一、什么是IBM SPSS Statistics?
IBM SPSS Statistics 是一款强大的统计软件平台,它所提供的数据分析功能,可以帮助企业、个人对各类数据进行切实可行的洞察分析,从而获取有效信息。
二、为什么要进行SPSS数据分析?
不管是企业、科研团队,亦或是个人,在进行调查、统计后得出的结果都将会是大量的数据,要从海量数据中找到应有的结论就需要利用方法进行数据分析,而SPSS就是为用户提供了系统的数据统计和分析方法,帮助大家进行数据分析得出结论。
三、如何使用SPSS?
首先,我们来认识一下SPSS软件的主操作界面,分为两个视图,分别是“数据视图”和“变量视图”。
我们在“变量视图”中定义好自己所调研的数据的变量,包括变量名称、类型、小数点、标签;定义好变量之后,就可以在“数据视图”输入我们要进行分析的数据,然后即可生成数据分析结果。
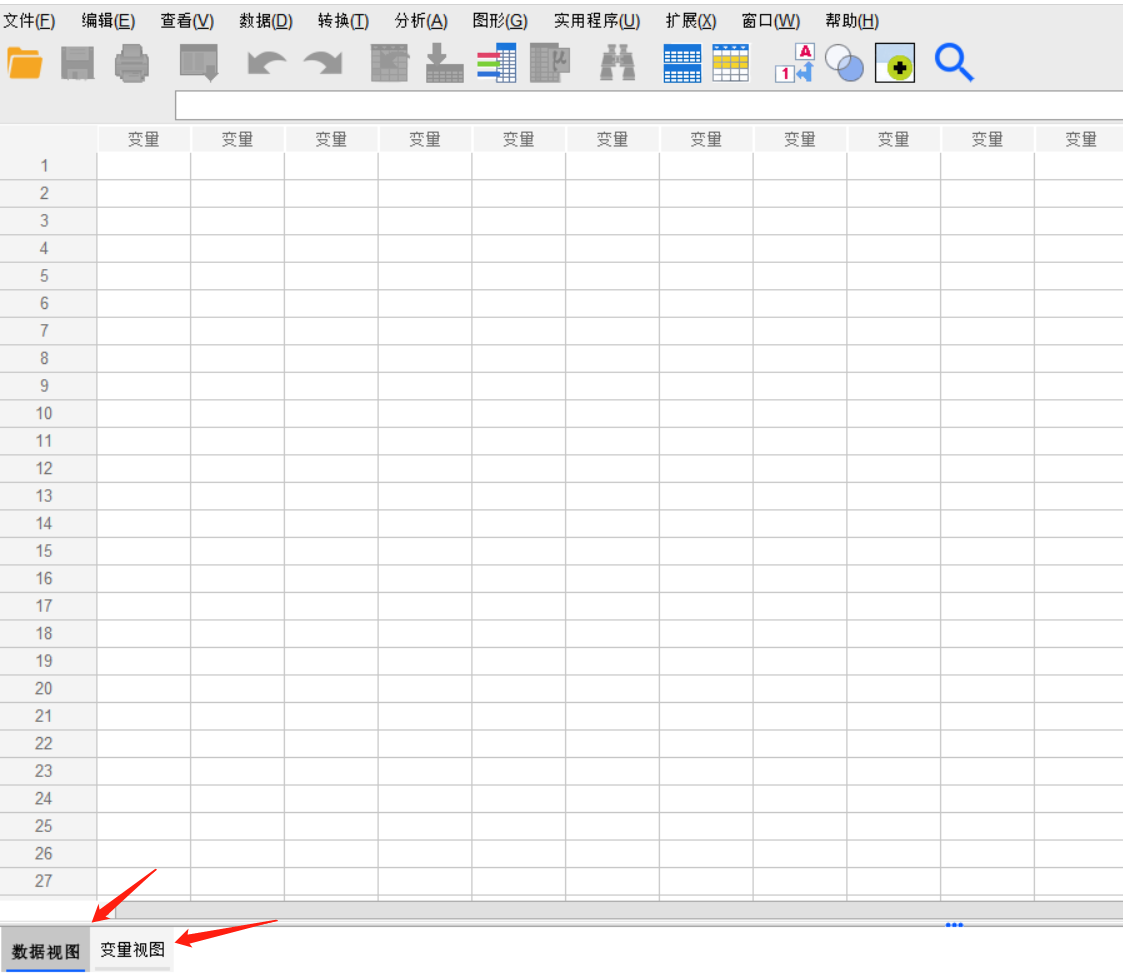
图片1:主操作界面
四、如何定义变量?
我们先定义变量名称,点击进入“变量视图”。
在名称列内输入变量名称。需要注意的是,定义变量名称不能包含空白字符和特殊字符,比如空格、感叹号、问号都不能出现在变量名称中;首字符也不能是“$”,属于无效字符;变量名称的末尾字符也不能出现“.”和下划线。

图片2:定义变量
我们所定义的变量名称也不能重复,英文字母的大小写也属于重复名称。
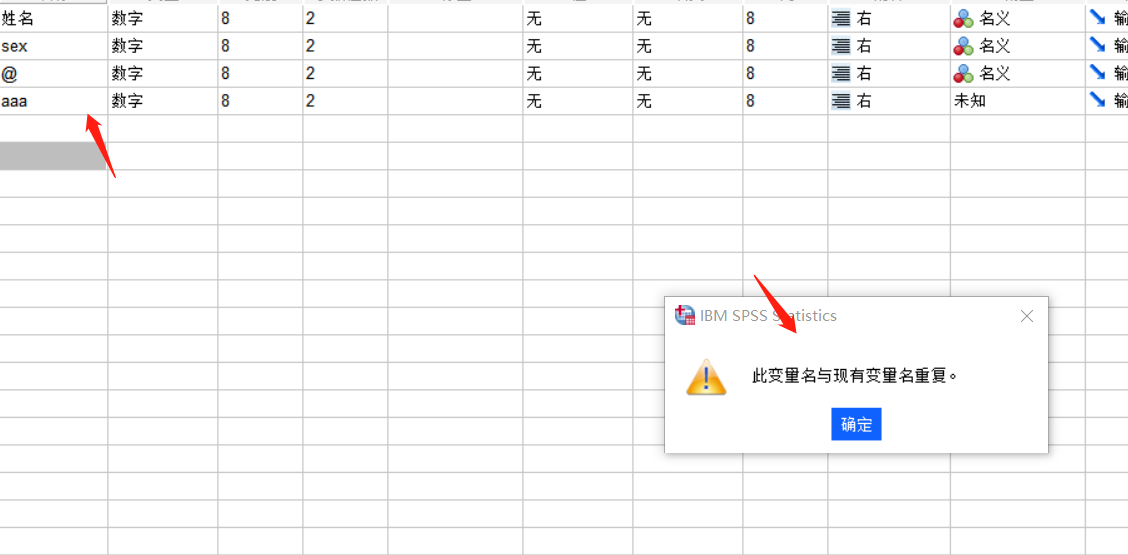
图片3:变量名称重复
定义完变量名称,我们继续定义变量类型,点击类型框后,即可出现如图4的编辑界面。
我们可以定义变量类型为“数字”、“逗号”、“点”、“日期”、“美元”、“字符串”等。
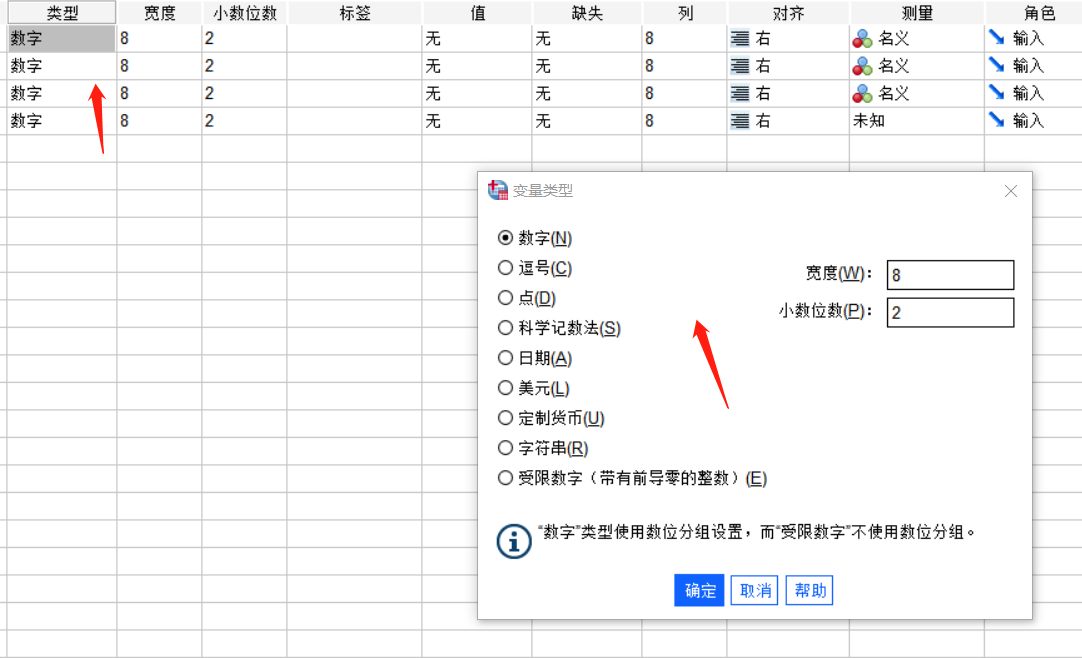
图片4:定义变量类型
SPSS软件系统默认的变量宽度为“8”,我们可以根据自己的需要增加或减少变量宽度。小数位数也同样可以进行调整。
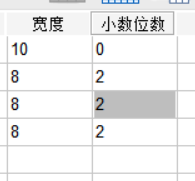
图片5:定义变量宽度和小数位数
“标签”是对定义变量进一步的描述和解释,我们可以在此输入关于变量的细节内容,方便数据的理解。
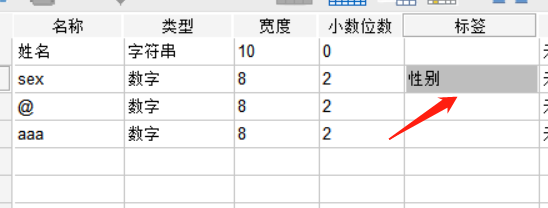
图片6:标签
如图7所示,我们添加了标签的变量在数据视图中就会以这种方式呈现。
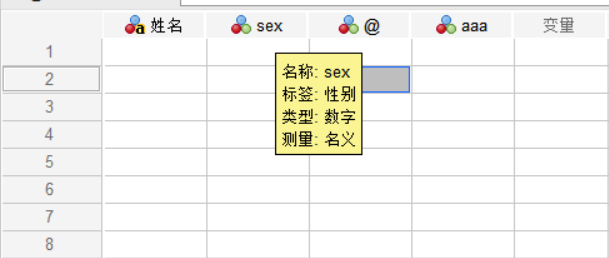
图片7:数据视图体现标签
“变量值”是对变量取值含义的解释说明信息。如图8所示,我们在此界面添加关于变量取值的含义。选中标签后点击“更改”即可对其进行修改。
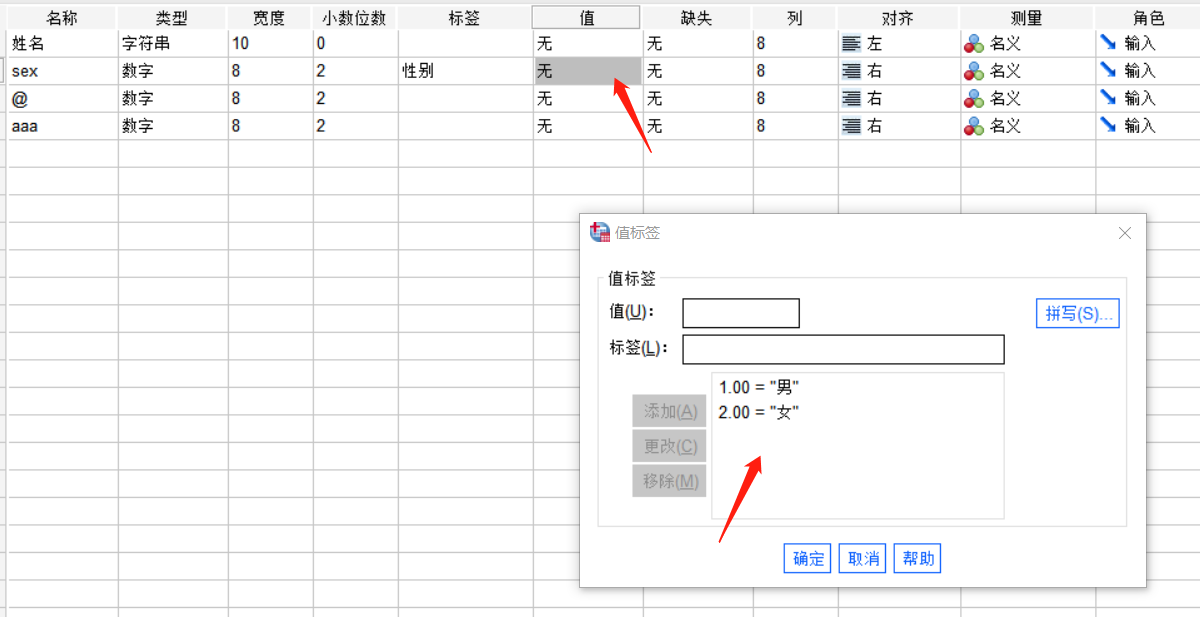
图片8:值标签
SPSS缺失值包含两类,分别是“系统缺失值”和“用户缺失值”。在实际工作中,常常会因为一些原因导致数据失踪,或者由于明显错误或不合理的数据出现导致缺失值的产生。我们为了避免漏填或明显错误的数据出现可以对其进行定义,从而保证数据分析结果的准确性。
如图9所示,“离散缺失值”可以设置三个值,系统进行数据分析时碰到设置的三个数值就会按照缺失值处理。对于一个数值型变量,缺失值也可以出现在一个连续的数值区间内,或者在两个连续的开区间内,并可同时指定一个离散缺失值。
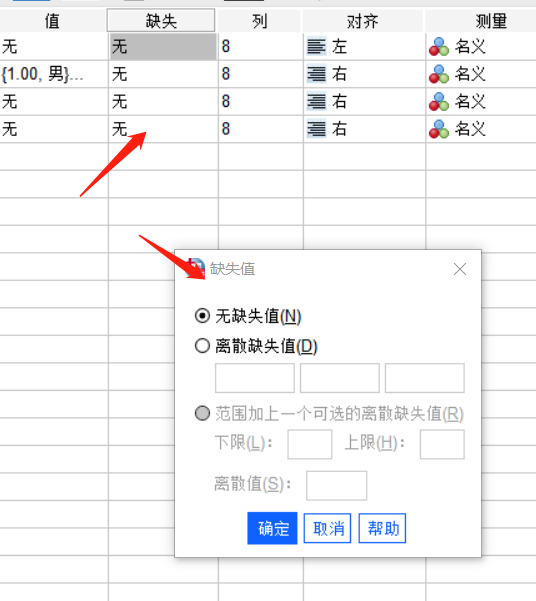
图片9:缺失值
以上是利用IBM SPSS Statistics进行数据分析的过程中,较为重要的几个变量属性,需要我们提前进行定义和设置,从而保证数据分析结果的准确性和真实性!了解了SPSS定义变量的方法,SPSS数据分析新手入门就会变得简单!
作者:鱼子酱
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)