看到https://www.cnblogs.com/derek1184405959/p/9446544.html项目:爬取房天下网站全国所有城市的新房和二手房信息和其他博客的代码,因为网站的更新或者其他原因都不能正确爬取数据并存储
https://blog.csdn.net/qq_35649945/article/details/92729815 若将数据进行多种方式存储参考此博客
对爬取数据进行分析https://blog.csdn.net/qq_43609802/article/details/106355722
爬取结果


网站url分析
1.获取所有城市url
https://www.fang.com/SoufunFamily.htm
例如:https://cq.fang.com/
2.新房url
https://sz.newhouse.fang.com/house/s/
3.二手房url
之前 https://esf.sh.fang.com/
现在https://sh.esf.fang.com/
4.北京新房和二手房url规则不同
https://newhouse.fang.com/house/s/
https://esf.fang.com/
注意和之前的URL的不同,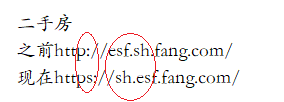

不改变的话会在爬虫过程一直发生重定向
https://blog.csdn.net/qq_43609802/article/details/106353479已经注意到这个问题并解决了
创建项目
cd 目标目录
scrapy startproject fang
cd fang
scrapy genspider sfw fang.com
在项目中新建 start.py文件
from scrapy import cmdline
cmdline.execute("scrapy crawl sfw_spider".split())
分析网页
获取省和市
注意:当市有多行时,第二行开始就没有了省份,需要作出判断,为市添加对应的省份

def parse(self, response):
trs=response.xpath('.//div[@class="outCont"]//tr')
provice = None
for tr in trs:
# 排除掉第一个td,两个第二个和第三个td标签
tds = tr.xpath(".//td[not(@class)]")
provice_td = tds[0]
provice_text = provice_td.xpath(".//text()").get()
# 如果第二个td里面是空值,则使用上个td的省份的值
provice_text = re.sub(r"\s", "", provice_text)
if provice_text:
provice = provice_text
# 排除海外城市
if provice == '其它':
continue
获取城市URL进行新房和二手房URL拼接
city_td=tds[1]
city_links = city_td.xpath(".//a")
for city_link in city_links:
city = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
# 下面通过获取的city_url拼接出新房和二手房的url链接
# 城市url:https://sz.fang.com/
# 新房url:https://sz.newhouse.fang.com/house/s/
# 二手房:https://sz.esf.fang.com/
url_module = re.split('[.//]',city_url)
scheme = 'https://'#url_module[0] =http: 使用这个会重定向到https:
domain = url_module[2] # cq.fang.com/
if 'bj' in domain:
newhouse_url = 'https://newhouse.fang.com/house/s/'
esf_url = 'https://esf.fang.com/'
else:
# 新房url
newhouse_url = scheme + domain + ".newhouse." + "fang.com/house/s/"
# 二手房url
esf_url = scheme + domain + ".esf.fang.com"
print("新房链接:",newhouse_url)
print("二手房链接:",esf_url)
获取新房页面的信息
def parse_newhouse(self,response):
#新房
provice,city = response.meta.get('info')
lis=response.xpath("//div[contains(@class,'nl_con')]/ul/li")
for li in lis:
name=li.xpath('.//div[@class="nlcd_name"]/a/text()').get()
#print(name)
if name:
name = re.sub(r"\s", "", name)
house_type_list = li.xpath(".//div[contains(@class,'house_type')]/a/text()").getall()
house_type_list = list(map(lambda x: re.sub(r"\s", "", x), house_type_list))
rooms = list(filter(lambda x: x.endswith("居"), house_type_list))
# 面积
area = "".join(li.xpath(".//div[contains(@class,'house_type')]/text()").getall())
area = re.sub(r"\s|-|/", "", area)
# 地址
address = li.xpath(".//div[@class='address']/a/@title").get()
address = re.sub(r"[请选择]", "", address)
sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get()
price = "".join(li.xpath(".//div[@class='nhouse_price']//text()").getall())
price = re.sub(r"\s|广告|\t|\n", "", price)
# 详情页url
origin_url = li.xpath(".//div[@class='nlcd_name']/a/@href").get()
item = NewHouseItem(
name=name,
rooms=rooms,
area=area,
address=address,
sale=sale,
price=price,
origin_url=origin_url,
provice=provice,
city=city
)
yield item
下一页
meta里面可以携带一些参数信息放到Request里面,在callback函数里面通过response获取
next_url = response.xpath("//div[@class='page']//a[@class='next']/@href").get()
if next_url:
yield scrapy.Request(url=response.urljoin(next_url),
callback=self.parse_newhouse,
meta={'info': (provice, city)}
)
爬取数据发现爬取北京只有 100次大概只爬取了5 6页的样子,通过查找发现了问题

会发现在后面的几页中,已经没有了class=‘next’的a标签,所以我们应该使用其他的方法,分析页面可以发现当你在某一页的时候,该页的span标签的class属性会变成class=‘on’,后面几页依旧如此,所以我们只需要定位到该页的a标签,然后找到它下一个的兄弟节点,就可以提取出来下一页url地址。而在xpath中,便是提供了这一方法
next_url = response.xpath("//div[@class='page']//a[@class='active']/following-sibling::a[1]/@href").get()
修改完数据之后每个城市可以爬取数据1000+条
同理二手房代码如下
next_url = response.xpath("//div[@class='page_al']//span[@class='on']/following-sibling::span[1]/a/@href").get()

代码感觉没啥问题,但是爬取结果还是不对
next_url = response.xpath("//div[@class='page_al']//p[1]/a/@href").extract_first() 有博客是这样写的,get() 、getall() 方法是新的方法,extract_first()、extract() 方法是旧的方法。
完整代码
items.py:Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误,可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item,以下我创建出NewFangItem和EsfFangItem两个item类,用来存放爬取到的房源信息。
import scrapy
class NewHouseItem(scrapy.Item):
#省份
provice = scrapy.Field()
# 城市
city = scrapy.Field()
# 小区
name = scrapy.Field()
# 价格
price = scrapy.Field()
# 几居,是个列表
rooms = scrapy.Field()
# 面积
area = scrapy.Field()
# 地址
address = scrapy.Field()
# 是否在售
sale = scrapy.Field()
# 房天下详情页面的url
origin_url = scrapy.Field()
class ESFHouseItem(scrapy.Item):
# 省份
provice = scrapy.Field()
# 城市
city = scrapy.Field()
# 小区名字
name = scrapy.Field()
# 几室几厅
rooms = scrapy.Field()
# 层
floor = scrapy.Field()
# 朝向
toward = scrapy.Field()
# 年代
year = scrapy.Field()
# 地址
address = scrapy.Field()
# 建筑面积
area = scrapy.Field()
# 总价
price = scrapy.Field()
# 单价
unit = scrapy.Field()
# 详情页url
origin_url = scrapy.Field()
SfwSpider类spiders/sfw.py
import scrapy
import re
from fang.items import NewHouseItem,ESFHouseItem
class SfwSpider(scrapy.Spider):
name = 'sfw'
allowed_domains = ['fang.com']
start_urls = ['https://www.fang.com/SoufunFamily.htm']
def parse(self, response):
trs=response.xpath('.//div[@class="outCont"]//tr')
provice = None
for tr in trs:
# 排除掉第一个td,两个第二个和第三个td标签
tds = tr.xpath(".//td[not(@class)]")
provice_td = tds[0]
provice_text = provice_td.xpath(".//text()").get()
# 如果第二个td里面是空值,则使用上个td的省份的值
provice_text = re.sub(r"\s", "", provice_text)
if provice_text:
provice = provice_text
# 排除海外城市
if provice == '其它':
continue
city_td=tds[1]
city_links = city_td.xpath(".//a")
for city_link in city_links:
city = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
# print("省份:",provice)
# print("城市:",city)
# print("城市链接:",city_url)
# 下面通过获取的city_url拼接出新房和二手房的url链接
# 城市url:https://sz.fang.com/
# 新房url:https://sz.newhouse.fang.com/house/s/
# 二手房:https://sz.esf.fang.com/
url_module = re.split('[.//]',city_url)
scheme = 'https://'#url_module[0] =http: 使用这个会重定向到https:
domain = url_module[2] # cq.fang.com/
if 'bj' in domain:
newhouse_url = 'https://newhouse.fang.com/house/s/'
esf_url = 'https://esf.fang.com/'
else:
# 新房url
newhouse_url = scheme + domain + ".newhouse." + "fang.com/house/s/"
# 二手房url
esf_url = scheme + domain + ".esf.fang.com"
#print("新房链接:",newhouse_url)
#print("二手房链接:",esf_url)
yield scrapy.Request(url=newhouse_url,callback=self.parse_newhouse,
meta={'info': (provice, city)}
)
yield scrapy.Request(url=esf_url,callback=self.parse_esf,meta={'info': (provice, city)})
break#只获取了表格中一行城市的数据
def parse_newhouse(self,response):
#新房
provice,city = response.meta.get('info')
lis=response.xpath("//div[contains(@class,'nl_con')]/ul/li")
for li in lis:
name=li.xpath('.//div[@class="nlcd_name"]/a/text()').get()
#print(name)
if name:
name = re.sub(r"\s", "", name)
house_type_list = li.xpath(".//div[contains(@class,'house_type')]/a/text()").getall()
house_type_list = list(map(lambda x: re.sub(r"\s", "", x), house_type_list))
rooms = list(filter(lambda x: x.endswith("居"), house_type_list))
# 面积
area = "".join(li.xpath(".//div[contains(@class,'house_type')]/text()").getall())
area = re.sub(r"\s|-|/", "", area)
# 地址
address = li.xpath(".//div[@class='address']/a/@title").get()
address = re.sub(r"[请选择]", "", address)
sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get()
price = "".join(li.xpath(".//div[@class='nhouse_price']//text()").getall())
price = re.sub(r"\s|广告|\t|\n", "", price)
# 详情页url
origin_url = li.xpath(".//div[@class='nlcd_name']/a/@href").get()
item = NewHouseItem(
name=name,
rooms=rooms,
area=area,
address=address,
sale=sale,
price=price,
origin_url=origin_url,
provice=provice,
city=city
)
yield item
#next_url = response.xpath("//div[@class='page']//a[@class='next']/@href").get()
next_url = response.xpath("//div[@class='page']//a[@class='active']/following-sibling::a[1]/@href").get()
next_url = response.urljoin(next_url)
if next_url:
yield scrapy.Request(url=response.urljoin(next_url),
callback=self.parse_newhouse,
meta={'info': (provice, city)}
)
def parse_esf(self,response):
#二手房
provice, city = response.meta.get('info')
dls = response.xpath("//div[@class='shop_list shop_list_4']/dl")
for dl in dls:
item = ESFHouseItem(provice=provice, city=city)
name=dl.xpath(".//span[@class='tit_shop']/text()").get()
if name:
name = re.sub(r"\s", "", name)
print(name)
infos = dl.xpath(".//p[@class='tel_shop']/text()").getall()
infos = list(map(lambda x: re.sub(r"\s", "", x), infos))
for info in infos:
if "厅" in info:
item["rooms"] = info
elif '层' in info:
item["floor"] = info
elif '向' in info:
item['toward'] = info
elif '㎡' in info:
item['area'] = info
elif '年建' in info:
item['year'] = re.sub("年建", "", info)
item['address'] = dl.xpath(".//p[@class='add_shop']/span/text()").get()
# 总价
price= "".join(dl.xpath(".//span[@class='red']//text()").getall())
price = re.sub(r"\s|广告|\t|\n", "", price)
item['price'] =price
# 单价
item['unit'] = dl.xpath(".//dd[@class='price_right']/span[2]/text()").get()
item['name'] = name
detail = dl.xpath(".//h4[@class='clearfix']/a/@href").get()
item['origin_url'] = response.urljoin(detail)
print(item)
yield item
#下一页
next_url = response.xpath("//div[@class='page_al']//span[@class='on']/following-sibling::span[1]/a/@href").get()
#next_url = response.xpath("//div[@class='page_al']/p/a/@href").get()
if next_url:
yield scrapy.Request(url=response.urljoin(next_url),
callback=self.parse_esf,
meta={'info': (provice, city)}
)
pipelines.py:当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。以下pipeline将所有(从所有’spider’中)爬取到的item,存储到csv、json中(也可以存储到mysql数据库等文件中需要先创建好数据库和数据表),:
注意:我们使用了NewHouseItem,ESFHouseItem需要在代码中加入以下语句确保数据不会混合存储,我之前看网上很多代码不包含此句,得到的文件里面既有新房数据又有二手房数据
if isinstance(item, NewHouseItem):
self.newhouse_exporter.export_item(item)
from scrapy.exporters import JsonLinesItemExporter
from fang.items import NewHouseItem,ESFHouseItem
import csv
class FangPipeline:
def __init__(self):
self.newhouse_fp = open('newhouse.json', 'wb')
self.esfhouse_fp = open('esfhouse.json', 'wb')
self.newhouse_exporter = JsonLinesItemExporter(self.newhouse_fp, ensure_ascii=False)
self.esfhouse_exporter = JsonLinesItemExporter(self.esfhouse_fp, ensure_ascii=False)
def process_item(self, item, spider):
if isinstance(item, NewHouseItem):
self.newhouse_exporter.export_item(item)
elif isinstance(item, ESFHouseItem):
self.esfhouse_exporter.export_item(item)
return item
def close_spider(self, spider):
self.newhouse_fp.close()
self.esfhouse_fp.close()
class FangCSVPipeline(object):
def __init__(self):
print("开始写入...")
self.f1 = open('new_house.csv', 'w', newline='')
self.write1 = csv.writer(self.f1)
self.write1.writerow(["城市", "小区名称", "价格", "几居",
"面积", "地址", "行政区", "是否在售", "详细url"])
self.f2 = open('esf_house1.csv', 'w', newline='')
self.write2 = csv.writer(self.f2)
self.write2.writerow(["城市", "小区的名字", "几居", "层", "朝向",
"年代", "地址", "建筑面积", "总价", "单价", "详细的url"])
self.f3 = open('rent_house.csv', 'w', newline='')
self.write3 = csv.writer(self.f3)
self.write3.writerow(['城市', '标题', '房间数', '平方数',
'价格', '地址', '交通描述', '区', '房间朝向'])
def process_item(self, item, spider):
print("正在写入...")
if isinstance(item, NewHouseItem):
self.write1.writerow([item['city'], item['name'], item['price'],
item['rooms'], item['area'], item['address'], item['district'], item['sale']
, item['origin_url']])
elif isinstance(item, ESFHouseItem):
self.write2.writerow([item['city'], item['name'], item['rooms'],
item['floor'], item['toward'], item['year'], item['address'], item['area']
, item['price'], item['unit'], item['origin_url']])
return item# elif isinstance(item, RenthousescrapyItem):
# self.write3.writerow([item['city'], item['title'], item['rooms'], item['area'], item['price']
# , item['address'], item['traffic'], item['region'],
# item['direction']])
def close_spider(self, item, spider):
print("写入完成...")
self.f1.close()
self.f2.close()
#self.f3.close()
middleware.py:下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)
设置随机请求头减小被反爬虫识别的概率(也可以增加使用代理ip),编写完后需要在setting中进行配置:
import random
class UserAgentDownloadMiddleware(object):
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
]
def process_request(self,request,spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agent
settings.py:Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL等。
进行配置:ROBOTSTXT_OBEY = False
开启item_pipelne:ITEM_PIPELINES = { 'fang.pipelines.FangPipeline': 300, }
开启下载器中间件
DOWNLOADER_MIDDLEWARES = {
'fang.middlewares.UserAgentDownloadMiddleware': 543,
}
完成代码后运行start文件
如发现其他问题或有解决错误的方法可以评论或者私信
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)