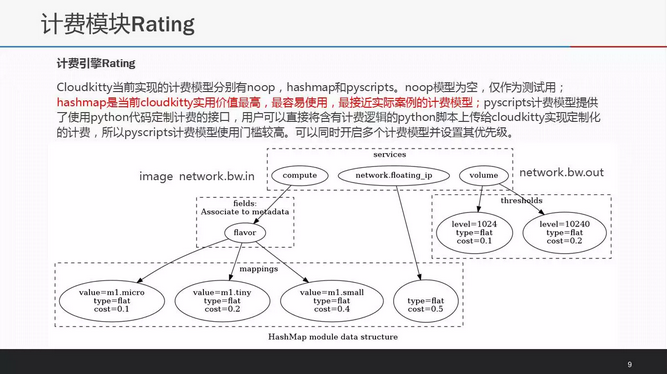
计费模型是实现计费的核心,一般能允许用户根据实际需求设定计费规则并且根据收集到资源数据进行准确的费用计算。Cloudkitty实现了多种计费模型noop,hashmap和pyscripts,允许同时启动多个计费模型,并根据设置的优先级完成执行费用计算。Cloudkitty中的pyscripts计费模型使用门槛较高,hashmap计费模型成为了使用价值最高,易用性最强的计费模型,接下来将详细讲解。

上面那张图展示了hashmap计费模型的例子,可以将其看作简单的树形结构。其模型的核心是它的几个概念:Group,Service,Field,Mapping和Threshold,上面PPT中给了详细的例子做参考。

费用总和可由上面的公式验证。
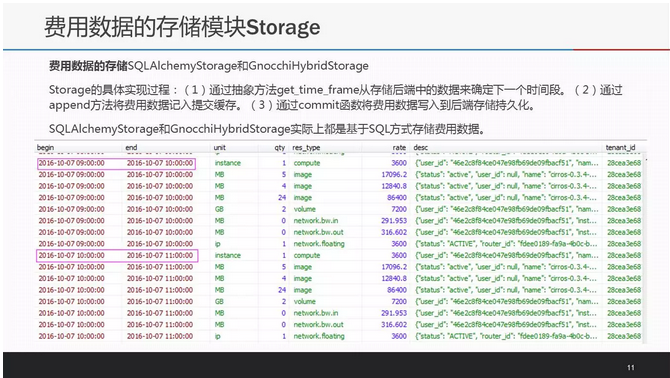
计费模型计算出来的费用数据将由storage模块持久化存储下来,所需记录的核心字段包括begin,end,unit,qty,res_type,desc和tenant_id等,包含了时间信息,资源相关信息,属主信息。每个租户的各项服务费用数据会先缓存下来,最后再将当前租户的当前周期内所产生的费用数据一次性提交到存储后端。
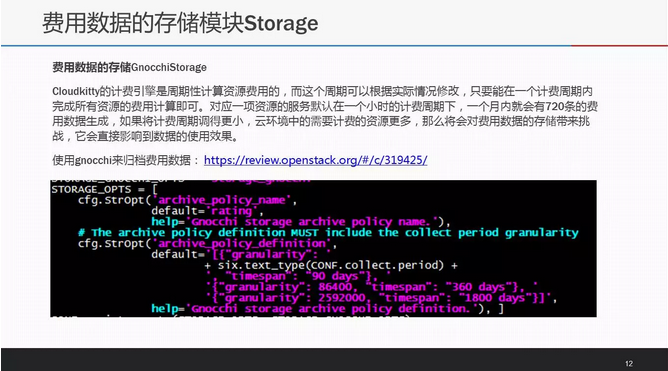
Cloudkitty当前实现的SQLAlchemyStorage和GnocchiHybridStorage实际上都是基于SQL方式存储费用数据。随着云环境中需要计费的项目增多和时间的推移,在使用方面必将会存在于Ceilometer存储measure数据类似的性能瓶颈问题,故使用原生GnocchiStorage来归档费用数据:https://review.openstack.org/#/c/319425/。
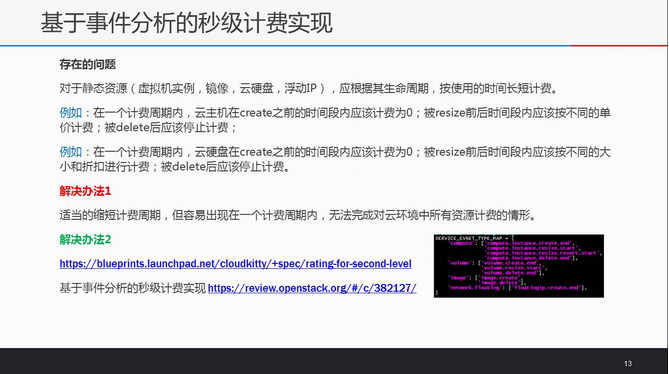
Collector所能收集的数据决定了Cloudkitty所能计费的资源/服务,包括compute,image,volume,network.bw.in,network.bw.out和network.floating。再细分,则计费源主要有两类,一类是静态资源,比如虚拟机实例,镜像,云硬盘,浮动IP,需根据其生命周期按使用时间长短计费;另一类是动态资源,比如网络流量,则需要统计计量情况进行计算费用。这就意味着完善的计费数据源应该包括event和measurement两类,而目前Cloudkitty并不支持event分析,这也是Cloudkitty不能达到秒级计费精度的根本原因。
由于Blueprint(https://blueprints.launchpad.net/cloudkitty/+spec/rating-for-second-level)基于事件分析的秒级计费实现(https://review.openstack.org/#/c/382127/)还未合并到社区,在此做下详细介绍和举例说明。Event模块预计实现三种插件ceilometer(默认) , noop(仅测试用)和 panko(等pankoclient完善后再具体实现)。
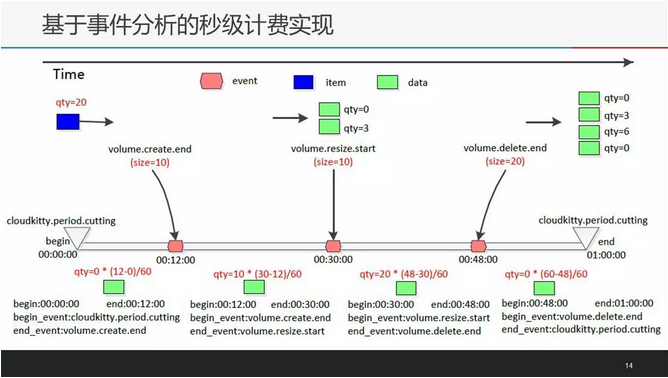
为了保证数据的一致性和不改变原有计费模型的代码,event模块在事件分析的过程中把从collector模块获得的数据进行分片,各个数据分片以时间为轴,保证了时间的连续性和事件的连贯性,过程中仅维护cur_period[\\\'begin\\\']和cur_period[\\\'begin_event\\\']字段即可。
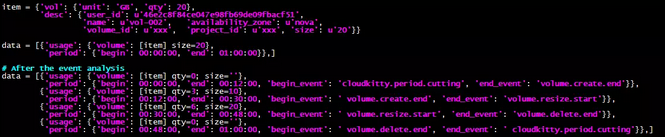
new_item[\\\'vol\\\'][\\\'qty\\\']的值:create事件之前和delete事件之后均置为零,其余片段则按时间占比计算。rate = (generated - cur_period[\\\'begin\\\']) / self._collect_period;new_item[\\\'vol\\\'][\\\'qty\\\'] = item[\\\'vol\\\'][\\\'qty\\\'] * rate。
如果data一旦被分片则slice_flag标识为真,最后需要做分片后处理,否则返回空[]。
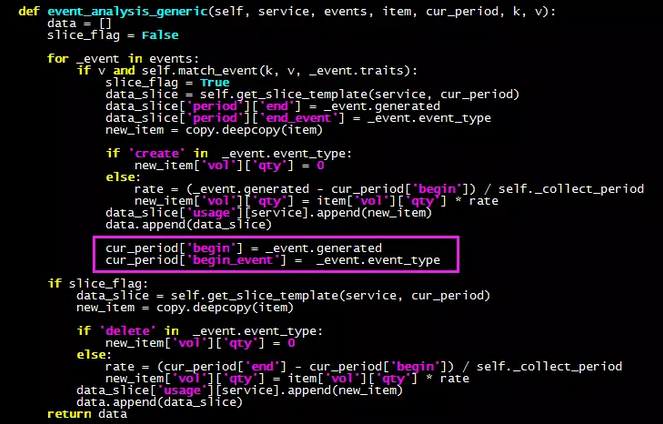
以上是裁剪的代码!另外对item分片的过程中,对于instance和volume需要额外维护desc中的一些字段并配合准确计算qty和适配field,例如volume需要维护size字段,instance需要flavor,vcpus和memory字段等,这些字段的值可以从事件的traits中取得。
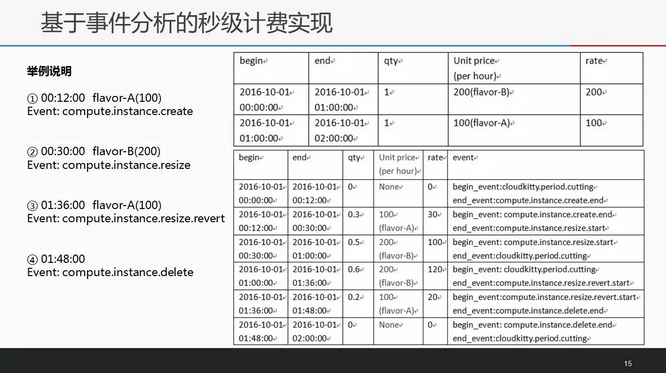
上面是一个关于云主机是否使用“基于事件分析的秒级计费”模块,对比计费的例子。instance生命周期内相关的事件有create,resize,resize.revert和delete,跨越了两个计费周期00:00:00至01:00:00和01:00:00至02:00:00,注意cloudkitty.period.cutting事件的位置。
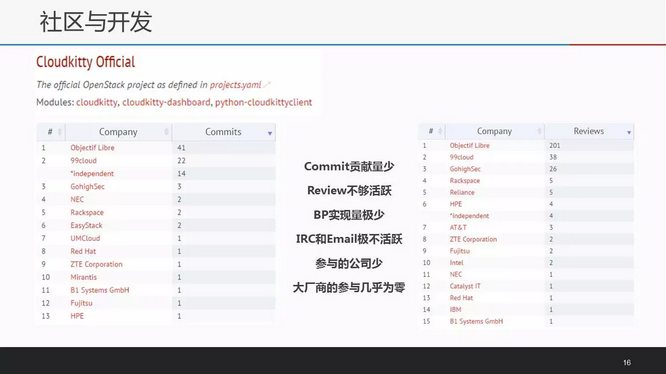
上面两张图来自http://stackalytics.com/统计的关于Cloudkitty在N版本的社区贡献情况。可见并不乐观,因此希望借助本次分享能吸引更多的开发者focus到计费项目中。

这里给出了一些实用的blueprints和参与Cloudkitty社区的一些tips。
本文转载自:http://www.zerotc.com/newsdetail/161.html
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)