链表常用操作
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)
from collections import deque
linkedlist=deque()
#Add element
#Time Complexity: 0(1)
linkedlist.append( 1)
linkedlist.append(2)
linkedlist.append( 3)#[1,2,3]
print( linkedlist)
#Insert element
#Time Complexity: 0(N)
linkedlist.insert(2,99)#[1,2,99,3]
print( linkedlist)
# Access e lement
# Time Complexity: 0(N )
element = linkedlist[2 ]
# 99
print( element )
# Search e lement
# Time Complexity: 0(N )
index = linkedlist. index(99 )
#2
print(index)
# Update element 查找+更改
# Time Complexity: 0(N )
linkedlist[2] = 88
# [1,2,88,3 ]
print( linkedlist )
# remove e lement
# Time Complexity: 0(N)
# del linkedlist[2 ]
linkedlist. remove( 88 )
# [1,2,3]
print( linkedlist )
链表练习
203. 移除链表元素
难度简单549收藏分享切换为英文接收动态反馈
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
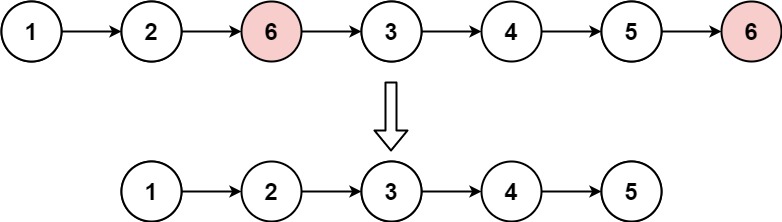
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
增加头结点

# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeElements(self, head: ListNode, val: int) -> ListNode:
while(head and head.val==val):
head=head.next
if head is None:
return head;
pre=head
while pre.next:
if(pre.next.val==val):
pre.next=pre.next.next
else:
pre= pre.next
return head
双指针 (删除头结点时另做考虑)注意可能头结点需要删除几次
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def removeElements(head: ListNode, val):
pre = ListNode(0)
pre.next = head
a = pre
while head is not None:
if (head.val == val):
a.next = head.next
else:
a = a.next
head = head.next
return pre.next

递归实现
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeElements(self, head: ListNode, val: int) -> ListNode:
if not head: return head
head.next = self.removeElements(head.next, val)
return head.next if head.val == val else head
参考网上的不是很简便
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class LinkList:
def __init__(self):
self.head=None
def initList(self, data):
# 创建头结点
self.head = ListNode(data[0])
r=self.head
p = self.head
# 逐个为 data 内的数据创建结点, 建立链表
for i in data[1:]:
node = ListNode(i)
p.next = node
p = p.next
return r
def printlist(self,head):
if head == None: return
node = head
while node != None:
print(node.val,end=' ')
node = node.next
def removeElements(head: ListNode, val):
pre = ListNode(0)
pre.next = head
a = pre
while head is not None:
if (head.val == val):
a.next = head.next
else:
a = a.next
head = head.next
return pre.next
l=LinkList()
a=[7,7,7,1]
head=l.initList(a)
l.printlist(head)
val=7
l.printlist(removeElements(head, val))
206 反转一个链表
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
pre = ListNode(0)
pre.next = head
while (head and head.next):
a = pre.next
hr = head.next
head.next = hr.next
pre.next = hr
hr.next = a
return pre.next

class Solution:
def reverseList(self, head: ListNode) -> ListNode:
# 申请两个节点,pre和 cur,pre指向None
pre = None
#pre.next = None
cur = head
# 遍历链表,while循环里面的内容其实可以写成一行
# 这里只做演示,就不搞那么骚气的写法了
while cur:
# 记录当前节点的下一个节点
tmp = cur.next
# 然后将当前节点指向pre
cur.next = pre
# pre和cur节点都前进一位
pre = cur
cur = tmp
return pre
递归:图解参考https://leetcode-cn.com/problems/reverse-linked-list/solution/dong-hua-yan-shi-206-fan-zhuan-lian-biao-by-user74/
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
# 递归终止条件是当前为空,或者下一个节点为空
if(head==None or head.next==None):
return head
# 这里的cur就是最后一个节点
cur = self.reverseList(head.next)
# 这里请配合动画演示理解
# 如果链表是 1->2->3->4->5,那么此时的cur就是5
# 而head是4,head的下一个是5,下下一个是空
# 所以head.next.next 就是5->4
head.next.next = head
# 防止链表循环,需要将head.next设置为空
head.next = None
# 每层递归函数都返回cur,也就是最后一个节点
return cur
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)