
作者:谢凌曦
编辑:桃子
报道:新智元
计算机视觉识别领域的发展如何?华为天才少年谢凌曦分享了万字长文,阐述了个人对其的看法。
最近,我参加了几个高强度的学术活动,包括CCF计算机视觉专委会的闭门研讨会和VALSE线下大会。经过与其他学者的交流,我产生了许多想法,千头万绪,便希望把它们整理下来,供自己和同行们参考。当然,受限于个人的水平和研究范围,文章中一定会存在许多不准确甚至错误的地方,当然也不可能覆盖所有重要的研究方向。我期待与有兴趣的学者们进行交流,以充实这些观点,更好地探讨未来发展方向。
在这篇文章中,我将会着重分析计算机视觉领域,特别是视觉感知(即识别)方向所面临的困难和潜在的研究方向。
相较于针对具体算法的细节改进,我更希望探讨当前算法(尤其是基于深度学习的预训练+微调范式)的局限性和瓶颈,并且由此得出初步的发展性结论,包括哪些问题是重要的、哪些问题是不重要的、哪些方向值得推进、哪些方向的性价比较低等。
在开始之前,我先画出如下思维导图。为了寻找合适的切入点,我将从计算机视觉和自然语言处理(人工智能中两个最受关注的研究方向)的区别开始谈起,引出图像信号的三个根本性质:信息稀疏性、域间差异性、无限粒度性,并将它们与几个重要的研究方向相对应。这样,我们就能更好地了解每个研究方向所处的状态:它已经解决了哪些问题、还有哪些重要的问题没有解决,然后针对性地分析今后的发展趋势。
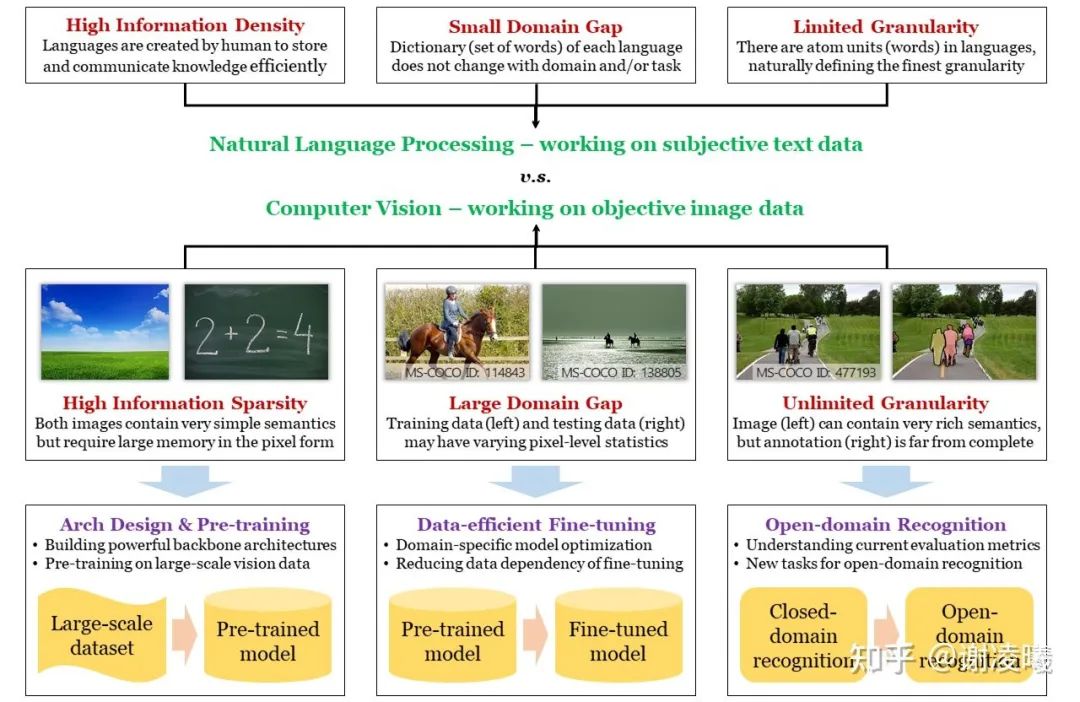
导图:CV和NLP的差异、CV三大挑战及应对方法
CV的三大基本困难和对应的研究方向
一直以来,NLP都走在CV的前面。不论是深度神经网络超越手工方法,还是预训练大模型开始出现大一统的趋势,这些事情都先发生在NLP领域,并在不久之后被搬运到了CV领域。这里的本质原因是NLP的起点更高:自然语言的基础单元是单词,而图像的基础单元是像素;前者具有天然的语义信息,而后者未必能够表达语义。
从根本上说,自然语言是人类创造出来,用于存储知识和交流信息的载体,所以必然具有高效和信息密度高的特性;而图像则是人类通过各种传感器捕捉的光学信号,它能够客观地反映真实情况,但相应地就不具有强语义,且信息密度可能很低。
从另一个角度看,图像空间比文本空间要大得多,空间的结构也要复杂得多。这就意味着,如果希望在空间中采样大量样本,并且用这些数据来表征整个空间的分布,采样的图像数据就要比采样的文本数据大许多个数量级。顺带一提,这也是为什么自然语言预训练模型比视觉预训练模型用得更好的本质原因——我们在后面还会提到这一点。
根据上述分析,我们已经通过CV和NLP的差别,引出了CV的第一个基本困难,即语义稀疏性。而另外两个困难,域间差异性和无限粒度性,也多少与上述本质差别相关。正是由于图像采样时没有考虑到语义,因而在采样不同域(即不同分布,如白天和黑夜、晴天和雨天等场景)时,采样结果(即图像像素)与域特性强相关,导致了域间差异性。同时,由于图像的基本语义单元很难定义(而文本很容易定义),且图像所表达的信息丰富多样,使得人类能够从图像中获取近乎无限精细的语义信息,远远超出当前CV领域任何一种评价指标所定义的能力,这就是无限粒度性。关于无限粒度性,我曾经写过一篇文章,专门讨论这个问题。
https://zhuanlan.zhihu.com/p/376145664
以上述三大基本困难为牵引,我们将业界近年来的研究方向总结如下:
这里需要做一个补充说明。由于数据空间大小和结构复杂度的差异,至少到目前为止,CV领域还不能通过预训练模型直接解决域间差异的问题,但是NLP领域已经接近了这一点。因此,我们看到了NLP学者们利用prompt-based方法统一了几十上百种下游任务,但是同样的事情在CV领域并没有发生。另外,在NLP中提出来的scaling law,其本质在于使用更大的模型来过拟合预训练数据集。也就是说,对于NLP来说,过拟合已经不再是一个问题,因为预训练数据集配合小型prompt已经足以表征整个语义空间的分布。但是,CV领域还没有做到这一点,因此还需要考虑域迁移,而域迁移的核心在于避免过拟合。也就是说,在接下来2-3年,CV和NLP的研究重心会有很大的差异,因而将任何一个方向的思维模式生搬硬套在另一个方向上,都是很危险的。
以下简要分析各个研究方向
方向1a:神经网络架构设计
2012年的AlexNet,奠定了深度神经网络在CV领域的基础。随后10年(至今),神经网络架构设计,经历了从手工设计到自动设计,再回到手工设计(引入更复杂的计算模块)的过程:
对于这一方向的未来,我的判断如下:
如果视觉识别任务没有明显改变,那么不论是自动设计,或者加入更复杂的计算模块,都无法将CV推向新的高度。视觉识别任务的可能改变,大致可以分为输入和输出两个部分。输入部分的可能改变如event camera,它可能会改变规则化处理静态或者时序视觉信号的现状,催生特定的神经网络结构;输出部分的可能改变,则是某种统一各种识别任务的框架(方向3会谈到),它有可能让视觉识别从独立任务走向大一统,从而催生出一种更适合视觉prompt的网络架构。
如果一定要在卷积和transformer之间做取舍,那么transformer的潜力更大,主要因为它能够统一不同的数据模态,尤其是文本和图像这两个最常见也最重要的模态。
方向1b:视觉预训练
作为如今CV领域炙手可热的方向,预训练方法被寄予厚望。在深度学习时代,视觉预训练可以分为有监督、无监督、跨模态三类,大致叙述如下:
基于上述回顾,我做出如下判断:
方向2:模型微调和终身学习
作为一个基础问题,模型微调已经发展出了大量的不同的setting。如果要把不同的setting统一起来,可以认为它们无非考虑三个数据集,即预训练数据集 Dpre (不可见)、目标训练集 Dtrain 、目标测试集 Dtest (不可见且不可预测)。根据对三者之间关系的假设不同,比较流行的setting可以概括如下:
迁移学习:假设 Dpre 或者 Dtrain 和 Dtest 的数据分布大不相同;
弱监督学习:假设 Dtrain 只提供了不完整的标注信息;
半监督学习:假设 Dtrain 只有部分数据被标注;
带噪学习:假设 Dtrain 的部分数据标注可能有误;
主动学习:假设 Dtrain 可以通过交互形式标注(挑选其中最难的样本)以提升标注效率;
持续学习:假设不断有新的 Dtrain 出现,从而学习过程中可能会遗忘从 Dpre 学习的内容;
……
从一般意义上说,很难找到统一的框架来分析模型微调方法的发展和流派。从工程和实用角度看,模型微调的关键在于对域间差异大小的事先判断。如果认为 Dpre 和 Dtrain 的差异可能很大,就要减少从预训练网络中迁移到目标网络中权重的比例,或者增加一个专门的head来适应这种差异;如果认为 Dtrain 和 Dtest 的差异可能很大,就要在微调过程中加入更强的正则化以防止过拟合,或者在测试过程中引入某种在线统计量以尽量抵消差异。至于上述各种setting,则分别有大量研究工作,针对性很强,此处不再赘述。
关于这个方向,我认为有两个重要问题:
方向3:无限细粒度视觉识别任务
关于无限细粒度视觉识别(以及类似的概念),目前还没有很多相关的研究。所以,我以自己的思路来叙述这个问题。我在今年VALSE报告上,对已有方法和我们的proposal做了详细解读。以下我给出文字叙述,更详细的解读请参考我的专题文章或者我在VALSE上做的报告:
https://zhuanlan.zhihu.com/p/546510418
https://zhuanlan.zhihu.com/p/555377882
首先,我要阐述无限细粒度视觉识别的含义。简单地说,图像中包含的语义信息非常丰富,但不具有明确的基本语义单元。只要人类愿意,就可以从一张图像中识别出越来越细粒度的语义信息(如下图所示);而这些信息,很难通过有限而规范的标注(即使花费足够多的标注成本),形成语义上完整的数据集,供算法学习。

即使如ADE20K这样的精细标注数据集,也缺少了大量人类能够识别的语义内容
我们认为,无限细粒度视觉识别是比开放域视觉识别更难,也更加本质的目标。我们调研了已有识别方法,将其分为两类,即基于分类的方法和语言驱动的方法,并论述它们无法实现无限细粒度的理由。
上述调研告诉我们,当前的视觉识别方法并不能达到无限细粒度的目标,而且在走向无限细粒度的路上还会遭遇难以逾越的困难。因此,我们我们想分析人是如何解决这些困难的。首先,人类在大多数情况下并不需要显式地做分类任务:回到上述例子,一个人到商场里买东西,不管商场把“按摩椅”放在“家具”区还是“家电”区,人类都可以通过简单的指引,快速找到“按摩椅”所在的区域。其次,人类并不仅限于用语言指代图像中的物体,可以使用更灵活的方式(如用手指向物体)完成指代,进而做更细致的分析。
结合这些分析,要达到无限细粒度的目标,必须满足以下三个条件。
开放性:开放域识别,是无限细粒度识别的一个子目标。目前看,引入语言是实现开放性的最佳方案之一。
特异性:引入语言时,不应被语言束缚,而应当设计视觉友好的指代方案(即识别任务)。
可变粒度性:并非总是要求识别到最细粒度,而是可以根据需求,灵活地改变识别的粒度。
在这三个条件的牵引下,我们设计出了按需视觉识别任务。与传统意义上的统一视觉识别不同,按需视觉识别以request为单位进行标注、学习和评测。当前,系统支持两类request,分别实现了从instance到semantic的分割、以及从semantic到instance的分割,因而两者结合起来,就能够实现任意精细程度的图像分割。按需视觉识别的另一个好处在于,在完成任意数量的request之后停止下来,都不会影响标注的精确性(即使大量信息没有被标注出来),这对于开放域的可扩展性(如新增语义类别)有很大的好处。具体细节,可以参看按需视觉识别的文章(链接见上文)。

统一视觉识别和按需视觉识别的对比
在完成这篇文章之后,我还在不断思考,按需视觉识别对于其他方向的影响是什么。这里提供两个观点:
在上述方向之外
我将CV领域的问题分为三大类:识别、生成、交互,识别只是其中最简单的问题。关于这三个子领域,简要的分析如下:
生成是比识别更高级的能力。人类能够轻易地识别出各种常见物体,但是很少有人能够画出逼真的物体。从统计学习的语言上说,这是因为生成式模型需要对联合分布 p(x,y) 进行建模,而判别式模型只需要对条件分布 p(y|x) 进行建模:前者能够推导出后者,而后者不能推导出前者。从业界的发展看,虽然图像生成质量不断提升,但是生成内容的稳定性(不生成明显非真实的内容)和可控性仍有待提升。同时,生成内容对于识别算法的辅助还相对较弱,人们还难以完全利用虚拟数据、合成数据,达到和真实数据训练相媲美的效果。对于这两个问题,我们的观点都是,需要设计更好、更本质的评价指标,以替代现有的指标(生成任务上替代FID、IS等,而生成识别任务需要结合起来,定义统一的评价指标)。
总之,在不同子领域,单纯依靠统计学习(特别是深度学习)的强拟合能力的尝试,都已经走到了极限。未来的发展,一定建立在对CV更本质的理解上,而在各种任务上建立更合理的评价指标,则是我们需要迈出的第一步。
结语
经过几次密集的学术交流,我能够明显地感受到业界的迷茫,至少对于视觉感知(识别)而言,有意思、有价值的研究问题越来越少,门槛也越来越高。这样发展下去,有可能在不久的将来,CV研究会走上NLP的道路,逐渐分化成两类:
一类使用巨量计算资源进行预训练,不断空虚地刷新SOTA;一类则不断设计出新颖却没有实际意义的setting以强行创新。这对于CV领域显然不是好事。为了避免这种事情,除了不断探索视觉的本质、创造出更有价值的评测指标,还需要业界增加宽容性,特别是对于非主流方向的宽容性,不要一边抱怨着研究同质化,一边对于没有达到SOTA的投稿痛下杀手。当前的瓶颈是所有人共同面对的挑战,如果AI的发展陷入停滞,没有人能够独善其身。
感谢看到最后。欢迎友善的讨论。
作者声明
所有内容均只代表作者本人观点,均有可能被推翻,二次转载务必连同声明一起转载。谢谢!
原文链接:
https://zhuanlan.zhihu.com/p/558646681
本文仅做学术分享,如有侵权,请联系删文。