目录
1.读取excel文件
(1)语法
(2)实例
2.读取cvs文件
(1)语法
(2)实例
3.读取txt文件
(1)语法
(2)实例
4.写入文件
(1)语法
(2)实例
1.读取excel文件
(1)语法
import pandas as pd
data = pd.read_excel(io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True)
常用参数说明
io:读取的excel文件名,如r'./vote.excel'。
sheet_name: excel文件中的sheet表名。
header: 哪一行设置为列索引,默认是第一行,即header = 0。
names: 列索引名。
index_col: 使用哪一列作为行索引,默认从0开始。
usecols: 读取表格中哪几列,必须是位置索引。
skiprows: 跳过前几行读取文件,默认从0开始。
nrows: 读取多少行数据。
(2)实例
读取文件中的分类sheet的指定列的六行数据。
import pandas as pd
data = pd.read_excel(r'.\data\sep_word - 1.0.xlsx',sheet_name= '分类',header= 0,nrows=6,usecols=[0,1,3,5])
data
输出结果为
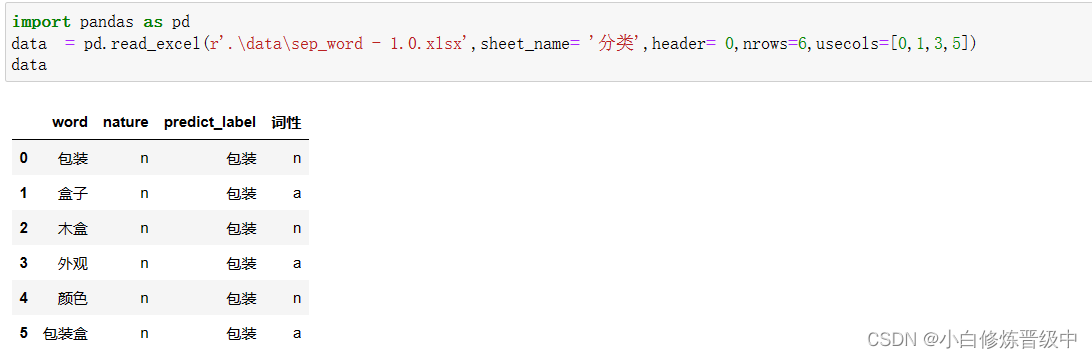
解释:usecols=[0,1,3,5]是指第1,2,4,6列。
2.读取cvs文件
(1)语法
import pandas as pd
data = pd.read_cvs(filepath_or_buffer: FilePathOrBuffer,
sep=",",
delimiter=None,
# Column and Index Locations and Names
header="infer",
names=None,
index_col=None,
usecols=None,
squeeze=False,
prefix=None,
mangle_dupe_cols=True,
# General Parsing Configuration
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skipinitialspace=False,
skiprows=None,
skipfooter=0,
nrows=None,
# NA and Missing Data Handling
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
skip_blank_lines=True,
# Datetime Handling
parse_dates=False,
infer_datetime_format=False,
keep_date_col=False,
date_parser=None,
dayfirst=False,
cache_dates=True,
# Iteration
iterator=False,
chunksize=None,
# Quoting, Compression, and File Format
compression="infer",
thousands=None,
decimal: str = ".",
lineterminator=None,
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
doublequote=True,
escapechar=None,
comment=None,
encoding=None,
dialect=None,
# Error Handling
error_bad_lines=True,
warn_bad_lines=True,
# Internal
delim_whitespace=False,
low_memory=_c_parser_defaults["low_memory"],
memory_map=False,
float_precision=None)
参数说明:
csv文件是以逗号为分隔符的文件,读取参数与excel基本类似,文件为gbk格式的csv,若不设置encoding参数,会报错。
encoding:默认为'utf-8',还有中文编码‘gbk’、‘gb18030’、‘gb2312’。
就我们关心的汉字而言,三种编码方式的表示范围是:
GB18030 > GBK > GB2312
即GBK是GB2312的超集,GB1803又是GBK的超集。
一般读取中文文本可以直接用encoding =GB18030
(2)实例
直接读取不设置编码方式,储存方式可能存在gbk格式,中文会乱码。
import pandas as pd
data = pd.read_csv(r'.\python\python数据分析\word.csv')
data
输出结果为:

一般用encoding= 'utf-8'可以解决很多编码乱码问题,但是还是报错。
显示:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc0 in position 37: invalid start byte

可能是因为中文储存的时候是gbk格式,utf-8还是识别不了一些编码,所以可以尝试用gbk,需要设置编码方式encoding='gbk'。
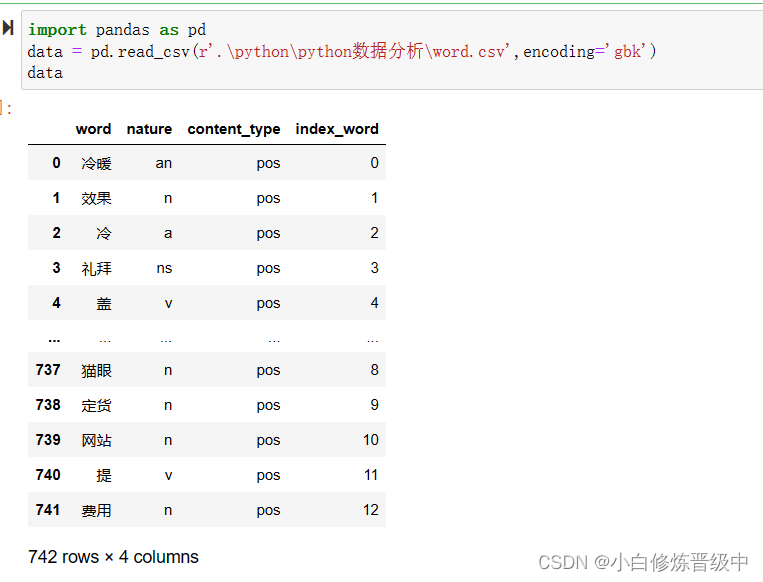
import pandas as pd
data = pd.read_csv(r'.\python\python数据分析\word.csv',encoding='gbk')
data
输出结果为:
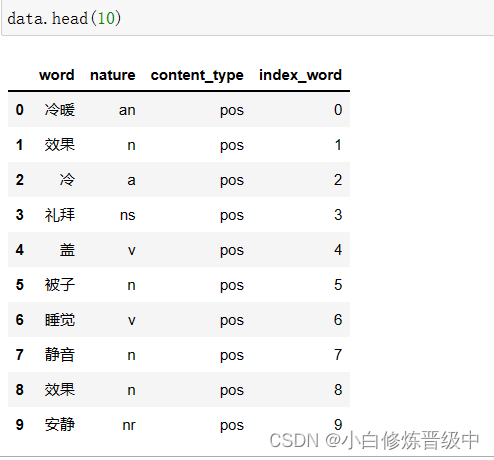
只想查看前10行数据用head函数。
data.head(10) #查看前十行数据
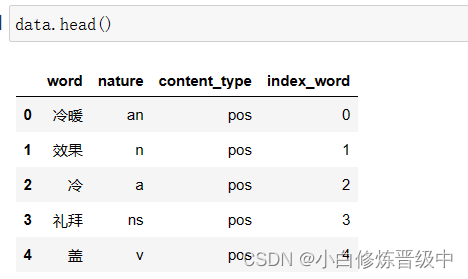
data.head() #默认显示前5行数据
3.读取txt文件
(1)语法
import pandas as pd
data = pd.read_table(filepath_or_buffer: FilePathOrBuffer,
sep="\t",
delimiter=None,
# Column and Index Locations and Names
header="infer",
names=None,
index_col=None,
usecols=None,
squeeze=False,
prefix=None,
mangle_dupe_cols=True,
# General Parsing Configuration
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skipinitialspace=False,
skiprows=None,
skipfooter=0,
nrows=None,
# NA and Missing Data Handling
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
skip_blank_lines=True,
# Datetime Handling
parse_dates=False,
infer_datetime_format=False,
keep_date_col=False,
date_parser=None,
dayfirst=False,
cache_dates=True,
# Iteration
iterator=False,
chunksize=None,
# Quoting, Compression, and File Format
compression="infer",
thousands=None,
decimal: str = ".",
lineterminator=None,
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
doublequote=True,
escapechar=None,
comment=None,
encoding=None,
dialect=None,
# Error Handling
error_bad_lines=True,
warn_bad_lines=True,
# Internal
delim_whitespace=False,
low_memory=_c_parser_defaults["low_memory"],
memory_map=False,
float_precision=None)
参数说明:
txt文件是以指制表符\t为分隔符的文件,参数与excel、csv基本类似,不同的地方在于必须要指定sep。
sep:默认为'\t'。
(2)实例
读取竞选文档。
data = pd.read_table(r'.\python\python数据分析\智能空调项目\python_study\vote.txt')
data
输出结果为:

4.写入文件
excel,csv,txt写入文件的方式基本类似,以pandas的to_xx()方式写入。
(1)语法
#写入excel文件
to_excel(
self,
excel_writer,
sheet_name="Sheet1",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
startrow=0,
startcol=0,
engine=None,
merge_cells=True,
encoding=None,
inf_rep="inf",
verbose=True,
freeze_panes=None
)
常用参数说明:
index: 是否保留行索引,默认是True保留,False表示不保留。
columns: 通过列索引指定所需列。
sheet_name: 表名,默认为‘sheet1’。
encoding:编码格式,utf-8或者gbk。
na_rep: 缺失值填充,可指定为0。
index_label: 行索引标签。
header: 默认为True,False没有列索引,如需更改列名,则header = ["列1","列2","列3"]
(2)实例
将txt文档写为xlsx文件。
import pandas as pd #导入pandas库
#读入txt文档
data = pd.read_table(r'.\python\python数据分析\智能空调项目\python_study\vote.txt',sep='\t')
#写入excel文档
data.to_excel(r'./vote.xlsx',sheet_name='vote',na_rep='')
参考文章:
python学习之路--pandas读写文件 - 知乎 (zhihu.com)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)