习库。(库之间存在差异,例如高阶微分,但这超出了本主题的范围。)
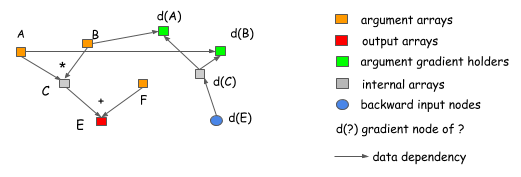
为什么显式向后路径更好?让我们用两个例子来解释它。第一个原因是显式的向后路径清楚地描述了计算之间的依赖关系。考虑下面的情况,我们想要得到A和b的梯度,从图中我们可以清楚地看到,d©梯度的计算并不依赖于F,这意味着我们可以在完成正向计算后立即释放F的内存。同样,C的内存也可以回收。
显式反向路径的另一个优点是能够拥有不同的反向路径,而不是正向路径的镜像。一个常见的例子是分割连接,如下图所示。
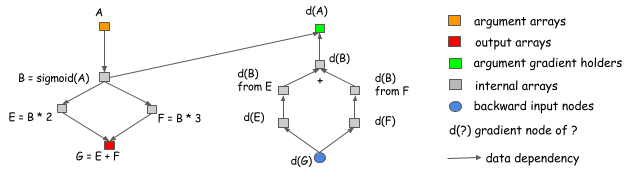
在本例中,B的输出由两个操作引用。如果我们想在同一个网络中做梯度计算,我们需要引入一个显式的分割层。这意味着我们也需要对前向计算进行分割。在这个图中,前进计算并不包含一个分离层,但图会在梯度回传到B之前自动插入一个梯度聚合节点,这帮助我们节省前向计算中的输出分离层的内存占用和数据复制开销。
如果我们采用显式的向后传递方法,向前传递和向后传递之间没有区别。我们只是按照时间顺序一步一步地进行计算。这使得显式的向后方法易于分析。我们只需要回答这个问题:如何为计算图的每个输出节点分配内存?
2 什么是可以优化的
如您所见,计算图是讨论内存分配优化技术的一种有用方法。我们已经展示了如何使用显式的后向图来节省一些内存。现在,让我们进一步研究优化,并看看如何为基准测试确定合理的基线。
假设我们要建立一个有n层的神经网络。通常,在实现神经网络时,我们需要为每一层的输出和反向传播过程中使用的梯度值分配节点空间。这意味着我们需要大约2n个内存单元。在使用显式向后图方法时,我们面临相同的要求,因为向后传递中的节点数量与向前传递中的节点数量大致相同。
2.1 就地操作
我们可以使用的最简单的技术之一是跨操作的就地内存共享。对于神经网络,我们通常可以将该技术应用于与激活函数相对应的操作。考虑以下情况,我们希望计算三个链式sigmoid函数的值。
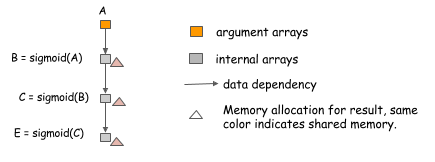
因为我们可以就地计算sigmoid,使用同一块的内存存储输入和输出,我们可以使用常量内存计算任意长度的sigmoid函数链。
注意:在实现就地优化时很容易出错。考虑以下情况,其中B的值不仅由C使用,而且由F使用。
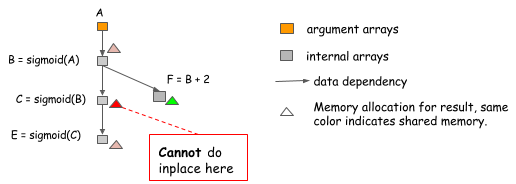
我们无法进行就地优化,因为在计算C=sigmoid(B)之后仍然需要B的值。对每个sigmoid操作进行就地优化的算法可能会落入这样的陷阱,所以我们需要小心何时可以使用它。
2.2 标准的内存共享
就地操作并不是我们可以共享内存的唯一地方。在下面的例子中,由于计算E后不再需要B的值,我们可以重用B的内存来保存E的结果。
内存共享不一定需要相同的数据形状。注意,在前面的例子中,B和E的形状可能不同。为了处理这种情况,我们可以分配一个大小等于B和E所需要的最大内存区域,并在它们之间共享它。
2.3 实际神经网络分配的例子
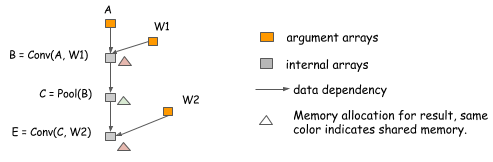
当然,这些只是玩具的例子,它们只涉及前向计算。但同样的想法也适用于真实的神经网络。下图显示了一个两层感知器的分配计划。
 在本例中:
在本例中:
- act1、d(fc1)、out、d(fc2)计算采用就地优化;
- d(act1)和d(A)之间共享内存。
3 内存分配算法
到目前为止,我们已经讨论了优化内存分配的一般技术。我们已经看到了需要避免的陷阱,在就地内存优化的例子中已经证明了这一点。那么,我们如何正确分配内存呢?这不是一个新问题。例如,它非常类似于编译器中的寄存器分配问题。也许我们可以借鉴一些技术。我们在这里并不是要对技术进行全面的回顾,而是要介绍一些简单但有用的技巧来解决这个问题。
关键问题是我们需要放置资源,这样它们才不会相互冲突。更具体地说,每个变量从计算到最后一次使用之间都有一个生命周期。在多层感知器的情况下,计算act1后fc1的生命周期结束。
其原则是只允许在生命周期不重叠的变量之间共享内存。有多种方法可以做到这一点。您可以构造每个变量作为节点的冲突图,并将具有重叠生命周期的变量之间的边链接起来,然后运行图形着色算法。这可能具有
O
(
n
2
)
O(n^2)
O(n2)复杂度,其中
n
n
n是图中节点的数量。这种方法计算量太大。
让我们考虑另一个简单的启发式。其思想是模拟遍历图的过程,并对依赖于节点的未来操作进行计数。

- 只有当前操作依赖于源(即count等于1)的时候,才可以使用就地优化;
- 只有当计数变为0时,内存可以回收到右上角的框中;
- 当我们需要新的内存时,我们可以从右上角的框中获取一个已释放的内存,或者分配一个新的内存。
注意:在模拟过程中,没有分配内存。相反,我们记录每个节点需要多少内存,并在最终的内存计划中分配最大的共享部分。
3.1 静态分配 VS. 动态分配
前面的策略完全模拟了命令式语言(如Python)中的动态内存分配过程。计数是每个内存对象的引用计数器,当引用计数器变为0时,对象将被垃圾收集。从这个意义上说,我们模拟动态内存分配一次,以创建一个静态分配计划。我们可以简单地使用动态分配和释放内存的命令式语言吗?
主要区别在于静态分配只完成一次,因此我们可以使用更复杂的算法。例如,我们可以搜索与所需内存块相似的内存大小。还可以使分配具有图意识。我们将在下一节讨论这个问题。动态分配给快速内存分配和垃圾回收带来了更大的压力。
对于希望依赖动态内存分配的用户来说,还有一点需要注意:不要不必要地引用对象。例如,如果我们组织一个列表中的所有节点,然后将它们存储在一个Net对象中,这些节点将永远不会被解除引用,我们也不会获得任何空间。不幸的是,这是一种常见的组织代码的方法。
3.2 为并行操作分配内存
在上一节中,我们讨论了如何模拟运行计算图的过程来获得静态分配计划。然而,优化并行计算也带来了其他挑战,因为资源共享和并行一般不可兼顾。让我们看一下同一个图的下面两个分配计划。
 如果我们进行从[1]到[8]的串行计算,这两个分配计划都是有效的。然而,左边的分配计划引入了额外的依赖项,这意味着我们不能并行运行[2]和[5]的计算。右边的计划可以。为了使计算并行化,我们需要更加小心。
如果我们进行从[1]到[8]的串行计算,这两个分配计划都是有效的。然而,左边的分配计划引入了额外的依赖项,这意味着我们不能并行运行[2]和[5]的计算。右边的计划可以。为了使计算并行化,我们需要更加小心。
3.3 正确和安全是第一位的
正确是我们的首要原则。这意味着以一种考虑到隐式依赖内存共享的方式执行。您可以通过向执行图中添加隐式依赖项边来实现这一点。或者,更简单的是,如果执行引擎能够识别可变变量,就像我们在依赖引擎设计的讨论中所描述的那样,按顺序推进操作,并写入表示相同内存区域的相同变量标记。
首先总是要使用一个安全的内存分配计划。这意味着永远不要将相同的内存分配给可以并行化的节点。当更需要减少内存时,这可能并不理想,而且当我们可以从同时在同一个GPU上执行的多个计算流中获益时,也不会得到太多好处。
3.4 尝试允许更多的并行化
现在我们可以安全地执行一些优化。一般的想法是尝试并鼓励不能并行化的节点之间的内存共享。您可以通过创建一个依赖关系图并在分配期间查询它来实现这一点,这将在构建时花费大约
O
(
n
2
)
O(n^2)
O(n2)的时间。我们还可以在这里使用启发式,例如,为图中的路径着色。如下图所示,当您试图找到图中最长的路径时,将它们涂上相同的颜色并继续。
 在获得节点的颜色之后,只允许(或鼓励)相同颜色的节点之间共享。这是祖先关系的更严格版本,但是如果只搜索第一个k路径,只需要O(n)时间。
在获得节点的颜色之后,只允许(或鼓励)相同颜色的节点之间共享。这是祖先关系的更严格版本,但是如果只搜索第一个k路径,只需要O(n)时间。
4 我们能节省多少内存呢?
我们已经讨论了一些技术和算法,您可以使用它们来压缩深度学习的内存。但使用这些技术可以真正节省多少内存呢?
对于已经为大型操作优化过的粗粒度操作图,可以将内存消耗减少大约一半。如果您正在优化符号库(如Theano)使用的细粒度计算网络,则可以进一步减少内存使用。本文的大部分思想启发了MXNet的设计。
此外,您还会注意到,与同时运行前向和后向传递相比,仅执行前向传递的内存成本非常低。这是因为如果只运行前向传递,内存重用会更多。
这里有两个结论:
- 使用计算图来分配内存;
- 对于深度学习模型,预测比训练消耗更少的内存。
文章翻译自:https://mxnet.incubator.apache.org/architecture/note_memory.html
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)