darknet框架简介
https://blog.csdn.net/mao_hui_fei/article/details/113820303
AlexeyAB大佬的关于darknet的详细文档信息
https://github.com/AlexeyAB/darknet
参考文件
YOLOV3训练自己的数据集(VOC数据集格式)
https://blog.csdn.net/weixin_43818251/article/details/89548583
同学们,这个系列的文件不要直接就跟着我操作了,因为这个是踩坑的记录,不是教程,我只是将整个流程记录下来,让后面的同学操作的时候能够避开这些坑,希望你能将整个系列的操作流程看了一遍斟酌后进行操作
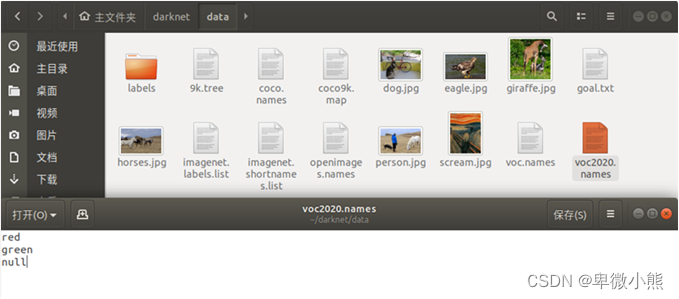
那么这里我是使用红绿灯的识别作为目标,标签为"red", “green”, “null”
并且使用VOC数据集
darknet和VOC
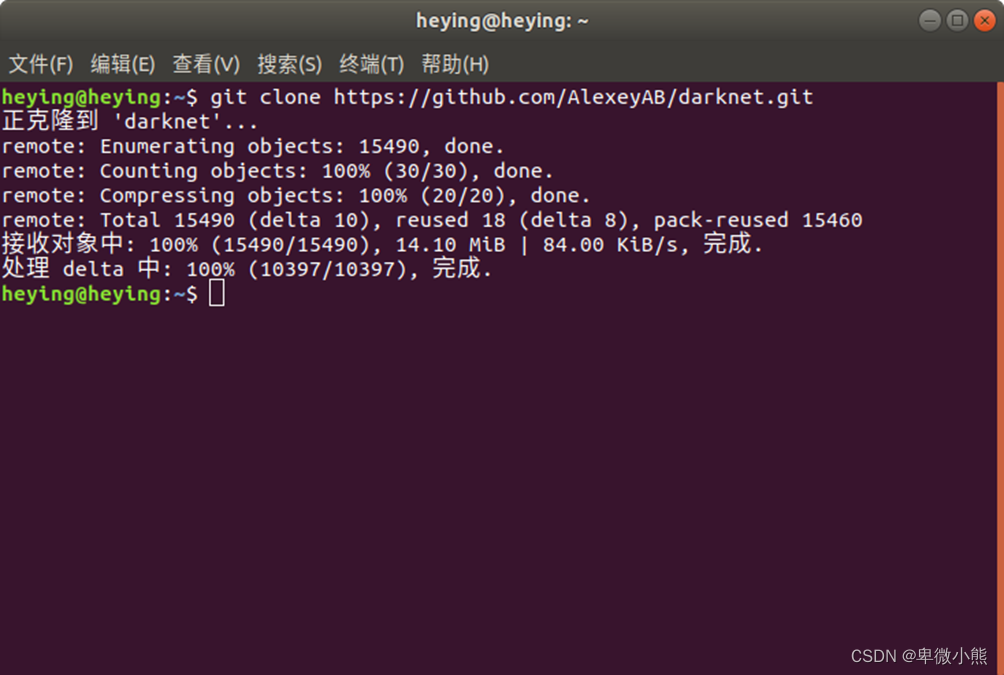
首先下载darknet
git clone https:
然后制作自己的VOC的数据集
当在LabelImg中标注完成图片后
然后需要对图片进行批量的重命名,格式是:000001.jpg 000002.jpg ……
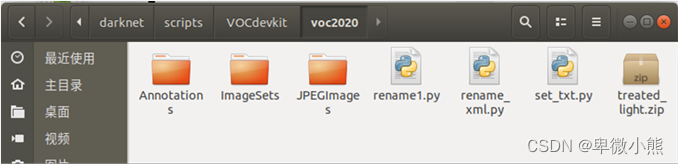
标注完成制作好标签后,在darknet/scripts文件夹内建立VOCdevkit
文件夹,VOCdevkit件夹内部文件形式如下
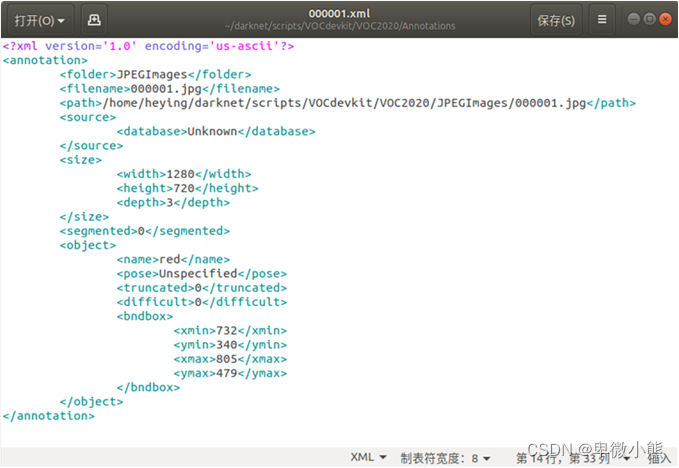
首先要注意标注生成的.xml文件中
的路径问题
当标注任务分给队伍所有人进行标注生成后,汇总的.xml文件中
的路径都是不一样的
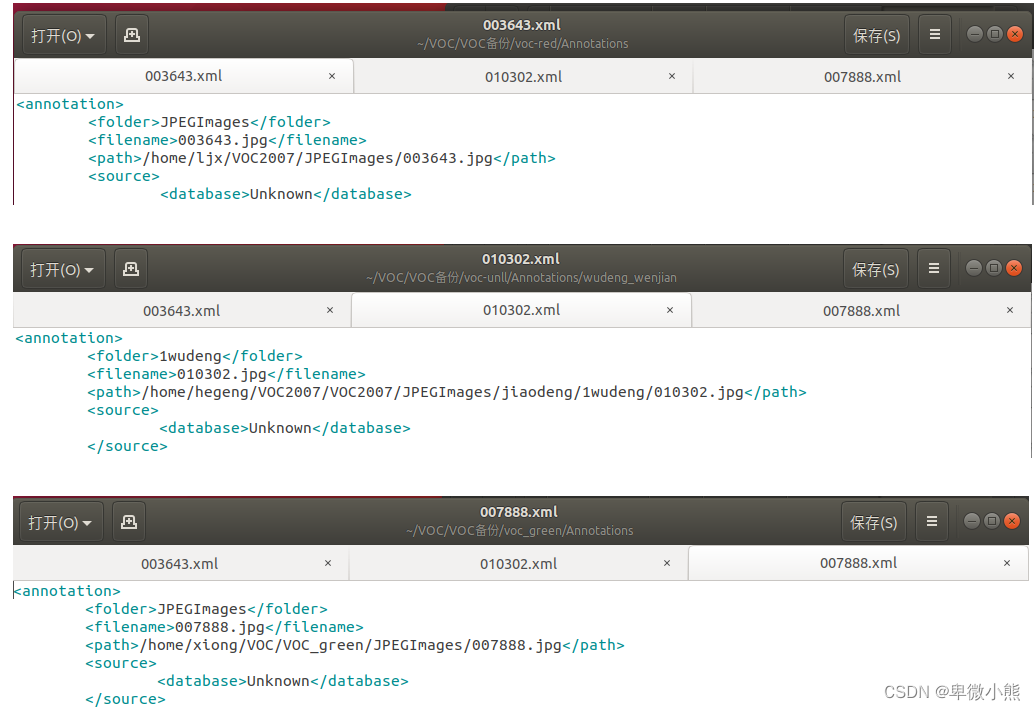
所以要对汇总的xml文件中的
路径都进行修改
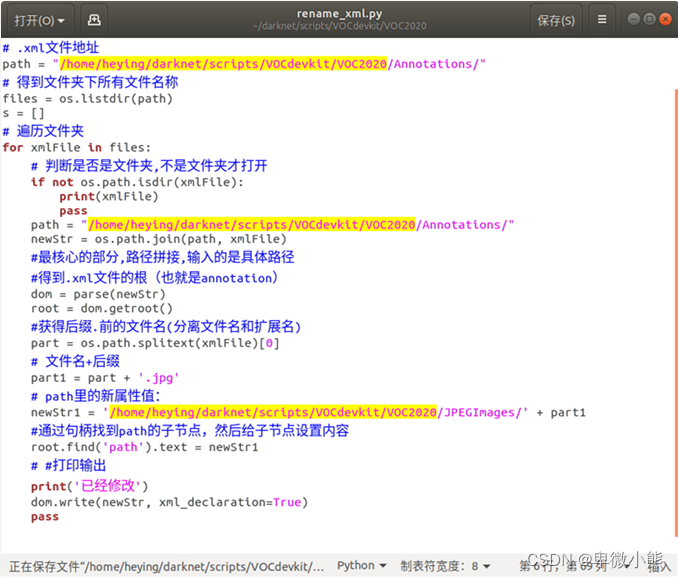
打开/home/heying/darknet/scripts/VOCdevkit/VOC2020/rename_xml.py文件
进行修改路径
import os
import os.path
from xml.etree.ElementTree import parse, Element
path = "/home/xiong/VOC/VOC_MAX/Annotations/"
files = os.listdir(path)
s = []
for xmlFile in files:
if not os.path.isdir(xmlFile):
print(xmlFile)
pass
path = "/home/xiong/VOC/VOC_MAX/Annotations/"
newStr = os.path.join(path, xmlFile)
dom = parse(newStr)
root = dom.getroot()
part = os.path.splitext(xmlFile)[0]
part1 = part + '.jpg'
newStr1 = '/home/xiong/VOC/VOC_MAX/JPEGImages/' + part1
root.find('path').text = newStr1
print('已经修改')
dom.write(newStr, xml_declaration=True)
pass
完成后使用python3运行
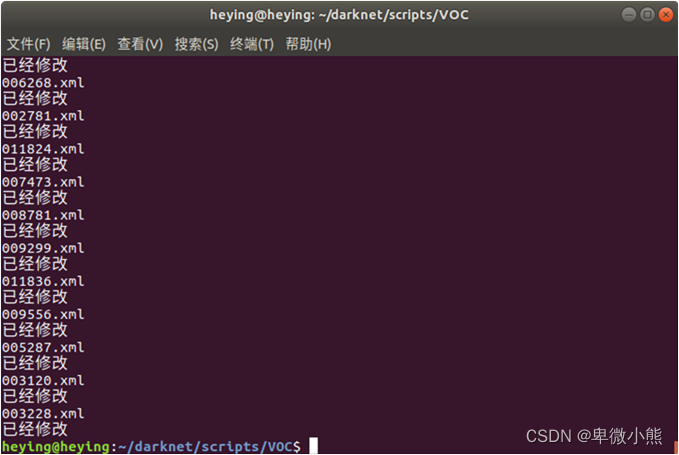
可以打开其中一个xml文件检查一下
然后在VOC数据集中新建一个Main文件
然后进行修改
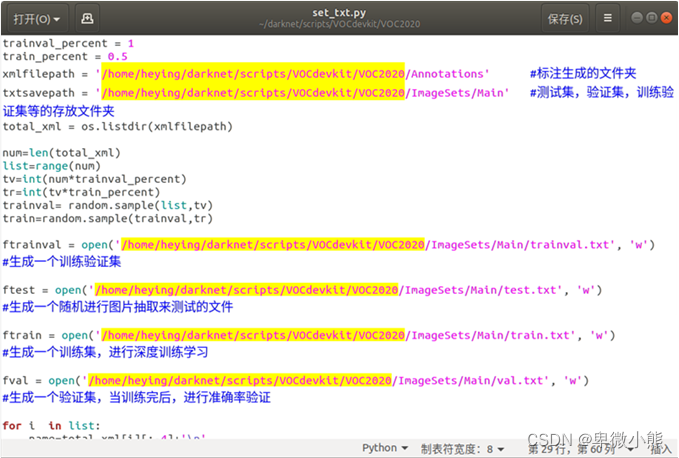
运行set_txt.py文件生成train.txt和test.txt
适用于训练所需要的各种验证集与数据集
(这一步可能是适用于jetson-inference的训练。可能使用yolov3不需要这一步)
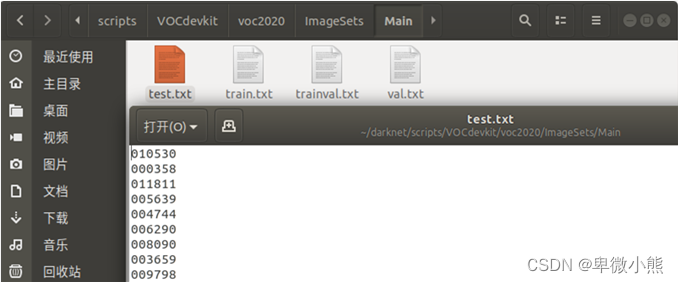
在darknet中git下来的代码中包含了voc_label.py的python文件,把它放到和 VOCdevkit 同级的目录下。修改相关配置
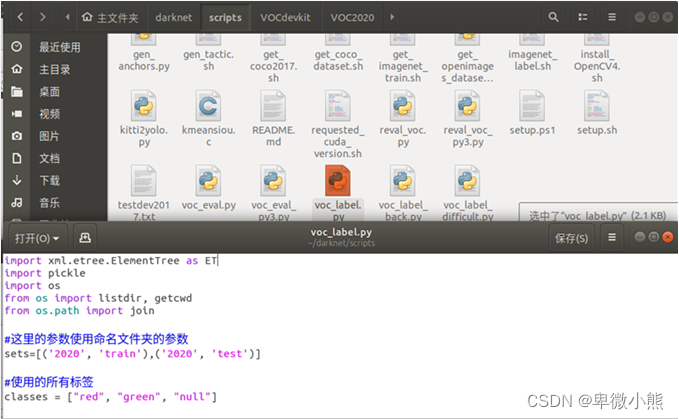
修改文件
sets=[('2020', 'train'),('2020', 'test')]
classes = ["red", "green", "null"]
在修改所使用的标签文件,要注意ID号的顺序
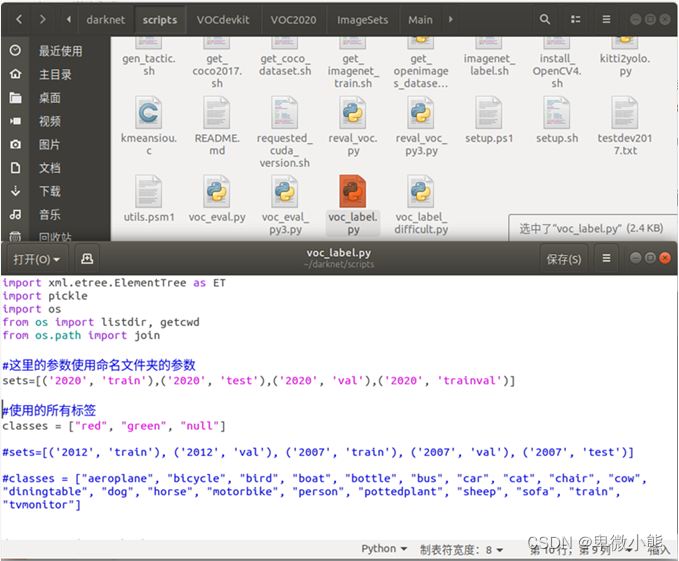
完成后运行
可以看到程序在路径中生成的文件与内容
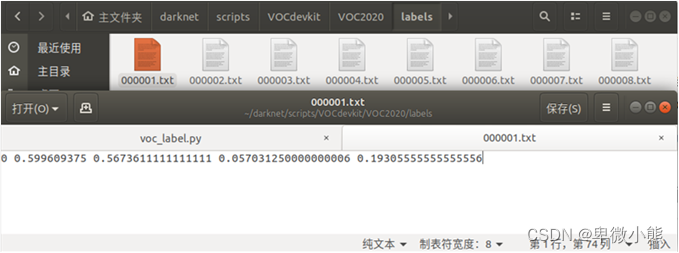
并且还会在VOCdevkit同级的目录下会生成2019_train.txt 和 2019_text.txt 两个文件,里面存有对应图片文件的绝对路径,训练时作为引用。
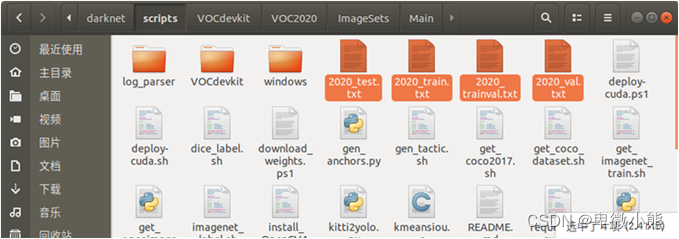
训练准备
在 darknet/data 目录下建立 myvoc.names 的文件(文件名无所谓,后缀得是.names),内容是类名
然后将标注的标签写入
修改 cfg/voc.data 文件,修改后如下所示:
classes= 3
train = /home/heying/darknet/scripts/2020_train.txt
valid = /home/heying/darknet/scripts/2020_test.txt
names = data/voc2020.names
backup = /home/heying/darknet/backup/
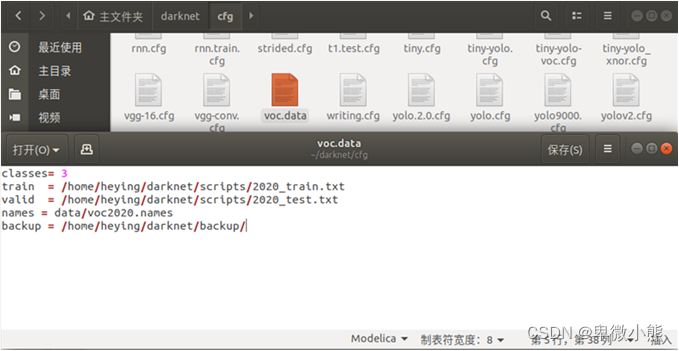
其中
【classes= 3】指标签的数量,本次流程为3个
【train = /home/heying/darknet/scripts/2020_train.txt】 刚生成的2020_train.txt的绝对路径
【valid = /home/heying/darknet/scripts/2020_test.txt】刚生成的2020_test.txt的绝对路径
【names = data/voc2020.names】刚设置的标签名称的文件
【backup = /home/pjreddie/backup/】训练完成的权重保存路径
完成后保存并退出
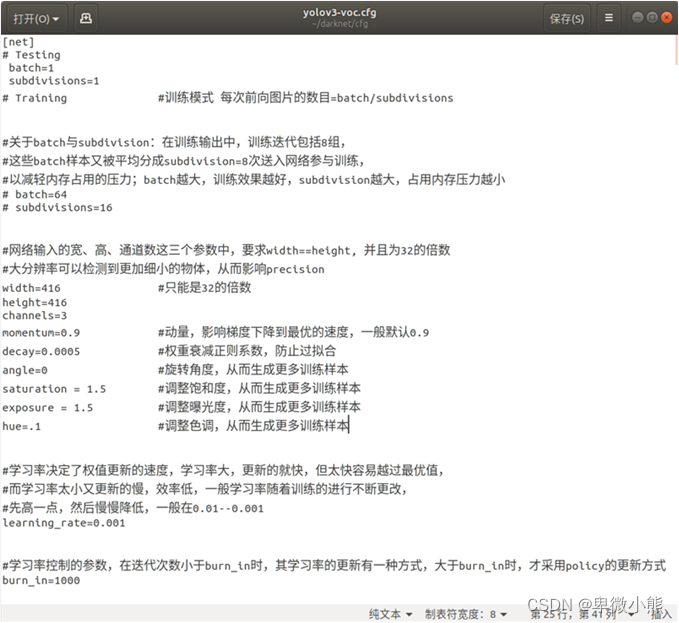
然后修改 cfg/yolov3-voc.cfg 文件
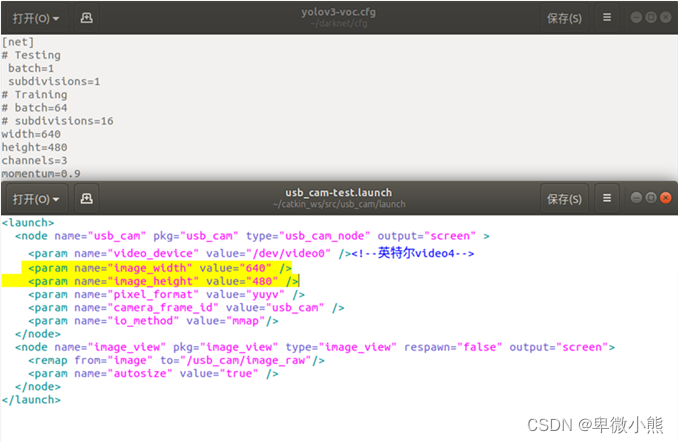
主要是 filters 和 classes 的调整,文件前面的Testing和Training模式根据自己进行的方式进行选择,width和height根据自己训练的图片进行调整,但必须为32的倍数。控制训练的迭代次数为1000次
这里我依照启动摄像头的usb_cam程序的长宽来设置分辨率
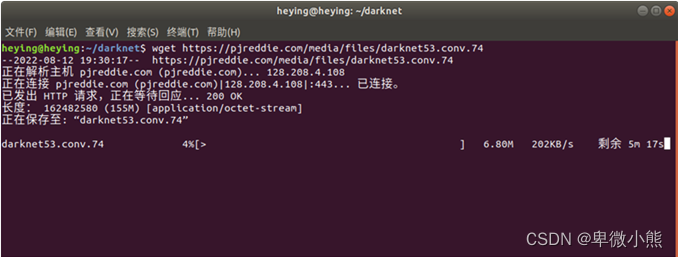
然后下载darknet-53的预训练权重文件
wget https:
开始进行训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpus 0,1 >> /home/heying/darknet/scripts/VOCdevkit/VOC2020/traffic_light.log
其中
这一行指令可以简化成
./darknet detector train [.data] [.cfg] [.weight]
【cfg/voc.data】→[.data] :指刚刚配置的.data文件路径
【 cfg/yolov3-voc.cfg】->[.cfg]:指刚刚配置的.cfg文件路径
【 darknet53.conv.74】->[.weight]:是预训练权重文件的路径,可以是.weight文件,也可以是.backup文件
【-gpus 0,1】是使用的GPU的个数,使用了两个
【 >> /home/heying/darknet/scripts/VOCdevkit/VOC2020/traffic_light.log 】这个只是将终端的标准输出记录下来,形成一个log日志文件,方便后续查看
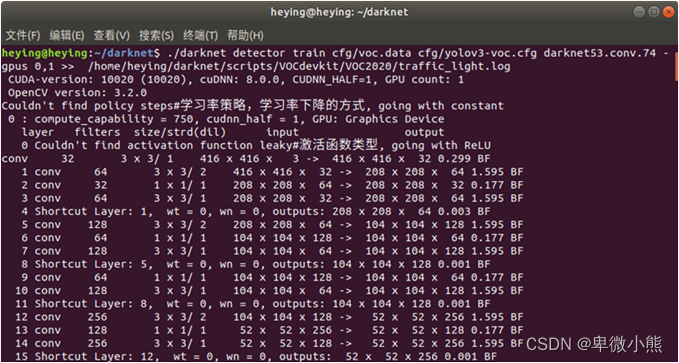
但是很不幸darknet训练卡住
就是程序一直停滞在这里
此次流程失败
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)