写在前面
本文主要介绍在实际开发过程中使用POI工具类去解析Excel格式文件遇到的问题引发的思考、学习以及解决方案,仅供参考,有考虑不周的地方还请指正。
问题描述
博主在做excel解析的时候,遇到了一个奇怪的现象——.xlsx拓展名的文件使用POI工具类的XSSFWorkbook进行程序初始化时候报格式错误,而使用HSSFWorkbook时候运行正常。
而当博主在新建一个.xlsx格式文件并将原文件中的数据复制到新的workbook中,再去使用XSSFWorkbook解析便可以正常执行。是什么原因导致在视觉上一致的文件,在使用POI解析时候有那么大的差别呢?
思考
POI很多网上给出的使用方法中说明XSSFWorkbook与HSSFWorkbook使用差别:
XSSF用于解析Excel2007版本开始,扩展名为.xlsx的excel文件。
HSSF用于解析Excel97-2003版本,扩展名为.xls的excel文件。
思考一下,若其只是按照拓展名来判定excel文件的格式,会出现这种情况吗?
很明显并不会,情况发生了,便只有一种解释——看着是.xlsx格式的文件本质上是一个.xls格式文件。
问题找到了,就是拓展名与POI解析出来的文件格式不一致,下一步便是去了解POI如何判断Excel文件的格式。
POI对Excel文件的判定标准
博主去官网查看了XSSFWorkbook的源码,在其构造函数中可以看到调用了
 源码路径:poi/XSSFWorkbook.java at trunk · apache/poi · GitHub
源码路径:poi/XSSFWorkbook.java at trunk · apache/poi · GitHub
继续追溯PackageHelper的open(InputStream stream, boolean closeStream)方法
源码路径:poi/PackageHelper.java at b52143528ac2f7eab4bd63bc64f4f957d7bb2f31 · apache/poi · GitHub
继续追溯OPCPackage的open(InputStream in)方法

源码路径:poi/OPCPackage.java at b52143528ac2f7eab4bd63bc64f4f957d7bb2f31 · apache/poi · GitHub
继续查看并找到对应的ZipPackage构造方法

源码路径:poi/ZipPackage.java at b52143528ac2f7eab4bd63bc64f4f957d7bb2f31 · apache/poi · GitHub
查看ZipHelper的openZipStream(InputStream stream)方法,可以看到想看的值主要跟两个哈部署有关,一个是FileMagic的prepareToCheckMagic方法,一个是本类的verifyZipHeader方法
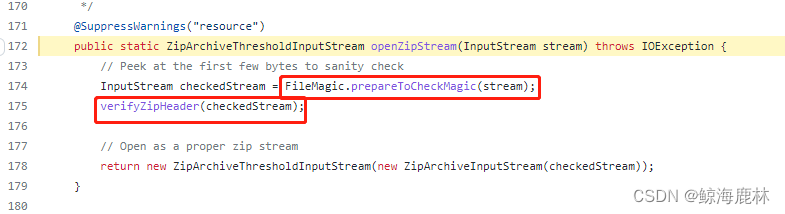
源码路径:poi/ZipHelper.java at b52143528ac2f7eab4bd63bc64f4f957d7bb2f31 · apache/poi · GitHub
我们先查看FileMagic的prepareToCheckMagic方法
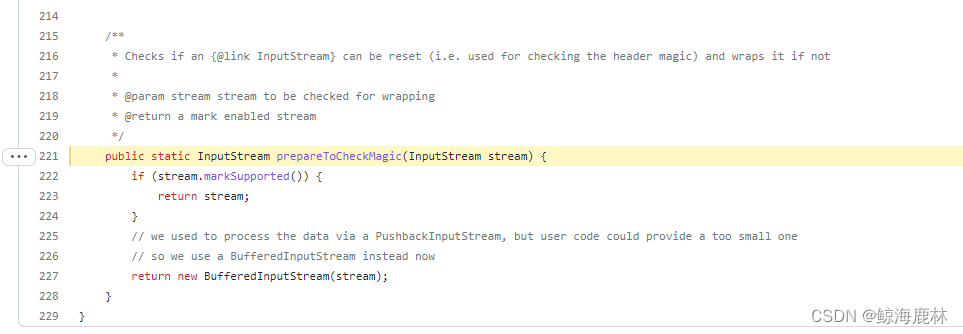 这边可以看到仅仅是一个准备的方法,并没有判断
这边可以看到仅仅是一个准备的方法,并没有判断
回到ZipHelper类,查看verifyZipHeader方法,在verifyZipHeader方法中对FileMagic.valueOf(is);的返回值进行了半段,从抛出的异常中可以看出若是OLE2便会抛出OLE2NotOfficeXmlFileException,说明格式不正确,应该使用HSSF解析,XSSF对应解析格式应该为OOXML,而且对于返回为XML则会报版本过低的异常(2003版本)。
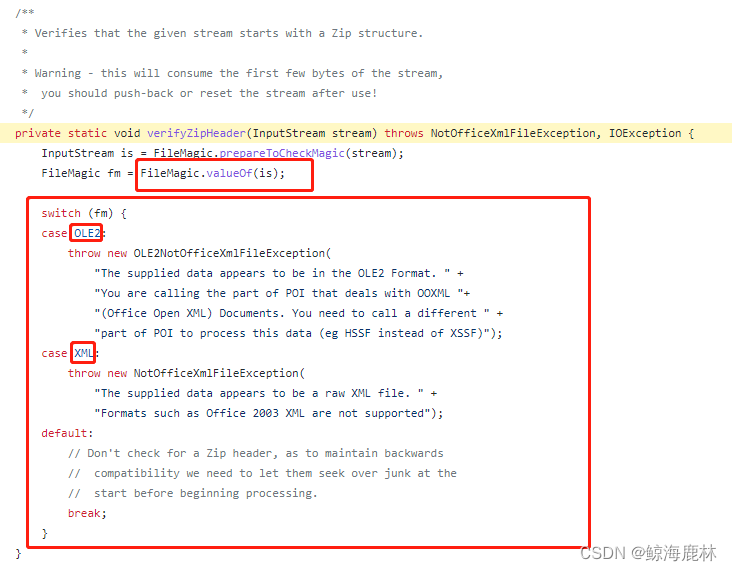
下面便是看一下FileMagic类的valueOf方法返回值依赖于什么数据的。


源码路径:poi/FileMagic.java at b52143528ac2f7eab4bd63bc64f4f957d7bb2f31 · apache/poi · GitHub
可以看到是获取字节流的第一个字节去判断,而非通过后缀名的格式取判断。
解决方案
问题找到了,如何取解决呢?博主是使用POI自带的判断字节流头部判断方法取处理,声明一个私有全局变量Type去标记当前文件的格式,以便后续的使用,后续的逻辑就很简单了,每个功能写两遍同名不同参的方法就行(XSSF与HSSF)。
public class TabsExcel {
static final Logger logger = Logger.getLogger(TabsExcel.class);
private Workbook workbook = null;
private String Type = "";
public TabsExcel() {
InputStream inp;
try {
inp = new FileInputStream(
System.getProperty("user.dir") + File.separator + "input" + File.separator + "文件名.xlsx");
BufferedInputStream bis = new BufferedInputStream(inp);
if (POIFSFileSystem.hasPOIFSHeader(bis)) {
workbook = new HSSFWorkbook(bis);
Type = "XLS";
} else if (POIXMLDocument.hasOOXMLHeader(bis)) {
workbook = new XSSFWorkbook(OPCPackage.open(bis));
Type = "XLSX";
}
} catch (FileNotFoundException e) {
logger.info("there something wrong,please check the log");
logger.error("Excel not found : No Excel to be parsed was found, please check the Input folder!");
logger.error(e.getMessage(), e);
System.exit(0);
} catch (IOException e) {
logger.info("there is something wrong, please check the log");
logger.error(e.getMessage(), e);
} catch (InvalidFormatException e) {
logger.info("there something wrong,please check the log");
logger.error(e.getMessage(), e);
}
}
}
代码中使用了log4j作为log的输出,需要的小伙伴可以自行下载配置文件,不需要的只要将log对应的代码删除就可以。