///
在.NET框架包含一个托管堆,所有的.NET语言在分配引用类型对象都要使用它,像值类型这样的轻量级别对象始终分配在栈中,但是所有的类实例和数组都被生成在一个内存池中,这个内存池就是托管堆
垃圾收集器的托管的基本算法很简单:
1、将所有的托管内存标记为垃圾
2、寻找正在使用的内存快,并将他们标记为有效
3、释放所有没有被使用的内存块
4、整理堆以减少碎片
看上去很简单,但是垃圾回收器实际采用的步骤和堆管理系统的其他部分并非微不足道,其中常常涉及为提高性能而作的优化设计。举例来说,垃圾收集遍历整个内存池具有很高的开销。然而,研究表明大部分在托管堆上分配的对象只有很短的生存期,因此堆被分成三个段,称作generations。新分配的对象被放在generation 0中。这个generation是最先被回收的----在这个generation中最可能找到不再使用的内存,由于它的尺寸很小(小到足以放进处理器L2cache中),因此在它里面的回收将是最快和最高效的。
托管堆的另外一种优化操作于locality of reference股则有关。该规则表明,一起分配的对象经常被一起使用。如果对象们在堆中位置很紧凑的话,高速缓存的性能将会得到提高。由于托管堆的天性,对象们总是被分配在连续的地址上,托管堆总是保持紧凑,结果使得对象们始终彼此靠近,永远不会分的很远。这一点于标准堆提供的非托管代码形成了鲜明的对比,在标准堆中,堆很容易变成碎片,而且一起分配的对象经常分得很远。
还有一种优化是与大对象有关的,通常,大对象具有很长的生存期。当一个大对象在.NET托管堆中产生时,它被分配在堆的一个特殊部分中,这部分堆永远不会被整理。因为移动大对象所带来的开销超过了整理这部分堆所提高的性能。
关于外部资源(External Resource)的问题
垃圾收集器能够有效的管理从托管堆中释放的资源,但是资源回收操作只有在内存紧张而触发一个回收动作时才执行。那么,类是怎样来管理像数据库连接或者窗口句柄这样有限资源的呢?等待,直到垃圾回收被触发之后再清理数据库连接或者文件句柄并不是一个好方法,这回严重降低系统的性能。
所有拥有外部资源的类,在这些资源已经不再用到的时候,都应当执行Close或者Dispose方法。从Beta2(译注:本文所有的Beta2)开始,Dispose模式通过IDisposable接口来实现。
需要清理外部资源的类还应当一个终止操作(finalizer)。在c#中,创建终止操作的首选方式是在析构函数中实现,在Framwork层,终止操作的实现则是通过重载System.Object.Finalize方法。以下两种实现终止操作的方法是等效的:
~OverdueBookLocator()
{
Dispose(false);
}
和
public void Finalize()
{
base.Finalize();
Dispose(false);
}
在c#中,同时在Finalize方法和析构函数实现终止操作将会导致错误的产生。
除非你有足够的理由,否则你不应该创建析构函数或者Finalize方法。终止操作会降低系统的性能,并且增加执行期的内存开销。同时,由于终止操作被执行的方式,你并不能保证何时一个终止操作会被执行。
内存分配和垃圾回收的细节
对GC有了一个总体印象之后,让我们来讨论关于托管堆中的分配于回收工作的细节。托管堆看起来与我们已经收悉的c++编程中的传统堆一点都不像。在传统的堆中,数据结构习惯于大块的空闲内存。在其中查找特定大小的内存快是一件很耗时的工作,尤其是当内存中充满碎片的时候。与此不同,在托管堆中,内存被组制成连续的数组,指针总是巡着已经被使用的内存和未被使用的内存之间的边界移动。当内存被分配的时候,指针只是简单递增——有此而来的一个好处是,分配操作的效率得到了很大的提升。
当对象被分配的时候,他们一开始被放在generation 0中。当generation 0的大小快要达到它的上限的时候,一个只在generation 0中执行的回收操作被触发。由于generation 0的大小很小,因此这将是一个非常快得GC过程。这个GC过程的结果是将generation 0彻底的刷新了一遍。不再使用的对象被释放,确实正被使用的对象被整理并移入generation 1中。
当generation 1的大小随着generation 0中移动的对象数量的增加而接近他的上限的时候,一个回收动作被触发来在generation 0和generation 1中执行GC过程,如同generation 0中一样,不再使用的对象被释放,正被使用的对象被整理并移入了下一个generation中。大部分GC过程的主要目标是generation 0,因为在generation 0中最可能存在大量的已不再使用的临时变量。堆generation 2的回收过程具有很高的开销,并且此过程只有在generation 0和generation 1的GC过程不能释放足够的内存时才会被触发。如果对generation 2的过程GC过程仍然不能释放足够的内存,那么系统就抛出OutOfMemoryException异常(内存溢出)
带有终止操作的对象的垃圾收集过程要稍微复杂一些。当一个带有终止操作的对象被标记为垃圾时,它并不会被立即释放。相反,它会被放置在一个终止队列(finalization queue)中,此队列为这个对象建立一个引用,来避免这个对象被回收。后台线程为队列中的每个对象执行他们各自的终止操作,并且将已经执行终止操作的对象从终止队列中删除。只有那些已经执行过终止操作的对象才会在下一次垃圾回收过程中被内存中删除。这样做的一个后果是,等待被终止的对象有可能在它被清空之前,被移入更高一级generaton中,从而增加它被清除的延迟时间。
需要执行终止操作的对象应当实现IDisposeable接口,以便客户程序通过此接口快速执行终止动作。IDispoable接口包含一个方法---Dispose.这个被Beta2引入的接口,采用一种在Beta2之前就已经被广泛使用的模式实现。从本质上讲,一个需要终止操作的对象暴漏出Dispose方法。这个方法被用来释放外部资源并抑制终止操作,就像下面这个程序片段演示的那样:
public class OverdueBookLocator:IDisposeable
{
~OverdueBookLocator()
{
InternalDispose(false);
}
public void Dispose()
{
InternalDispose(true);
}
protected void InternalDispose(bool diposing)
{
if(isposing)
{
GC.SuppressFinalize(this);
}
}
}
使用基于CLR的语言编译器开发的代码都成为托管代码。
托管堆是CLR中自动内存管理的基础。初始化新进程时,运行会为进程保留一个连续的地址空间区域。这个保留的地址空间被称为托管堆。托管堆维护着一个指针,用它指向将在堆中分配的下一个对象的地址。最初,该指针设置为指向托管堆的基址。
以下代码说明的很形象:
//引用类型(‘class’类类型)
class SomeRef
{
public int32 x;
}
//值类型(‘struct’)
struct SomeVa
{
public Int32 x;
}
static void Value TypeDemo()
{
SomeRef r1=new SomeRef();//分配在托管堆
SomeVal v1=new SomeVal();//分配堆栈上
r1.x=5;//解析指针
v1.x=5;//在堆栈上修改
SomeRef r2=r1;//仅拷贝引用(指针)
SomerVal v2=v1;//先在堆栈上分配,然后拷贝成员
r1.x=8;//改变了r1,r2的值
v1.x=9;//改变了v1,没有改变v2
}
-------------------------------------------------------------------------------------------------------
栈是内存中完全用于存储局部变量或成员(值类型数据)的高效区域,但其大小有限制。
托管堆占内存比栈大得多,当访问速度较慢。托管堆只用于分配内存,一般有CLR来出来释放问题。
当创建值类型数据时,在栈上分配内存;
当创建引用型数据时,在托管堆上分配内存并返回对象的引用。注意这个对象的引用,像其他局部变量一样也是保存在栈中,该引用指向的值则位于托管堆中。
如果创建一个包含值类型的引用类型,比如数组,其元素的值也是存放在托管堆中的某个地方,由使用该实体的变量引用;而值类型存储在使用它们的地方,有几处在使用,就有几个副本存在。
对于引用类型,如果在声明变量的时候没有使用new运算符,运行时不会给它分配托管堆的内存空间,而是在栈伤给她分配一个包含null值的引用。对于值类型,运行时会给它分配栈上的空间,并且调用构造函数来初始化对象的状态。
------------------------------------------------------------------------------------------------------
一、栈和托管堆
通用类型系统(CTS)区分两种基本类型:值类型和引用类型。它们之间的根本区别在于它们在内存中的存储方式。.NET使用两种不同的物理内存快来存储数据------栈和托管堆:

值类型总是在内存中占用一个预定义的字节数(例如,int类型占4个字节,而string类型占用的字节数会根据字符串的长度而不同)。当生命一个值类型变量时,会在栈中分配适当大小的内存(除了引用类型的值类型成员外,如类的int字段)。内存中的这个空间用来存储变量所包含的值。.NET维护一个栈指针,它包含栈中下一个可用的内存空间的地址。当一个变量离开作用域时,栈指针指向下移动被释放变量所占有的字节数。所以它仍指向下一个可用地址。
引用变量也利用栈,但这时候栈包含的只是对另一个内存位置的引用,而不是实际值。这个位置是托管堆中的一个地址,和栈一样,他也维护一个指针,包含堆中下一个可用的内存地址。但是,堆不是先入后出的,因为对对象的引用可在我们的程序中传递(例如,作为参数传递给方法调用)。堆中的对象不会在程序的一个预定点离开作用域。为了在不适用在堆中分配的内存时将它释放。.NET定期执行垃圾回收集,垃圾收集递归检查应用程序中所有对象的引用。引用不再有效的对象使用的内存无法从程序中访问,该内存就可以回收。
二、类型层次结构
CTS定义了一种类型层次结构,该结构不仅仅描述了不同预定义类型,还指出了用户定义类型的层次结构中的

三、引用类型
引用类型包含一个指针,指向堆中存储对象本身的位置。因为引用类型只包含实际的值,对方法体内参数所做的任何修改都将影响传递给方法调用的引用类型的变量。
下图显示了声明一个字符串变量并把它作为参数传递给一个方法时所发生的事情。
string s1="something";
DoSomething(s1);
//.....
DoSomething(string s2)
{
//....
}

当声明一个字符变量s1时,一个值被压入栈中,它指向栈中的一个位置,在上图中,引用存放在地址1243044中,而实际的字符串存放在堆地址12662032中,当该字符串传递给一个方法中,在栈伤对应输入参数声明了一个新德变量(这次是在地址1243032上),保存在引用变量,即堆中内存位置中的值被传递给这个新德变量。
委托是引用方法的一种引用类型,类似于c++中的函数指针(两者的主要区别于委托包括调用其方法的对象)。
四、预定义的引用类型
有两种引用类型在c#中受到了特别的重视,他们的c#别名和预定义值类型的c#别名很相像。第一种是object(c#别名是object,o小写)。这是所有值类型和引用类型的最终基类。因为所有的类型派生object,所以可以把任何类型转换成Object,甚至值类型也可以转换。这个把值类型转换为Object的过程称为装箱。所有的值类型都派生自引用类型,在这件事看似矛盾的事情背后,装箱的作用不可或缺。
第二种是String类,字符串代表一个固定不变的Unicode字符序列,这种不变性意味着,一旦在堆中分配了一个字符串,他的值将永远不会改变,如果值该改变了,.NET就创建一个全新的String对象,并把它赋值给该变量,这意味着,字符串在很多方面都像值类型,而不像引用类型。如果把一个字符串传递给方法。然后在方法体内改变参数的值,这不会影响最初的字符串(当然,除非参数按引用传递的)。c#提供了别名String(s小写)来代表System.String类,如果代码中使用String,必须在代码一开始添加Using System;这一行。使用内建的别名string则不需要using System;
NET垃圾回收器(GC)原理浅析
这篇文章主要介绍了.NET垃圾回收器(GC)原理浅析,本文先是讲解了一些基础知识如托管堆(Managed Heap)、CPU寄存器(CPU Register)、根(Roots)等,然后讲解了垃圾回收的基本原理、算法等,需要的朋友可以参考下
作为.NET进阶内容的一部分,垃圾回收器(简称GC)是必须了解的内容。本着“通俗易懂”的原则,本文将解释CLR中垃圾回收器的工作原理。
基础知识
托管堆(Managed Heap)
先来看MSDN的解释:初始化新进程时,运行时会为进程保留一个连续的地址空间区域。这个保留的地址空间被称为托管堆。
“托管堆也是堆”,为什么这样说呢?这么说是希望大家不要被“术语”迷惑,这个知识点的前提是“值类型和引用类型的区别”。这里假设读者已经知道“值类型存储在栈中,引用类型存储在堆中。(引用类型的引用存储在栈中)”这一重要概念。所以,根据这个理论,除值类型外,CLR要求所有资源都从托管堆分配。
托管堆维护着一个指针,这里命名为NextObjPtr,它指向下一个对象在堆中的分配位置。

CPU寄存器(CPU Register)
这个是计算机基础知识,这里复习一下,有助于对下面“根”概念的理解。
CPU寄存器是CPU自己的”临时存储器”,比内存的存取还快。按与CPU远近来分,离得最近的是寄存器,然后缓存(计算机一、二、三级缓存),最后内存。
根(Roots)
类中定义的任何静态字段,方法的参数,局部变量(仅限引用类型变量)等都是根,另外cpu寄存器中的对象指针也是根。根是CLR在堆之外可以找到的各种入口点。
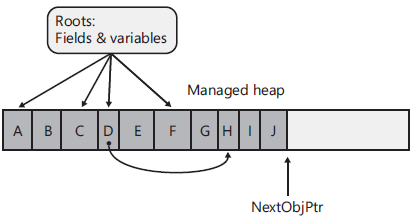
对象可达与不可达(Objects reachable and unreachable)
如果一个根引用了堆中的一个对象,则该对象为“可达”,否则即是“不可达”。
垃圾回收的原因
从计算机组成的角度来讲,所有的程序都是要驻留在内存中运行的。而内存是一个限制因素(大小)。除此之外,托管堆也有大小限制。如果托管堆没有大小限制,那C#的执行速度要优于c了(托管堆的结构让它有比c运行时堆更快的对象分配速度)。因为地址空间和存储的限制因素,托管堆要通过垃圾回收机制,来维持它的正常运作,保证对象的分配,不会“内存溢出”。
垃圾回收的基本原理
回收分为两个阶段: 标记 –> 压缩
标记的过程,其实就是判断对象是否可达的过程。当所有的根都检查完毕后,堆中将包含可达(已标记)与不可达(未标记)对象。
标记完成后,进入压缩阶段。在这个阶段中,垃圾回收器线性的遍历堆,以寻找不可达对象的连续内存块。并把可达对象移动到这里以压缩堆。这个过程有点类似于磁盘空间的碎片整理。

如上图所示,绿色框表示可达对象,黄色框为不可达对象。不可达对象清除后,移动可达对象实现内存压缩(变得更紧凑)。
压缩之后,“指向这些对象的指针”的变量和CPU寄存器现在都会失效,垃圾回收器必须重新访问所有根,并修改它们来指向对象的新内存位置。这会造成显著的性能损失。这个损失也是托管堆的主要缺点。
基于以上特点,垃圾回收引发的回收算法也是一项研究课题。因为如果真等到托管堆满才开始执行垃圾回收,那就真的太“慢”了。
垃圾回收算法 – 分代(Generation)算法
代是CLR垃圾回收器采用的一种机制,它唯一的目的就是提升应用程序的性能。分代回收,速度显然快于回收整个堆。
CLR托管堆支持3代:第0代,第1代,第2代。第0代的空间约为256KB,第1代约为2M,第2代约为10M。新构造的对象会被分配到第0代。

如上图所示,当第0代的空间满时,垃圾回收器启动回收,不可达对象(上图C、E)会被回收,存活的对象被归为第1代。
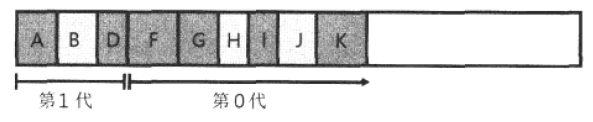
当第0代空间已满,第1代也开始有很多不可达对象以至空间将满时,这时两代垃圾都将被回收。存活下来的对象(可达对象),第0代升为第1代,第1代升为第2代。
实际CLR的代回收机制更加“智能”,如果新创建的对象生存周期很短,第0代垃圾也会立刻被垃圾回收器回收(不用等空间分配满)。另外,如果回收了第0代,发现还有很多对象“可达”,
并没有释放多少内存,就会增大第0代的预算至512KB,回收效果就会转变为:垃圾回收的次数将减少,但每次都会回收大量的内存。如果还没有释放多少内存,垃圾回收器将执行
完全回收(3代),如果还是不够,则会抛出“内存溢出”异常。
也就是说,垃圾回收器会根据回收内存的大小,动态的调整每一代的分配空间预算!达到自动优化!
总结
垃圾回收背后有这样一个基本的观念:编程语言(大多数的)似乎总能访问无限的内存。而开发者可以一直分配、分配再分配——像魔法一样,取之不尽用之不竭。
.NET垃圾回收器的基本工作原理是:通过最基本的标记清除原理,清除不可达对象;再像磁盘碎片整理一样压缩、整理可用内存;最后通过分代算法实现性能最优化。
//
详谈.net中的垃圾回收机制
1. 自动内存管理和GC
在原始程序中堆的内存分配是这样的:找到第一个有足够空间的内存地址(没被占用的),然后将该内存分配。当程序不再需要此内存中的信息时程序员需要手动将此内存释放。堆的内存是公用的,也就是说所有进程都有可能覆盖另一进程的内存内容,这就是为什么很多设计不当的程序甚至会让操作系统本身都down掉。我们有时碰到的程序莫名其妙的死掉了(随机现象),也是因为内存管理不当引起的(可能由于本身程序的内存问题或是外来程序造成的)。另一个常见的实例就是大家经常看到的游戏的Trainer,他们通过直接修改游戏的内存达到"无敌"的效果。明白了这些我们可以想象如果内存地址被用混乱了的话会多么危险,我们也可以想象为什么C++程序员(某些)一提起指针就头疼的原因了。另外,如果程序中的内存不被程序员手动释放的话那么这个内存就不会被重新分配,直到电脑重起为止,也就是我们所说的内存泄漏。所说的这些是在非托管代码中,CLR通过AppDomain实现代码间的隔离避免了这些内存管理问题,也就是说一个AppDomain在一般情况下不能读/写另一AppDomain的内存。托管内存释放就由GC(Garbage Collector)来负责。我们要进一步讲述的就是这个GC,但是在这之前要先讲一下托管代码中内存的分配,托管堆中内存的分配是顺序的,也就是说一个挨着一个的分配。这样内存分配的速度就要比原始程序高,但是高出的速度会被GC找回去。为什么?看过GC的工作方式后你就会知道答案了。
2. GC工作方式
首先我们要知道托管代码中的对象什么时候回收我们管不了(除非用GC.Collect**GC回收,这不推荐,后面会说明为什么)。GC会在它"高兴"的时候执行一次回收(这有许多原因,比如内存不够用时。这样做是为了提高内存分配、回收的效率)。那么如果我们用Destructor呢?同样不行,因为.NET中Destructor的概念已经不存在了,它变成了Finalizer,这会在后面讲到。目前请记住一个对象只有在没有任何引用的情况下才能够被回收。为了说明这一点请看下面这一段代码:
view sourceprint?object objA = new object();
object objB = objA;
objA = null;
// **回收。
GC.Collect();
objB.ToString();
这里objA引用的对象并没有被回收,因为这个对象还有另一个引用,ObjB。对象在没有任何引用后就有条件被回收了。
当GC回收时,它会做以下几步:
1、确定对象没有任何引用。
2、检查对象是否在Finalizer表上有记录。如果在Finalizer表上有记录,那么将记录移到另外的一张表上,在这里我们叫它Finalizer2。如果不在Finalizer2表上有记录,那么释放内存。在Finalizer2表上的对象的Finalizer会在另外一个low priority的线程上执行后从表上删除。当对象被创建时GC会检查对象是否有Finalizer,如果有就会在Finalizer表中添加纪录。我们这里所说的记录其实就是指针。如果仔细看这几个步骤,我们就会发现有Finalizer的对象第一次不会被回收,也就是,有Finalizer的对象要一次以上的Collect操作才会被回收,这样就要慢一步,所以作者推荐除非是绝对需要不要创建Finalizer。
GC为了提高回收的效率使用了Generation的概念,原理是这样的,第一次回收之前创建的对象属于Generation 0,之后,每次回收时这个Generation的号码就会向后挪一,也就是说,第二次回收时原来的Generation 0变成了Generation 1,而在第一次回收后和第二次回收前创建的对象将属于Generation 0。GC会先试着在属于Generation 0的对象中回收,因为这些是最新的,所以最有可能会被回收,比如一些函数中的局部变量在退出函数时就没有引用了(可被回收)。如果在Generation 0中回收了足够的内存,那么GC就不会再接着回收了,如果回收的还不够,那么GC就试着在Generation 1中回收,如果还不够就在Generation 2中回收,以此类推。Generation也有个最大限制,根据Framework版本而定,可以用GC.MaxGeneration获得。在回收了内存之后GC会重新排整内存,让数据间没有空格,这样是因为CLR顺序分配内存,所以内存之间不能有空着的内存。现在我们知道每次回收时都会浪费一定的CPU时间,这就是我说的一般不要手动GC.Collect的原因。
当我们用Destructor的语法时,编译器会自动将它写为protected virtual void Finalize(),这个方法就是我所说的Finalizer。就象它的名字所说,它用来结束某些事物,不是用来摧毁(Destruct)事物。在Visual Basic中它就是以Finalize方法的形式出现的,所以Visual Basic程序员就不用操心了。C#程序员得用Destructor的语法写Finalizer,不过千万不要弄混了,.NET中已经没有Destructor了。C++中我们可以准确的知道什么时候会执行Destructor,不过在.NET中我们不能知道什么时候会执行Finalizer,因为它是在第一次对象回收操作后才执行的。我们也不能知道Finalizer的执行顺序,也就是说同样的情况下,A的Finalize可能先被执行,B的后执行,也可能A的后执行而B的先执行。也就是说,在Finalizer中我们的代码不能有任何的时间逻辑。下面我们以计算一个类有多少个实例为示例,指出Finalizer与Destructor的不同并指出在Finalizer中有时间逻辑的错误:
view sourceprint?public class CountObject {
public static int Count = 0;
public CountObject() {
Count++;
}
~CountObject() {
Count--;
}
}
static void Main() {
CountObject obj;
for (int i = 0; i < 5; i++) {
obj = null; // 这一步多余,这么写只是为了更清晰些!
obj = new CountObject();
}
// Count不会是1,因为Finalizer不会马上被触发,要等到有一次回收操作后才会被触发。
Console.WriteLine(CountObject.Count);
Console.ReadLine();
}
注意以上代码要是改用C++写的话会发生内存泄漏,因为我们没有用delete操作符手动清理内存,但是在托管代码中却不会发生内存泄漏,因为GC会自动检测没有引用了的对象并回收。这里作者推荐你只在实现IDisposable接口时配合使用Finalizer,在其他的情况下不要使用(可能会有特殊情况)。
3. 对象的复活
什么?回收的对象也可以"复活"吗?没错,虽然这么说的定义不准确。让我们先来看一段代码:
view sourceprint?public class Resurrection {
public int Data;
public Resurrection(int data) {
this.Data = data;
}
~Resurrection() {
Main.Instance = this;
}
}
public class Main {
public static Resurrection Instance;
public static void Main() {
Instance = new Resurrection(1);
Instance = null;
GC.Collect();
GC.WaitForPendingFinalizers();
// 看到了吗,在这里“复活”了。
Console.WriteLine(Instance.Data);
Instance = null;
GC.Collect();
Console.ReadLine();
}
}
你可能会问:"既然这个对象能复活,那么这个对象在程序结束后会被回收吗?"。会,"为什么?"。让我们按照GC的工作方式走一遍你就明白是怎么回事了。
1、执行Collect。检查引用。没问题,对象已经没有引用了。
2、创建新实例时已经在Finalizer表上作了纪录,所以我们检查到了对象有Finalizer。
3、因为查到了Finalizer,所以将记录移到Finalizer2表上。
4、在Finalizer2表上有记录,所以不释放内存。
5、Collect执行完毕。这时我们用了GC.WaitForPendingFinalizers,所以我们将等待所有Finalizer2表上的Finalizers的执行。
6、Finalizer执行后我们的Instance就又引用了我们的对象。(复活了)
7、再一次去除所有的引用。
8、执行Collect。检查引用。没问题。
9、由于上次已经将记录从Finalizer表删除,所以这次没有查到对象有Finalizer。
10、在Finalizer2表上也不存在,所以对象的内存被释放了。
非托管资源的释放到现在为止,我们说了托管内存的管理,那么当我们利用如数据库、文件等非托管资源时呢?这时我们就要用到.NET Framework中的标准:IDisposable接口。按照标准,所有有需要手动释放非托管资源的类都得实现此接口。这个接口只有一个方法,Dispose(),不过有相对的Guidelines指示如何实现此接口,在这里我向大家说一说。实现IDisposable这个接口的类需要有这样的结构:
view sourceprint?public class Base : IDisposable {
public void Dispose() {
this.Dispose(true);
GC.SupressFinalize(this);
}
protected virtual void Dispose(bool disposing) {
if (disposing) {
// 托管类
}
// 非托管资源释放
}
~Base() {
this.Dispose(false);
}
}
public class Derive : Base {
protected override void Dispose(bool disposing) {
if (disposing) {
// 托管类
}
// 非托管资源释放
base.Dispose(disposing);
}
}
为什么要这样设计呢?让我在后面解说一下。现在我们讲讲实现这个Dispose方法的几个准则:它不能扔出任何错误,重复的调用也不能扔出错误。也就是说,如果我已经调用了一个对象的Dispose,当我第二次调用Dispose的时候程序不应该出错,简单地说程序在第二次调用Dispose时不会做任何事。这些可以通过一个flag或多重if判断实现。一个对象的Dispose要做到释放这个对象的所有资源。拿一个继承类为例,继承类中用到了非托管资源所以它实现了IDisposable接口,如果继承类的基类也用到了非托管资源那么基类也得被释放,基类的资源如何在继承类中释放呢?当然是通过一个virtual/Overridable方法了,这样我们能保证每个Dispose都被调用到。这就是为什么我们的设计有一个virtual/Overridable的Dispose方法。注意我们首先要释放继承类的资源然后再释放基类的资源。因为非托管资源一定要被保障正确释放所以我们要定义一个Finalizer来避免程序员忘了调用Dispose的情况。上面的设计就采用了这种形式。如果我们手动调用Dispose方法就没有必要再保留Finalizer了,所以在Dispose中我们用了GC.SupressFinalize将对象从Finalizer表去掉,这样再回收时速度会更快。那么那个disposing和"托管类"是怎么回事呢?是这样:在"托管类"中写所有你想在调用Dispose时让其处于可释放状态的托管代码。还记得我们说过我们不知道托管代码是什么时候释放的吗?在这里我们只是去掉成员对象的引用让它处于可被回收状态,并不是直接释放内存。在"托管类"中这里我们也要写上所有实现了IDisposable的成员对象,因为他们也有Dispose,所以也需要在对象的Dispose中调用他们的Dispose,这样才能保证第二个准则。disposing是为了区分Dispose的调用方法,如果我们手动调用那么为了第二个准则"托管类"部分当然得执行,但如果是Finalizer调用的Dispose,这时候对象已经没有任何引用,也就是说对象的成员自然也就不存在了(无引用),也就没有必要执行"托管类"部分了,因为他们已经处于可被回收状态了。好了,这就是IDisposable接口的全部了。现在让我们来回想一下,以前我们可能认为有了Dispose内存就会马上被释放,这是错误的。只有非托管内存才会被马上释放,托管内存的释放由GC管理,我们不用管。
4. 弱引用的使用
A = B,我们称这样的引用叫做强引用,GC就是通过检查强引用来决定一个对象是否是可以回收的。另外还有一种引用称作弱引用(WeakReference),这种引用不影响GC回收,这就是它的用处所在。你会问到底有什么用处。现在我们来假设我们有一个很胖的对象,也就是说它占用很多内存。我们用过了这个对象,打算将它的引用去掉好让GC可以回收内存,但是功夫不大我们又需要这个对象了,没办法,重新创建实例,怎么创建这么慢啊?有什么办法解决这样的问题?有,将对象留在内存中不就快了嘛!不过我们不想这样胖得对象总占着内存,而我们也不想总是创建这样胖的新实例,因为这样很耗时。那怎么办……?聪明的朋友一定已经猜到了我要说解决方法是弱引用。不错,就是它。我们可以创建一个这个胖对象的弱引用,这样在内存不够时GC可以回收,不影响内存使用,而在没有被GC回收前我们还可以再次利用该对象。这里有一个示例:
view sourceprint?public class Fat {
public int Data;
public Fat(int data) {
this.Data = data;
}
}
public class Main {
public static void Main() {
Fat oFat = new Fat(1);
WeakReference oFatRef = new WeakReference(oFat);
// 从这里开始,Fat对象可以被回收了。
oFat = null;
if (oFatRef.IsAlive) {
Console.WriteLine(((Fat) oFatRef.Target).Data); // 1
}
// 强制回收。
GC.Collect();
Console.WriteLine(oFatRef.IsAlive); // False
Console.ReadLine();
}
}
这里我们的Fat其实并不是很胖,但是可以体现示例的本意:如何使用弱引用。那如果Fat有Finalizer呢,会怎样?如果Fat有Finalizer那么我们可能会用到WeakReference的另一个构造函数,当中有一参数叫做TrackResurrection,如果是True,只要Fat的内存没被释放我们就可以用它,也就是说Fat的Finalizer执行后我们还是可以恢复Fat(相当于第一次回收操作后还可恢复Fat);如果TrackResurrection是False,那么第一次回收操作后就不能恢复Fat对象了。
5. 总结
我在这里写出了正篇文章的要点:
一个对象只当在没有任何引用的情况下才会被回收。
一个对象的内存不是马上释放的,GC会在任何时候将其回收。一般情况下不要强制回收工作。
如果没有特殊的需要不要写Finalizer。
不要在Finalizer中写一些有时间逻辑的代码。
在任何有非托管资源或含有Dispose的成员的类中实现IDisposable接口。
按照给出的Dispose设计写自己的Dispose代码。
当用胖对象时可以考虑弱引用的使用。
.Net的GC垃圾回收原理及实现
一、先了解下必备的知识前提
内存中的托管与非托管,可简单理解为:
托管:可借助GC从内存中释放的数据对象(以下要描述的内容点)
非托管:必须手工借助Dispose释放资源(实现自IDisposable)的对象
内存中有栈和堆的概念区分,仅简单说明:
栈:先进后出 的特点(这里不再详细阐述)
堆:存放数据对象实例的内存空间(以下要描述的内容点)
二、.Net GC的简单描述
GC垃圾回收是对于内存堆的处理过程。
当一个应用程序进程创建时,会为此应用程序在物理内存堆中分配一块虚拟的连续性内存空间,以供应用程序后续运行时存放产生的数据对象实例。
GC是一个独立的进程,用来自动维护管理内存堆中的空间分配和释放。它通过一个或多个线程进行垃圾回收,默认启用后台线程垃圾回收。(关于前台线程与后台线程,可参考其它)
三、.Net平台的GC垃圾回收,什么时候会被触发呢?
1、当被分配的堆中虚拟内存空间不够用时,系统会自动 回收/压缩/扩大 被分配的虚拟内存块,以适应新产生的数据对象存储。
2、当整个物理内存不够用时,系统会自动 回收/压缩 各个进程占用的内存空间,以适应新产生的数据对象存储。
3、当应用程序中手动触发GC回收时,GC按照手动指定的方式进行垃圾回收。
四、从作用域上 去理解堆中的代
先这样去理解吧
假设一个实例变量声明时的作用域较大,那它就不会马上被回收,因为作用域大的因素,有可能后续程序时常还会被用到。
假设一个实例变量声明时的作用域较小,那它就有可能被优先回收,因为生存周期较短,过了作用域范围,此变量不会再被使用。
假设一个静态的或全局的作用域变量,那它通常不会被回收,因为这样的全局声明会在任意代码段长期被使用。
所以,为了更好的回收,堆中将各数据对象实例归纳为:0代、1代、2代
0代:临时或最新创建的数据对象实例。最常被回收的对象实例。
1代:一段时间内再次使用的数据对象实例,生命周期较长的数据对象实例。较少被回收的对象实例。
2代:常住内存的对象实例,如:静态类型,全局作用域等的对象实例。通常为应用程序退出后回收。
五、堆中对象 在代之间的转移:幸存者的提升
应用程序持续运行中,
新创建的对象首先被放在0代中,当运行一段时间后,有些变量超出了自己所在的作用域,不会再被使用,会被GC清理;
由于有些变量作用域大,当前还未超出自己所在的作用域,接下来可能还会被使用,所以GC不会清理;
0代中,有些数据对象实例会被GC清理,有些数据实例对象未被GC清理,那么,未被GC清理的数据对象实例,我们称它为幸存者。
此时,0代中的幸存者会被转移到1代中(想想上面提到1代存放的是哪类对象实例...);
那么,以此类推,长期/处处被使用的对象实例,就会从1代中转移到2代中;
因此,2代中存放的通常为静态或全局作用域或长期被使用到的对象实例。
六、GC是如何去确定要清理的对象实例?
GC在堆中生成各对象间的结构图,作为回收对象的依据,找出非活动的对象。
所有数据对象实例之间的关联引用关系,都会生成一个完整的结构图,一些不在结构图中的 或超出所在作用域的 或不再被继续使用的对象实例,被称为非活动对象。被视为GC要清理的对象。
准确的说:
七、手动GC垃圾回收
在某些不常见的情况下,强制回收可提高应用程序的性能。在此,可使用 GC.Collect 方法强制执行垃圾回收,从而诱导垃圾回收。
注意,是诱导,而不是即刻回收。
为了考虑到应用程序当前的稳定运行,执行GC.Collect并不一定马上产生效果,这里仅仅是一个触发,会去收集将要回收的对象,回收动作会在未来某个合适的时间段进行。(当然,也可以强制阻塞式回收,这里略过)
(思考一下:无用的实例=null,是否告知GC为可回收的对象?再GC.Collect()后的效果。)
关于 GC.Collect 方法的参数,会用到上面提到的概念及场景:
- 对指定的代进行回收
- 指定回收次数
- 强制回收 或 择机回收
- 阻塞式回收 或 后台线程回收
- 压缩 或 清理
(阻塞式回收方式:都先停一停,先让我回收完)
当然,通常建议:0代,择机,后台回收(阻塞式风险太大,通常选择择机方式,具体自我考量)
八、内存堆中的弱引用
当应用程序正在执行使用的对象,GC是不可能回收的,那么,就认为应用程序对该对象具有强引用。
强引用:应用程序正在使用的对象实例,不能被GC回收。
弱引用:应用程序暂时没使用的对象实例,暂时可被GC定义为可回收的实例,在回收之前,也可被应用程序再次使用后变为强引用。
假设一个对象实例被GC清理后,后续又被再次用到的场景,就会重新创建对象实例,那如果这个对象实例又比较大,这样的频繁创建... ...
当然还有优化的空间,所以,弱引用优化了以上场景。
弱引用的优点:对于频繁创建的大实例,弱类型可以做到一次创建多次使用,避免大对象实例多次创建的性能消耗。
(对于小对象使用弱类型,所带来的对对象管理上的性能消耗,是否值得)
若要对某对象建立弱引用,使用要跟踪的对象实例创建 WeakReference。 然后将 Target 属性设置为该对象,将该对象的原始引用设置为 null。(参考官方文档)
也就是说:我们可以自定义控制哪些对象实例要不要暂时不被GC垃圾回收。
九、多应用共享内存时的垃圾回收
当多个应用程序在一台主机同时运行时,对内存空间大小的分配,建议是灵活可变的,以达到各应用程序对内存利用的平衡及稳定性。
如果启用 gcTrimCommitOnLowMemory 设置,垃圾回收器会计算系统内存负载,并在负载达到 90% 时进入修整模式。除非负载下降到不到 85%,否则会一直处于修整模式。
如果条件允许,垃圾回收器可以决定 gcTrimCommitOnLowMemory 设置对当前应用没有帮助并忽略它。
如下启用 gcTrimCommitOnLowMemory 设置
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<runtime>
<gcTrimCommitOnLowMemory enabled="true"/>
</runtime>
</configuration>
/
C#垃圾回收机制
CLR:公共运行时环境,管理托管堆。
CTR:设置引用类型,值类型。
GC:只负责回收托管对象,不负责回收非托管对象。
垃圾回收器的基本假定:
1.被分配内存空间的对象最有可能被释放。在方法执行时,就需要为该方法的对象分配内存空间,搜索最近分配的对象集合有助于花费最少的代价来尽可能多地释放内存空间。
2.生命期最长的对象释放的可能性最小,经过几轮垃圾回收后,对象仍然存在,搜索它时就需要进行大量的工作,却只能释放很小的一部分空间。
3.同时被分配内存的对象通常是同时使用,将它们彼此相连有助于提高缓存性能和回收效率。
C#中的回收器是分代的垃圾回收器(Gererational GarbageCollector) 它将分配的对象分为3个类别或代。(可用GC.GetGeneration方法返回任意作为参数的对象当前所处的代)最近被分配内存的对象被放置于第0代,因为第0代很小,小到足以放进处理器的二级(L2)缓存,所以它能够提供对对象的快速存取。经过一轮垃圾回收后,仍然保留在第0代中的对象被移进第1代中,再经过一轮垃圾内存回收后,仍然保留在第1代中的对象则被移进第2代中,第2代中包含了生存期较长的对象。
在C#中值类型是在堆栈中分配内存,它们有自身的生命周期,所以不用对它们进行管理,会自动分配和释放。而引用类型是在堆中分配内存的。所以它的分配和释放就需要像回收机制来管理。C#为一个对象分配内存时,托管堆可以立即返回新对象所需的内存,因为托管堆类似于简单的字节数组,有一个指向第一个可用内存空间的指针,指针像游标一样向后移动,一段段内存就分配给了正在运行的程序的对象。在不需要太多垃圾回收的程序小,托管堆性能优于传统的堆。
当第0代中没有可以分配的有效内存时,就触发了第0代中的一轮垃圾回收,它将删除那些不再被引用的对象,并将当前正在使用的对象移至第1代。而当第0代垃圾回收后依然不能请求到充足的内存时,就启动第1代垃圾回收。如果对各代都进行了垃圾回收后仍没有可用的内存就会引发一个OutOfMemoryException异常。
Public class BaseResource:IDisposable
{
PrivateIntPtr handle; // 句柄,属于非托管资源
PrivateComponet comp; // 组件,托管资源
PrivatebooisDisposed = false; //是否已释放资源的标志
PublicBaseResource
{
}
//实现接口方法
//由类的使用者,在外部显示调用,释放类资源
Public void Dispose()
{
Dispose(true);// 释放托管和非托管资源
//将对象从垃圾回收器链表中移除,
// 从而在垃圾回收器工作时,只释放托管资源,而不执行此对象的析构函数
GC.SuppressFinalize(this);
}
//由垃圾回收器调用,释放非托管资源
~BaseResource()
{
Dispose(false);// 释放非托管资源
}
//参数为true表示释放所有资源,只能由使用者调用
//参数为false表示释放非托管资源,只能由垃圾回收器自动调用
//如果子类有自己的非托管资源,可以重载这个函数,添加自己的非托管资源的释放
//但是要记住,重载此函数必须保证调用基类的版本,以保证基类的资源正常释放
Protectedvirtual void Dispose(bool disposing)
{
If(!this.disposed)// 如果资源未释放 这个判断主要用了防止对象被多次释放
{
If(disposing)
{
Comp.Dispose();// 释放托管资源
}
closeHandle(handle);// 释放非托管资源
handle= IntPtr.Zero;
}
this.disposed= true; // 标识此对象已释放
}
}
在垃圾回收时尽量避免使用finallize来回收资源,这样会造成两车垃圾回收,影响效率
垃圾回收器使用名为“终止队列”的内部结构跟踪具有 Finalize 方法的对象。每次您的应用程序创建具有 Finalize 方法的对象时,垃圾回收器都在终止队列中放置一个指向该对象的项。托管堆中所有需要在垃圾回收器回收其内存之前调用它们的终止代码的对象都在终止队列中含有项。(实现 Finalize 方法或析构函数对性能可能会有负面影响,因此应避免不必要地使用它们。用 Finalize 方法回收对象使用的内存需要至少两次垃圾回收。当垃圾回收器执行回收时,它只回收没有终结器的不可访问对象的内存。这时,它不能回收具有终结器的不可访问对象。它改为将这些对象的项从终止队列中移除并将它们放置在标为准备终止的对象列表中。该列表中的项指向托管堆中准备被调用其终止代码的对象。垃圾回收器为此列表中的对象调用 Finalize 方法,然后,将这些项从列表中移除。后来的垃圾回收将确定终止的对象确实是垃圾,因为标为准备终止对象的列表中的项不再指向它们。在后来的垃圾回收中,实际上回收了对象的内存。
//
root为
全局变量的引用
静态对象的引用
对所有对象检查。判断应用程序是否可以访问,即是否有活动根
第0带 从未被标记为回收的新分配对象
第1带 上一次垃圾回收未被标记
第2代 一次以上垃圾回收未被标记
不是单纯的引用计数
而是标记。从root出发。找到所有reachable object(被引用了的对象)。标记。释放。重新整理地址连续
引用计数对于闭环 a->b->c->d->a 是无法回收
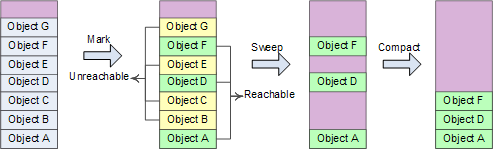
Mark-Compact 标记压缩算法
阶段1: Mark-Sweep 标记清除阶段,先假设heap中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,最后heap中没有打标记的对象都是可以被回收的;阶段2: Compact 压缩阶段,对象回收之后heap内存空间变得不连续,在heap中移动这些对象,使他们重新从heap基地址开始连续排列,类似于磁盘空间的碎片整理。
Heap内存经过回收、压缩之后,可以继续采用前面的heap内存分配方法,即仅用一个指针记录heap分配的起始地址就可以。主要处理步骤:将线程挂起→确定roots→创建reachable objects graph→对象回收→heap压缩→指针修复。可以这样理解roots:heap中对象的引用关系错综复杂(交叉引用、循环引用),形成复杂的graph,roots是CLR在heap之外可以找到的各种入口点。
GC搜索roots的地方包括全局对象、静态变量、局部对象、函数调用参数、当前CPU寄存器中的对象指针(还有finalization queue)等。主要可以归为2种类型:已经初始化了的静态变量、线程仍在使用的对象(stack+CPU register) 。 Reachable objects:指根据对象引用关系,从roots出发可以到达的对象。例如当前执行函数的局部变量对象A是一个root object,他的成员变量引用了对象B,则B是一个reachable object。从roots出发可以创建reachable objects graph,剩余对象即为unreachable,可以被回收 。
GC的前世与今生
虽然本文是以.NET作为目标来讲述GC,但是GC的概念并非才诞生不久。早在1958年,由鼎鼎大名的图林奖得主John McCarthy所实现的Lisp语言就已经提供了GC的功能,这是GC的第一次出现。Lisp的程序员认为内存管理太重要了,所以不能由程序员自己来管理。
但后来的日子里Lisp却没有成气候,采用内存手动管理的语言占据了上风,以C为代表。出于同样的理由,不同的人却又不同的看法,C程序员认为内存管理太重要了,所以不能由系统来管理,并且讥笑Lisp程序慢如乌龟的运行速度。的确,在那个对每一个Byte都要精心计算的年代GC的速度和对系统资源的大量占用使很多人的无法接受。而后,1984年由Dave Ungar开发的Smalltalk语言第一次采用了Generational garbage collection的技术(这个技术在下文中会谈到),但是Smalltalk也没有得到十分广泛的应用。
直到20世纪90年代中期GC才以主角的身份登上了历史的舞台,这不得不归功于Java的进步,今日的GC已非吴下阿蒙。Java采用VM(Virtual Machine)机制,由VM来管理程序的运行当然也包括对GC管理。90年代末期.NET出现了,.NET采用了和Java类似的方法由CLR(Common Language Runtime)来管理。这两大阵营的出现将人们引入了以虚拟平台为基础的开发时代,GC也在这个时候越来越得到大众的关注。
为什么要使用GC呢?也可以说是为什么要使用内存自动管理?有下面的几个原因:
1、提高了软件开发的抽象度;
2、程序员可以将精力集中在实际的问题上而不用分心来管理内存的问题;
3、可以使模块的接口更加的清晰,减小模块间的偶合;
4、大大减少了内存人为管理不当所带来的Bug;
5、使内存管理更加高效。
总的说来就是GC可以使程序员可以从复杂的内存问题中摆脱出来,从而提高了软件开发的速度、质量和安全性。
什么是GC
GC如其名,就是垃圾收集,当然这里仅就内存而言。Garbage Collector(垃圾收集器,在不至于混淆的情况下也成为GC)以应用程序的root为基础,遍历应用程序在Heap上动态分配的所有对象[2],通过识别它们是否被引用来确定哪些对象是已经死亡的、哪些仍需要被使用。已经不再被应用程序的root或者别的对象所引用的对象就是已经死亡的对象,即所谓的垃圾,需要被回收。这就是GC工作的原理。为了实现这个原理,GC有多种算法。比较常见的算法有Reference Counting,Mark Sweep,Copy Collection等等。目前主流的虚拟系统.NET CLR,Java VM和Rotor都是采用的Mark Sweep算法。
一、Mark-Compact 标记压缩算法
简单地把.NET的GC算法看作Mark-Compact算法。阶段1: Mark-Sweep 标记清除阶段,先假设heap中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,最后heap中没有打标记的对象都是可以被回收的;阶段2: Compact 压缩阶段,对象回收之后heap内存空间变得不连续,在heap中移动这些对象,使他们重新从heap基地址开始连续排列,类似于磁盘空间的碎片整理。
Heap内存经过回收、压缩之后,可以继续采用前面的heap内存分配方法,即仅用一个指针记录heap分配的起始地址就可以。主要处理步骤:将线程挂起→确定roots→创建reachable objects graph→对象回收→heap压缩→指针修复。可以这样理解roots:heap中对象的引用关系错综复杂(交叉引用、循环引用),形成复杂的graph,roots是CLR在heap之外可以找到的各种入口点。
GC搜索roots的地方包括全局对象、静态变量、局部对象、函数调用参数、当前CPU寄存器中的对象指针(还有finalization queue)等。主要可以归为2种类型:已经初始化了的静态变量、线程仍在使用的对象(stack+CPU register) 。 Reachable objects:指根据对象引用关系,从roots出发可以到达的对象。例如当前执行函数的局部变量对象A是一个root object,他的成员变量引用了对象B,则B是一个reachable object。从roots出发可以创建reachable objects graph,剩余对象即为unreachable,可以被回收 。

指针修复是因为compact过程移动了heap对象,对象地址发生变化,需要修复所有引用指针,包括stack、CPU register中的指针以及heap中其他对象的引用指针。Debug和release执行模式之间稍有区别,release模式下后续代码没有引用的对象是unreachable的,而debug模式下需要等到当前函数执行完毕,这些对象才会成为unreachable,目的是为了调试时跟踪局部对象的内容。传给了COM+的托管对象也会成为root,并且具有一个引用计数器以兼容COM+的内存管理机制,引用计数器为0时,这些对象才可能成为被回收对象。Pinned objects指分配之后不能移动位置的对象,例如传递给非托管代码的对象(或者使用了fixed关键字),GC在指针修复时无法修改非托管代码中的引用指针,因此将这些对象移动将发生异常。pinned objects会导致heap出现碎片,但大部分情况来说传给非托管代码的对象应当在GC时能够被回收掉。
二、 Generational 分代算法
程序可能使用几百M、几G的内存,对这样的内存区域进行GC操作成本很高,分代算法具备一定统计学基础,对GC的性能改善效果比较明显。将对象按照生命周期分成新的、老的,根据统计分布规律所反映的结果,可以对新、老区域采用不同的回收策略和算法,加强对新区域的回收处理力度,争取在较短时间间隔、较小的内存区域内,以较低成本将执行路径上大量新近抛弃不再使用的局部对象及时回收掉。分代算法的假设前提条件:
1、大量新创建的对象生命周期都比较短,而较老的对象生命周期会更长;
2、对部分内存进行回收比基于全部内存的回收操作要快;
3、新创建的对象之间关联程度通常较强。heap分配的对象是连续的,关联度较强有利于提高CPU cache的命中率,.NET将heap分成3个代龄区域: Gen 0、Gen 1、Gen 2;
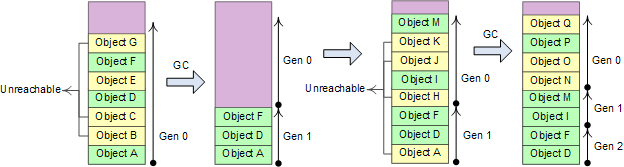
Heap分为3个代龄区域,相应的GC有3种方式: # Gen 0 collections, # Gen 1 collections, #Gen 2 collections。如果Gen 0 heap内存达到阀值,则触发0代GC,0代GC后Gen 0中幸存的对象进入Gen1。如果Gen 1的内存达到阀值,则进行1代GC,1代GC将Gen 0 heap和Gen 1 heap一起进行回收,幸存的对象进入Gen2。
2代GC将Gen 0 heap、Gen 1 heap和Gen 2 heap一起回收,Gen 0和Gen 1比较小,这两个代龄加起来总是保持在16M左右;Gen2的大小由应用程序确定,可能达到几G,因此0代和1代GC的成本非常低,2代GC称为full GC,通常成本很高。粗略的计算0代和1代GC应当能在几毫秒到几十毫秒之间完成,Gen 2 heap比较大时,full GC可能需要花费几秒时间。大致上来讲.NET应用运行期间,2代、1代和0代GC的频率应当大致为1:10:100。
三、Finalization Queue和Freachable Queue
这两个队列和.NET对象所提供的Finalize方法有关。这两个队列并不用于存储真正的对象,而是存储一组指向对象的指针。当程序中使用了new操作符在Managed Heap上分配空间时,GC会对其进行分析,如果该对象含有Finalize方法则在Finalization Queue中添加一个指向该对象的指针。
在GC被启动以后,经过Mark阶段分辨出哪些是垃圾。再在垃圾中搜索,如果发现垃圾中有被Finalization Queue中的指针所指向的对象,则将这个对象从垃圾中分离出来,并将指向它的指针移动到Freachable Queue中。这个过程被称为是对象的复生(Resurrection),本来死去的对象就这样被救活了。为什么要救活它呢?因为这个对象的Finalize方法还没有被执行,所以不能让它死去。Freachable Queue平时不做什么事,但是一旦里面被添加了指针之后,它就会去触发所指对象的Finalize方法执行,之后将这个指针从队列中剔除,这是对象就可以安静的死去了。
.NET Framework的System.GC类提供了控制Finalize的两个方法,ReRegisterForFinalize和SuppressFinalize。前者是请求系统完成对象的Finalize方法,后者是请求系统不要完成对象的Finalize方法。ReRegisterForFinalize方法其实就是将指向对象的指针重新添加到Finalization Queue中。这就出现了一个很有趣的现象,因为在Finalization Queue中的对象可以复生,如果在对象的Finalize方法中调用ReRegisterForFinalize方法,这样就形成了一个在堆上永远不会死去的对象,像凤凰涅槃一样每次死的时候都可以复生。
托管资源:
.NET中的所有类型都是(直接或间接)从System.Object类型派生的。
CTS中的类型被分成两大类——引用类型(reference type,又叫托管类型[managed type]),分配在内存堆上;值类型(value type),分配在堆栈上。如图:
值类型在栈里,先进后出,值类型变量的生命有先后顺序,这个确保了值类型变量在退出作用域以前会释放资源。比引用类型更简单和高效。堆栈是从高地址往低地址分配内存。
引用类型分配在托管堆(Managed Heap)上,声明一个变量在栈上保存,当使用new创建对象时,会把对象的地址存储在这个变量里。托管堆相反,从低地址往高地址分配内存,如图:
.NET中超过80%的资源都是托管资源。
非托管资源:
ApplicationContext, Brush, Component, ComponentDesigner, Container, Context, Cursor, FileStream, Font, Icon, Image, Matrix, Object, OdbcDataReader, OleDBDataReader, Pen, Regex, Socket, StreamWriter, Timer, Tooltip, 文件句柄, GDI资源, 数据库连接等等资源。可能在使用的时候很多都没有注意到!
.NET的GC机制有这样两个问题:
首先,GC并不是能释放所有的资源。它不能自动释放非托管资源。
第二,GC并不是实时性的,这将会造成系统性能上的瓶颈和不确定性。
GC并不是实时性的,这会造成系统性能上的瓶颈和不确定性。所以有了IDisposable接口,IDisposable接口定义了Dispose方法,这个方法用来供程序员显式调用以释放非托管资源。使用using语句可以简化资源管理。
示例:
///summary
/// 执行SQL语句,返回影响的记录数
summary
///param name="SQLString"SQL语句/param
///returns影响的记录数/returns
publicstaticint ExecuteSql(string SQLString)
{
using (SqlConnection connection =new SqlConnection(connectionString))
{
using (SqlCommand cmd =new SqlCommand(SQLString, connection))
{
try
{
connection.Open();
int rows = cmd.ExecuteNonQuery();
return rows;
}
catch (System.Data.SqlClient.SqlException e)
{
connection.Close();
throw e;
}
finally
{
cmd.Dispose();
connection.Close();
}
}
}
}
当你用Dispose方法释放未托管对象的时候,应该调用GC.SuppressFinalize。如果对象正在终结队列(finalization queue), GC.SuppressFinalize会阻止GC调用Finalize方法。因为Finalize方法的调用会牺牲部分性能。如果你的Dispose方法已经对委托管资源作了清理,就没必要让GC再调用对象的Finalize方法(MSDN)。附上MSDN的代码,大家可以参考。
publicclass BaseResource : IDisposable
{
// 指向外部非托管资源
private IntPtr handle;
// 此类使用的其它托管资源.
private Component Components;
// 跟踪是否调用.Dispose方法,标识位,控制垃圾收集器的行为
privatebool disposed =false;
// 构造函数
public BaseResource()
{
// Insert appropriate constructor code here.
}
// 实现接口IDisposable.
// 不能声明为虚方法virtual.
// 子类不能重写这个方法.
publicvoid Dispose()
{
Dispose(true);
// 离开终结队列Finalization queue
// 设置对象的阻止终结器代码
//
GC.SuppressFinalize(this);
}
// Dispose(bool disposing) 执行分两种不同的情况.
// 如果disposing 等于 true, 方法已经被调用
// 或者间接被用户代码调用. 托管和非托管的代码都能被释放
// 如果disposing 等于false, 方法已经被终结器 finalizer 从内部调用过,
//你就不能在引用其他对象,只有非托管资源可以被释放。
protectedvirtualvoid Dispose(bool disposing)
{
// 检查Dispose 是否被调用过.
if (!this.disposed)
{
// 如果等于true, 释放所有托管和非托管资源
if (disposing)
{
// 释放托管资源.
Components.Dispose();
}
// 释放非托管资源,如果disposing为 false,
// 只会执行下面的代码.
CloseHandle(handle);
handle = IntPtr.Zero;
// 注意这里是非线程安全的.
// 在托管资源释放以后可以启动其它线程销毁对象,
// 但是在disposed标记设置为true前
// 如果线程安全是必须的,客户端必须实现。
}
disposed =true;
}
// 使用interop 调用方法
// 清除非托管资源.
[System.Runtime.InteropServices.DllImport("Kernel32")]
privateexternstatic Boolean CloseHandle(IntPtr handle);
// 使用C# 析构函数来实现终结器代码
// 这个只在Dispose方法没被调用的前提下,才能调用执行。
// 如果你给基类终结的机会.
// 不要给子类提供析构函数.
~BaseResource()
{
// 不要重复创建清理的代码.
// 基于可靠性和可维护性考虑,调用Dispose(false) 是最佳的方式
Dispose(false);
}
// 允许你多次调用Dispose方法,
// 但是会抛出异常如果对象已经释放。
// 不论你什么时间处理对象都会核查对象的是否释放,
// check to see if it has been disposed.
publicvoid DoSomething()
{
if (this.disposed)
{
thrownew ObjectDisposedException();
}
}
// 不要设置方法为virtual.
// 继承类不允许重写这个方法
publicvoid Close()
{
// 无参数调用Dispose参数.
Dispose();
}
publicstaticvoid Main()
{
// Insert code here to create
// and use a BaseResource object.
}
}
GC.Collect() 方法
作用:强制进行垃圾回收。
GC的方法:
| 名称 |
说明 |
| Collect() |
强制对所有代进行即时垃圾回收。 |
| Collect(Int32) |
强制对零代到指定代进行即时垃圾回收。 |
| Collect(Int32, GCCollectionMode) |
强制在 GCCollectionMode 值所指定的时间对零代到指定代进行垃圾回收 |
GC注意事项:
1、只管理内存,非托管资源,如文件句柄,GDI资源,数据库连接等还需要用户去管理。
2、循环引用,网状结构等的实现会变得简单。GC的标志-压缩算法能有效的检测这些关系,并将不再被引用的网状结构整体删除。
3、GC通过从程序的根对象开始遍历来检测一个对象是否可被其他对象访问,而不是用类似于COM中的引用计数方法。
4、GC在一个独立的线程中运行来删除不再被引用的内存。
5、GC每次运行时会压缩托管堆。
6、你必须对非托管资源的释放负责。可以通过在类型中定义Finalizer来保证资源得到释放。
7、对象的Finalizer被执行的时间是在对象不再被引用后的某个不确定的时间。注意并非和C++中一样在对象超出声明周期时立即执行析构函数
8、Finalizer的使用有性能上的代价。需要Finalization的对象不会立即被清除,而需要先执行Finalizer.Finalizer,不是在GC执行的线程被调用。GC把每一个需要执行Finalizer的对象放到一个队列中去,然后启动另一个线程来执行所有这些Finalizer,而GC线程继续去删除其他待回收的对象。在下一个GC周期,这些执行完Finalizer的对象的内存才会被回收。
9、.NET GC使用"代"(generations)的概念来优化性能。代帮助GC更迅速的识别那些最可能成为垃圾的对象。在上次执行完垃圾回收后新创建的对象为第0代对象。经历了一次GC周期的对象为第1代对象。经历了两次或更多的GC周期的对象为第2代对象。代的作用是为了区分局部变量和需要在应用程序生存周期中一直存活的对象。大部分第0代对象是局部变量。成员变量和全局变量很快变成第1代对象并最终成为第2代对象。
10、GC对不同代的对象执行不同的检查策略以优化性能。每个GC周期都会检查第0代对象。大约1/10的GC周期检查第0代和第1代对象。大约1/100的GC周期检查所有的对象。重新思考Finalization的代价:需要Finalization的对象可能比不需要Finalization在内存中停留额外9个GC周期。如果此时它还没有被Finalize,就变成第2代对象,从而在内存中停留更长时间。
//
//