141. 环形链表
难度简单986
给定一个链表,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
如果链表中存在环,则返回 true 。 否则,返回 false 。
进阶:
你能用 O(1)(即,常量)内存解决此问题吗?
示例 1:
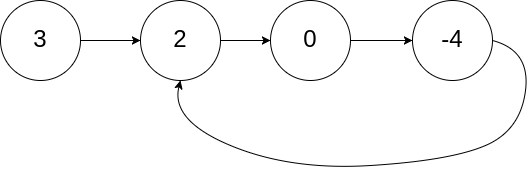
输入:head = [3,2,0,-4], pos = 1 输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
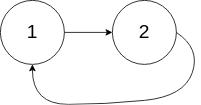
输入:head = [1,2], pos = 0 输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1输出:false
解释:链表中没有环。


class Solution():
def hasCycle(self, head):
"""
:type head: ListNode
:rtype: bool
"""
if head is None:
return False
seen = set()
while head:
if head in seen:
return True
else:
seen.add(head)
head=head.next
return False

原因如下:列表数据有序,可重复,查找某个元素方式为逐个遍历;
时间复杂度为列表的长度,即从第一个元素遍历到最后一个元素为止,O(len(list))
集合数据无序,不可重复,查找某个元素方式为哈希。即某个元素通过哈希计算,他的位置永远固定(顺序却不按输入元素顺序,解释了为什么集合无序),查询时通过哈希即可一次找到该元素。
时间复杂度为O(1)

方法二:快慢指针
class Solution():
def hasCycle(self, head):
"""
:type head: ListNode
:rtype: bool
"""
if head is None:
return False
node1 = head # 走一步
node2 = head # 走两步
while node2.next and node2.next.next:
node1 = node1.next
node2 = node2.next.next
if node1 == node2:
return True
return False

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)