论文:Additive Margin Softmax for Face Verification
0 摘要
AM-Softmax,additive margin softmax。
人脸识别任务是一个度量学习任务,目的是使学习到的特征具有类内高度聚合、类间尽可能分离的特性。前面L-softmax和Sphereface中都通过乘积的方式解释了人脸识别中的角度间隔。本文作者提出了为softmax loss使用相加的角度间隔,效果更好并且理论上更合理。文中仍然强调和验证了特征归一化的必要性。在LFW和Megaface数据集上证明了AM-Softmax的先进性。
1 Softmax & A-Softmax
Softmax:
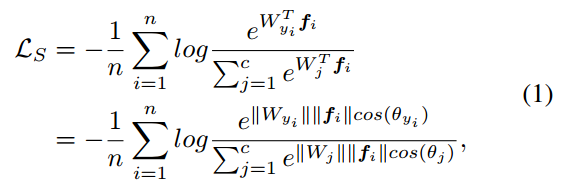
f
f
f表示最后一个全连接层的输入,
f
i
f_i
fi表示第
i
i
i个样本。
W
j
W_j
Wj表示最后一个全连接层的第
j
j
j列。
W
y
i
T
f
i
W_{y_i}^Tf_i
WyiTfi称为第
i
i
i个样本的target logit。
A-Softmax:
A-Softmax中对softmax进行了两项修改,一是对权重进行归一化(
∣
∣
W
∣
∣
=
1
||W|| = 1
∣∣W∣∣=1),而是修改
∣
∣
f
i
∣
∣
c
o
s
(
θ
)
||f_i||cos(\theta)
∣∣fi∣∣cos(θ)为
∣
∣
f
i
∣
∣
ψ
(
θ
y
i
)
||f_i||\psi(\theta_{y_i})
∣∣fi∣∣ψ(θyi).
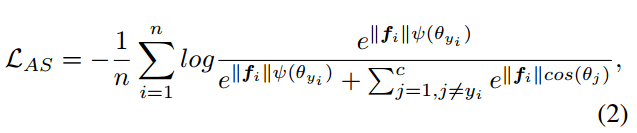
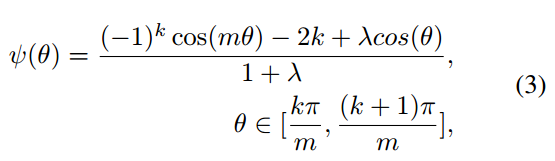
m是大于1的整数,
λ
\lambda
λ是一个超参数,用于控制损失函数的优化难易程度。在训练过程中,
λ
\lambda
λ初始值为1000,随着训练的进行慢慢减小以增大每一类样本角空间的聚合度。Sphereface论文中,作者设置的最优参数是
λ
=
5
,
m
=
4
\lambda = 5,m = 4
λ=5,m=4,通过图2的分析显示,这相当于
λ
=
0
,
m
=
1.5
\lambda = 0,m = 1.5
λ=0,m=1.5。

图2横轴是角度,纵轴是
W
y
i
T
f
i
W_{y_i}^Tf_i
WyiTfi。上图可以看出,
λ
=
5
,
m
=
4
\lambda = 5,m = 4
λ=5,m=4时的A-Softmax和m=0.35时的AM-Softmax在[0,90°]中取值很接近,而[0,90°]也是现实中
θ
\theta
θ的常见取值范围。
2 AM-Softmax
定义
ψ
(
θ
)
\psi(\theta)
ψ(θ)为:
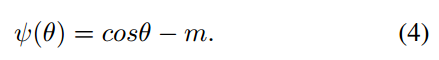
实现时,进行了权重和输入特征的归一化之后的输入为:
x
=
cos
(
θ
y
i
)
=
W
y
i
T
f
i
∣
∣
W
y
i
∣
∣
∣
∣
f
i
∣
∣
x = \cos(\theta_{yi})=\frac{W_{y_i}^Tf_i}{||W_{y_i}||||f_i||}
x=cos(θyi)=∣∣Wyi∣∣∣∣fi∣∣WyiTfi,所以前向过程中只需要计算:

反向传播时,
Ψ
′
(
x
)
=
1
\Psi^{'}(x) = 1
Ψ′(x)=1,计算上要比Sphereface容易。
作者这里还是使用余弦度量两个特征间的相似度,因此作者是对一个全连接层进行输入和权重的归一化来构建一个余弦层。然后对余弦值使用超参数s。最终的损失函数为:

作者发现如果通过训练过程学习超参数s的话,则会造成网络收敛速度非常慢。所以作者设置超参数s为人为设定的足够大的固定值。
在L-Softmax和A-Softmax的训练过程中,超参数
λ
\lambda
λ是逐渐减小的,但是作者人为控制
λ
\lambda
λ的递减策略又引入了很多难以调试的超参数。作者这里不使用
λ
\lambda
λ递减训练策略。并且发现,即便从一开始就固定超参数m,训练过程也可以很好的收敛。
几何解释:

对于传统的softmax损失,分类边界
P
0
P_0
P0处满足
W
1
T
P
0
W_1^TP_0
W1TP0 =
W
2
T
P
0
W_2^TP_0
W2TP0。
对于AM-Softmax,分类边界不再是一个向量,而是一个间隔区域。对于类别1的边界
P
1
P_1
P1,有
W
1
T
P
1
−
m
=
W
2
T
P
1
W_1^TP_1 - m = W_2^TP_1
W1TP1−m=W2TP1,得到
m
=
W
1
T
P
1
−
W
2
T
P
1
=
cos
(
θ
W
1
,
P
1
)
−
cos
(
θ
W
2
,
P
1
)
m = W_1^TP_1 - W_2^TP_1 = \cos(\theta_{W_1,P_1}) - \cos(\theta_{W_2,P_1})
m=W1TP1−W2TP1=cos(θW1,P1)−cos(θW2,P1)。同理对于类别2的边界
P
2
P_2
P2,有
W
2
T
P
2
−
m
=
W
1
T
P
2
W_2^TP_2 - m = W_1^TP_2
W2TP2−m=W1TP2,得到
m
=
W
2
T
P
2
−
W
1
T
P
2
=
cos
(
θ
W
2
,
P
2
)
−
cos
(
θ
W
1
,
P
2
)
m = W_2^TP_2 - W_1^TP_2 = \cos(\theta_{W_2,P_2}) - \cos(\theta_{W_1,P_2})
m=W2TP2−W1TP2=cos(θW2,P2)−cos(θW1,P2)。假设各类类内方差相同,那么就有
cos
(
θ
W
2
,
P
1
)
=
cos
(
θ
W
1
,
P
2
)
\cos(\theta_{W_2,P_1}) = \cos(\theta_{W_1,P_2})
cos(θW2,P1)=cos(θW1,P2)。所以
m
=
cos
(
θ
W
1
,
P
1
)
−
cos
(
θ
W
1
,
P
2
)
m = \cos(\theta_{W_1,P_1}) - \cos(\theta_{W_1,P_2})
m=cos(θW1,P1)−cos(θW1,P2)。也就是说,m等于对于类别1而言,间隔区域两个边界相对于类别1的余弦差值。
角度间隔和余弦间隔的区别:
SphereFace中,margin m是乘到
θ
\theta
θ上的,所以是以乘积的方式影响loss值。在AM-Softmax中,间隔m是从
cos
(
θ
)
\cos(\theta)
cos(θ)中减去的,是以相加的方式影响loss值的。
虽然
θ
\theta
θ和
cos
(
θ
)
\cos(\theta)
cos(θ)是一一对应的,但是由于cos函数引入了非线性,这两者还是有所区别的。
AM-Softmax的优化目标是cos相似度,而不是A-Softmax中的角度。如果使用传统的softmax函数时,这两者是相同的,因为
cos
θ
1
=
cos
θ
2
⇒
θ
1
=
θ
2
\cos \theta_1 = \cos \theta_2 \Rightarrow \theta_1 = \theta_2
cosθ1=cosθ2⇒θ1=θ2。但是,两者在计算上还是有所区别,如果我们优化的是
cos
(
θ
)
\cos(\theta)
cos(θ),那么在
θ
\theta
θ取值为0或者
π
\pi
π的地方,
cos
(
θ
)
\cos(\theta)
cos(θ)的取值比较密集。如果我们优化的是角度,那么在计算了
W
T
f
W^Tf
WTf之后,还需要进行
arccos
\arccos
arccos的操作,计算复杂度会更高。
总体来说,角度间隔在概念上比余弦间隔更合理,但是考虑到计算复杂度,余弦间隔在相同目的的情况下计算量更小。
特征归一化:
A-Softmax中只使用了权重归一化,但是AM-Softmax中在权重归一化的基础上又使用了特征归一化,那么该不该应用特征归一化呢?
答案是取决于图像的质量。L2-Softmax论文中指出了高质量图像的特征范数更大。
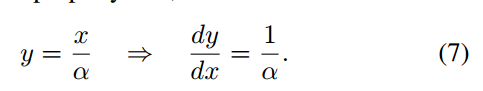
从上面式子可以看出,进行归一化操作之后,范数越小的特征相比范数更大的特征,梯度被放大的倍数越大。那么网络就会更加注意对这些低质量图像的拟合。这样做很类似于难例挖掘,因此对于低质量的图像集,特征归一化还是很必要的。

使用了特征归一化之后,对于范数很小的特征,梯度值可能很大,有可能造成梯度爆炸。作者认为理想的梯度应该是介于上述两条曲线之间,这个也是后面需要进一步研究的问题。
可视化特征:

3 实验
超参数:
实验中,s固定为30.m的值经过实验证明取0.35到0.4时效果最好。
在LFW和MegaFace上的实验效果:

 AM-Softmax在LFW和MegaFace数据集上比A-Softmax效果要更好。
AM-Softmax在LFW和MegaFace数据集上比A-Softmax效果要更好。
4 总结
AM-Softmax : 特征归一化,权重归一化,优化目标
cos
(
θ
)
−
m
\cos(\theta) - m
cos(θ)−m。
超参数:s=30,m取0.35/0.4,作者认为如何自动去学习间隔m的值以及如何去解释指定类/样本的间隔依然值得继续研究。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)