点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者:Greene | 来源:知乎(已获作者授权)
https://zhuanlan.zhihu.com/p/361105702
最近 Transformer 在计算机视觉遍地开花,从纯 Transformer 到 Transformer 和 CNN 的显式隐式杂交,各个任务仿佛嗷嗷待哺的婴儿,等着 Transformer 奶一口,这自然让人好奇 Transformer 的稳健性(Robustness)如何。
然而,Transformer 训练起来算力要求大,对抗训练加 Transformer 训练起来算力要求就是大上加大,好在我们不用亲自花费精力去实验,或者实验到一半的你也可以先休息一下,因为在 arXiv 上已经出现了研究 Transformer 的稳健性的论文。
第一篇映入眼帘的便是 2021年3月26日 公开的 Transformer 的老家谷歌做的这篇:
Srinadh Bhojanapalli, Ayan Chakrabarti, Daniel Glasner, Daliang Li, Thomas Unterthiner, Andreas Veit. Understanding Robustness of Transformers for Image Classification. arXiv:2103.14586

首先,Transformer 也存在对抗样本(Adversarial Example),这依然是一个问题,不过,针对 Transformer 的对抗扰动和针对 CNN 的对抗扰动看起来确实不太一样:

说明 Transformer 和 CNN 摔跤的地方不太一样。Transformer 的对抗扰动有明显的块(Patch)间差异,看起来似乎是每一块单独生成的对抗样本拼接而成的。他们使用 PGD 和 FGSM 测得的稳健性如下:

原文中对威胁模型(Threat Model)的描述是 one gray level,应该对应  。可以看到,Transformer 相对 CNN 并没有显著地更加稳健(Robust),在 FGSM 下的稳健性和应对输入变换(旋转、平移)的稳健性都不如 CNN;在 PGD 攻击下的稳健性比 CNN 要好一些,个人猜测有可能是因为 Transformer 让 PGD 更难优化。
。可以看到,Transformer 相对 CNN 并没有显著地更加稳健(Robust),在 FGSM 下的稳健性和应对输入变换(旋转、平移)的稳健性都不如 CNN;在 PGD 攻击下的稳健性比 CNN 要好一些,个人猜测有可能是因为 Transformer 让 PGD 更难优化。
老实说,这个结果让人有点失望,本来以为 Transformer 有从根本上杜绝对抗攻击的可能,但这些结果表明,并没有 o(╥﹏╥)o
不过令人欣慰的是,对抗样本在 Transformer 和 CNN 之间的迁移性不好:

这看起来似乎佐证了 Transformer 和 CNN 确实跌倒在不同的地方[1]。这篇文章处处透露着谷歌的豪气,只能说,不愧是谷歌。
就在这篇文章出现的三天后,arXiv上便再次出现了一篇研究 Transformer 的稳健性的论文:
Rulin Shao, Zhouxing Shi, Jinfeng Yi, Pin-Yu Chen, Cho-Jui Hsieh. On the Adversarial Robustness of Visual Transformers. arXiv:2103.15670

这篇论文最吸引人的地方是开篇的第一幅图:

这个 Transformer 看起来非常稳健啊,难道谷歌这次翻车了?按照这张图,Transformer 的稳健性似乎直接达到了对抗训练之后的CNN基准[2],而且他的结论是越加 CNN,就越不稳健......
然而看到后面却发现,好像结论跟谷歌没差,他们给出的PGD 攻击的结果如下:

在同样的威胁模型下(  ),ViT-B/16 的稳健精确度为 11.05% ~ 4.54%,与谷歌那篇论文的结论基本一致。图 1 目测绘制的是威胁模型为
),ViT-B/16 的稳健精确度为 11.05% ~ 4.54%,与谷歌那篇论文的结论基本一致。图 1 目测绘制的是威胁模型为  的结果,这个威胁模型比一个灰度阶梯(1/255)还小,实际意义有限[3]。
的结果,这个威胁模型比一个灰度阶梯(1/255)还小,实际意义有限[3]。
他们做了更加完善的迁移攻击的研究,结果如下:

颜色更深表示迁移性更强,对角线是自己跟自己的迁移攻击成功率,可以看到,结论与谷歌那篇中一致,对抗样本在 Transformer 与 CNN 之间的迁移性较低。
难能可贵的是,最耗时间的对抗训练他们也帮我们做了,这里使用的威胁模型是常见的  :
:
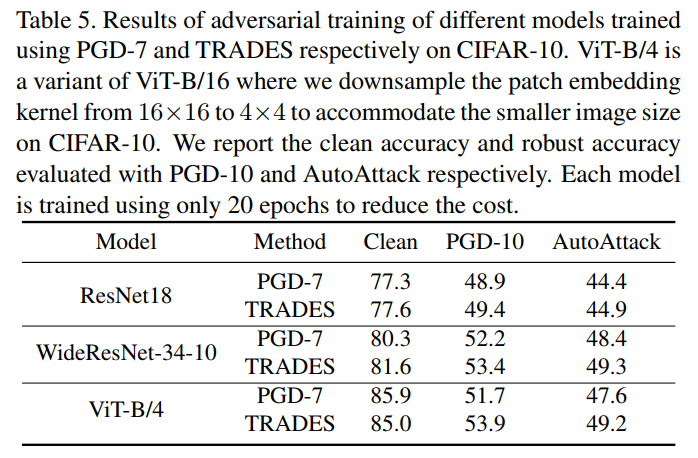
需要注意的是,每个模型只训练了 20 个周期(Epoch),一般的对抗训练会进行100个周期(Epoch)以上[4]。根据这个结果,Transformer 在对抗训练后的效果似乎比 CNN 要好,两个精确度都要高一些。
对比 ResNet-18 和 ViT-B/4 使用 TRADES 对抗训练得到的结果,ViT-B/4 的 标准精确度(Clean)要高 7.4%,稳健精确度(AutoAttack)要高 4.3%;鉴于只训练了20个周期,这个更好的效果有可能是因为 Transformer 在对抗训练的前期比 CNN 收敛得更快。
Transformer 是比 CNN 更稳健呢?还是稳健性跟 CNN 差不多呢?两篇论文,诸君自取。不过可以确定的是,Transformer 跟 CNN 跌倒的方式不同,他们确实学习到了很不一样的特征,而不一样的特征能得到相似的效果,不难理解为何关于 Transformer 的论文这么多了。
PS:Transformer 有没有合适的翻译额,中英混杂看起来很累,翻译成变压器或者变形金刚似乎不太好。
参考
^不过这里测试迁移性使用的是 PGD 攻击,之前已经有研究表明,就迁移性而言,使用 FGSM 这种单次攻击得到的对抗样本要更好一些
^Robust Bench https://robustbench.github.io/
^因为保存成图片这个级别的扰动基本就没有用了
^Tianyu Pang, Xiao Yang, Yinpeng Dong, Hang Su, Jun Zhu. Bag of Tricks for Adversarial Training. arXiv preprint 2020. arXiv:2010.00467 https://arxiv.org/abs/2010.00467
上述两篇论文PDF下载
后台回复:Tranformer鲁棒性,即可下载论文PDF
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看