一、文章出发点
每个像素点的类别(label)应该是它所属目标(object)的类别。
所以这篇文章对像素的上下文信息建模
建模方法:求每个像素点和每个类别的相关性
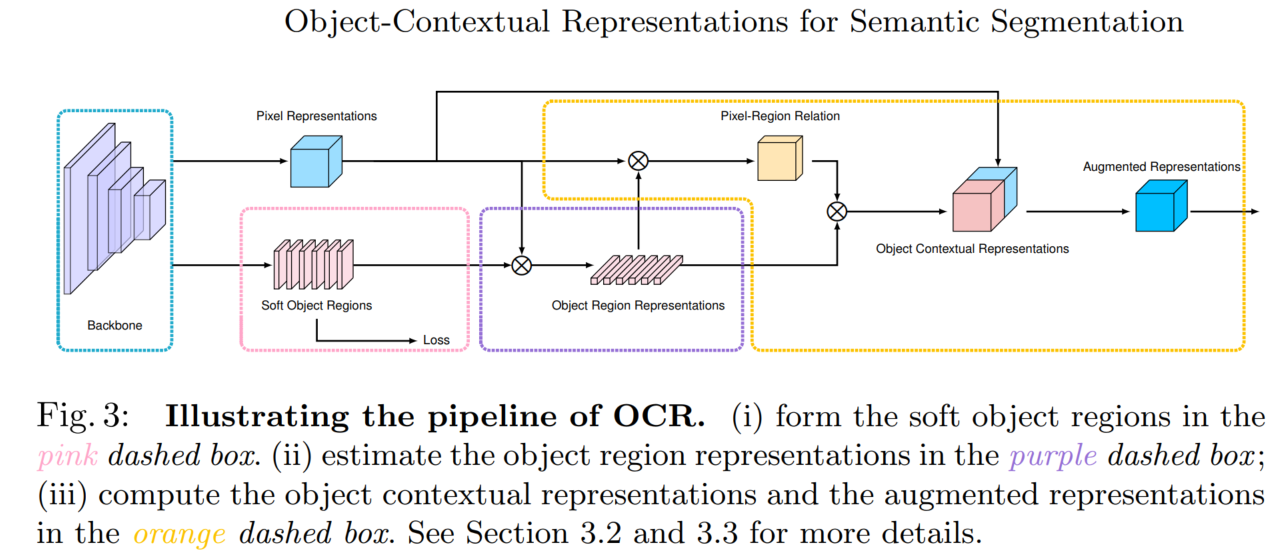
二、方法
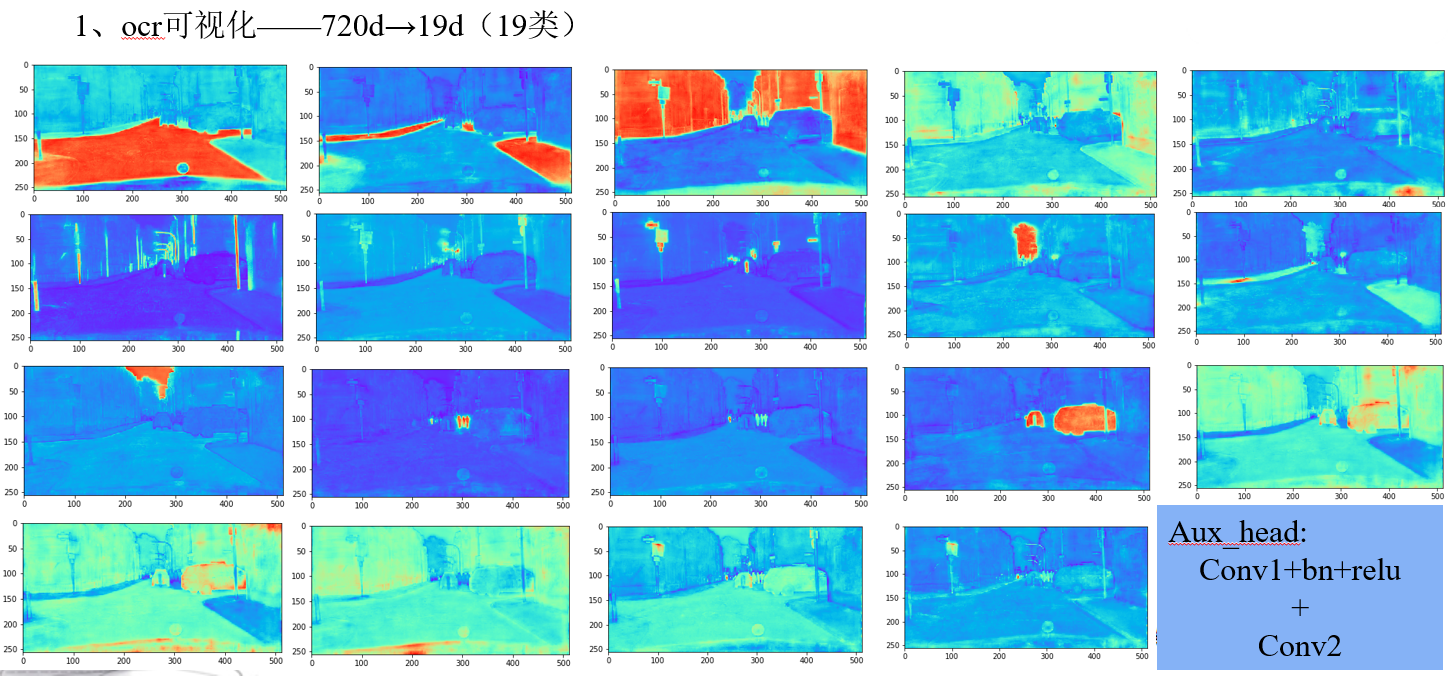
方法(以 cityscapes 19类为例):这里最终的加权可以看做是像素和类别之间的加权
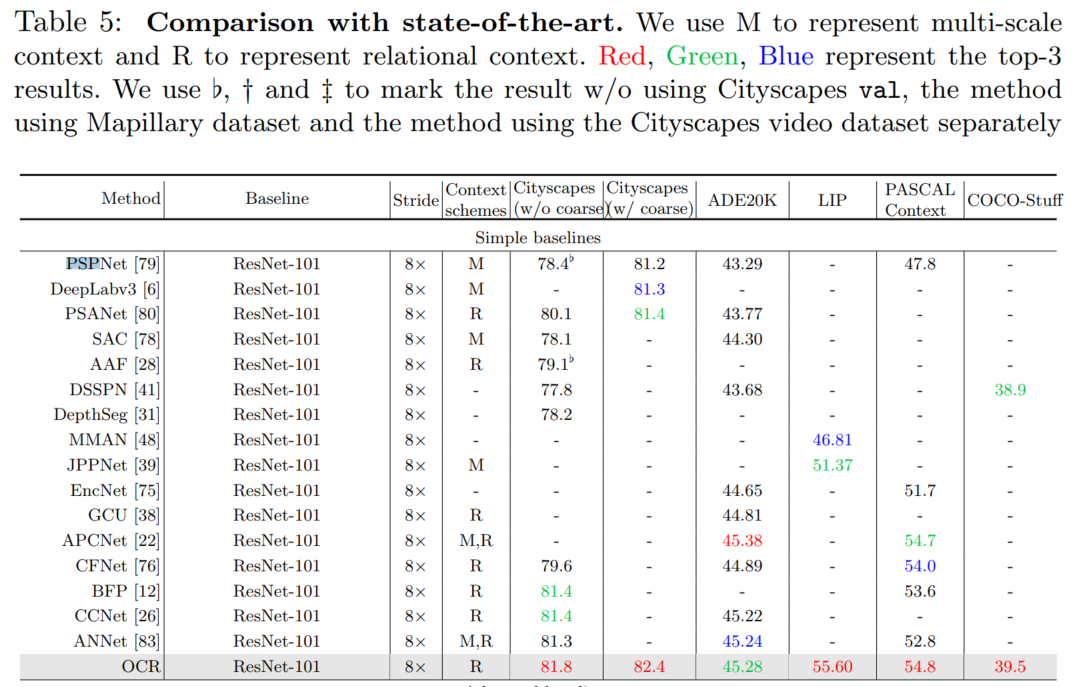
- 首先,得到普通的初始分割结果(19类)
- 然后,计算每个特征图(512)和初始分割结果(19)的相关性,得到 512x19 的矩阵
- 之后,用该 512x19 的矩阵,对特征图(512)加权,得到加权后的特征图
- 最后,对加权后的特征图进行特征抽取,得到加权后的最终分割结果(19类)

# prev_output: 19d的粗糙预测结果
# feats:将hrnet输出的720d的变成512d
# context:每个类别图和每个特征图的关系(19x512)
# object_context:self-attention
1、prev_output:
2、feats获得

3、context获得

4、self-attention

import torch
import torch.nn as nn
import torch.nn.functional as F
from mmcv.cnn import ConvModule
from mmseg.ops import resize
from ..builder import HEADS
from ..utils import SelfAttentionBlock as _SelfAttentionBlock
from .cascade_decode_head import BaseCascadeDecodeHead
# from .Attention_layer import HardClassAttention as HCA
class SpatialGatherModule(nn.Module):
"""Aggregate the context features according to the initial predicted
probability distribution.
Employ the soft-weighted method to aggregate the context.
"""
def __init__(self, scale):
super(SpatialGatherModule, self).__init__()
self.scale = scale
def forward(self, feats, probs):
"""Forward function."""
batch_size, num_classes, height, width = probs.size()
channels = feats.size(1)
probs = probs.view(batch_size, num_classes, -1)
feats = feats.view(batch_size, channels, -1)
# [batch_size, height*width, num_classes]
feats = feats.permute(0, 2, 1)
# [batch_size, channels, height*width]
probs = F.softmax(self.scale * probs, dim=2)
# [batch_size, channels, num_classes]
ocr_context = torch.matmul(probs, feats)
ocr_context = ocr_context.permute(0, 2, 1).contiguous().unsqueeze(3)
return ocr_context
class ClassRelationGatherModule(nn.Module):
"""Aggregate the context features according to the initial predicted
probability distribution.
Employ the soft-weighted method to aggregate the context.
"""
def __init__(self, scale):
super(ClassRelationGatherModule, self).__init__()
self.scale = scale
def forward(self, feats, probs):
"""Forward function."""
batch_size, num_classes, height, width = probs.size()
channels = feats.size(1)
probs_1 = probs.view(batch_size, num_classes, -1)
probs_2 = probs.view(batch_size, num_classes, -1)
# [batch_size, height*width, num_classes]
probs_2 = probs_2.permute(0, 2, 1)
# [batch_size, channels, height*width]
probs_1 = F.softmax(self.scale * probs_1, dim=2)
# [batch_size, channels, num_classes]
class_gather = torch.matmul(probs_1, probs_2)
class_gather = class_gather.permute(0, 2, 1).contiguous().unsqueeze(3)
return class_gather
class ObjectAttentionBlock(_SelfAttentionBlock):
"""Make a OCR used SelfAttentionBlock."""
def __init__(self, in_channels, channels, scale, conv_cfg, norm_cfg,
act_cfg):
if scale > 1:
query_downsample = nn.MaxPool2d(kernel_size=scale)
else:
query_downsample = None
super(ObjectAttentionBlock, self).__init__(
key_in_channels=in_channels,
query_in_channels=in_channels,
channels=channels,
out_channels=in_channels,
share_key_query=False,
query_downsample=query_downsample,
key_downsample=None,
key_query_num_convs=2,
key_query_norm=True,
value_out_num_convs=1,
value_out_norm=True,
matmul_norm=True,
with_out=True,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.bottleneck = ConvModule(
in_channels * 2,
in_channels,
1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def forward(self, query_feats, key_feats):
"""Forward function."""
context = super(ObjectAttentionBlock, self).forward(query_feats, key_feats)
output = self.bottleneck(torch.cat([context, query_feats], dim=1))
if self.query_downsample is not None:
output = resize(query_feats)
return output
@HEADS.register_module()
class OCRHead(BaseCascadeDecodeHead):
"""Object-Contextual Representations for Semantic Segmentation.
This head is the implementation of `OCRNet
<https://arxiv.org/abs/1909.11065>`_.
Args:
ocr_channels (int): The intermediate channels of OCR block.
scale (int): The scale of probability map in SpatialGatherModule in
Default: 1.
"""
def __init__(self, ocr_channels, scale=1, **kwargs):
super(OCRHead, self).__init__(**kwargs)
self.ocr_channels = ocr_channels
self.scale = scale
self.object_context_block = ObjectAttentionBlock(
self.channels,
self.ocr_channels,
self.scale,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
self.spatial_gather_module = SpatialGatherModule(self.scale)
self.class_relation_gather_module = ClassRelationGatherModule(self.scale)
self.bottleneck = ConvModule(
self.in_channels,
self.channels,
3,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def forward(self, inputs, prev_output):
"""Forward function."""
# concat multi-level img feature
x = self._transform_inputs(inputs) # (1,720,128,256) hr18, 512x1024
feats = self.bottleneck(x) # (1,512,128,256)
context = self.spatial_gather_module(feats, prev_output) # (1,512,19,1)
object_context = self.object_context_block(feats, context) #(1,512,128,256)
output = self.cls_seg(object_context) # (1,19,128,256)
return output
三、效果
经过OCR头后的效果对比如下图,每个类别的响应比较全面且稳定。
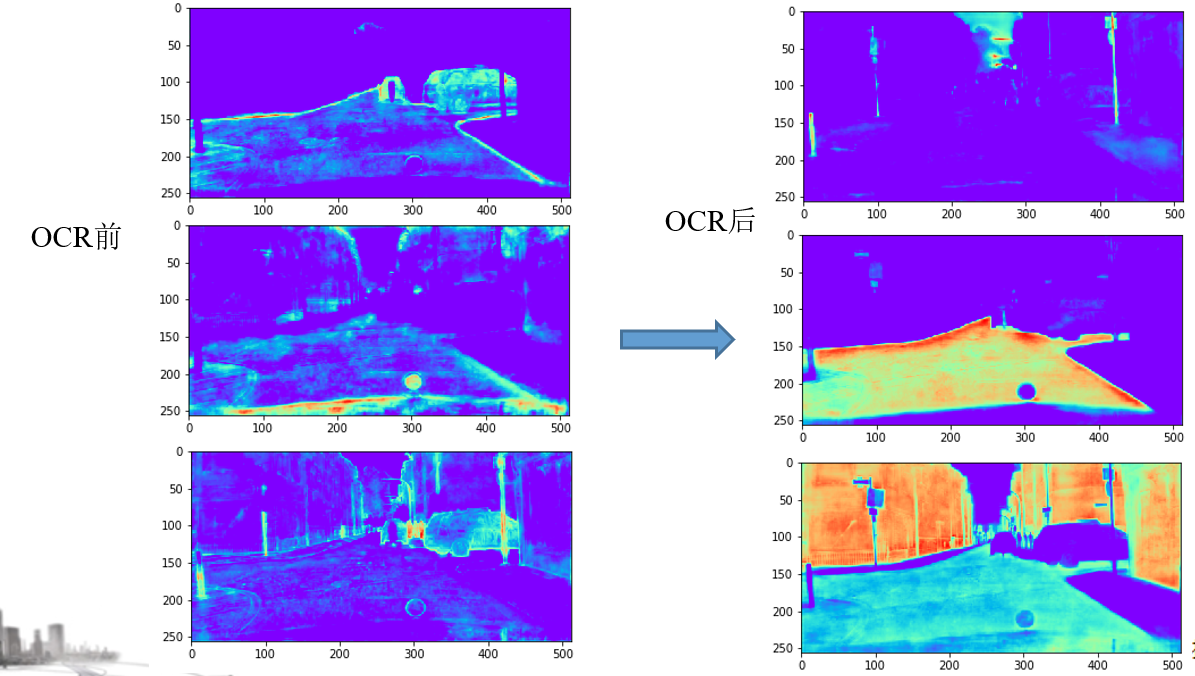
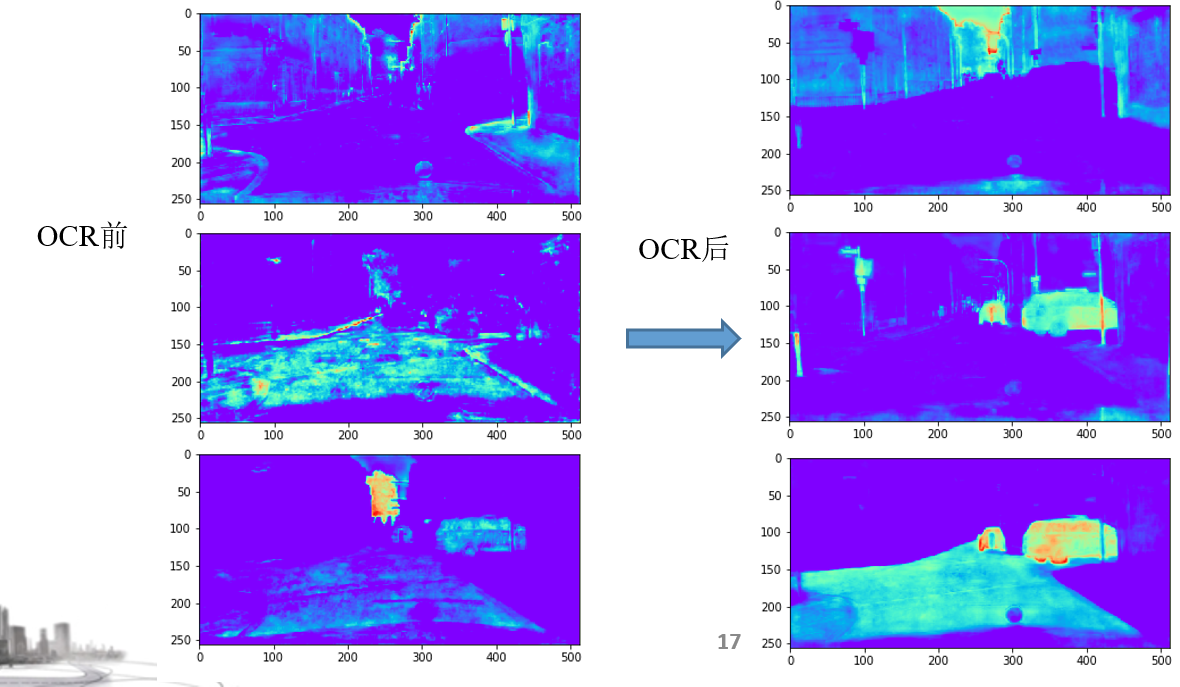
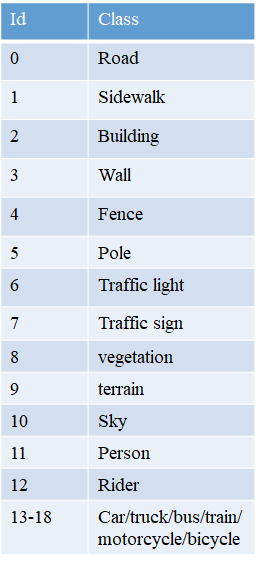
cityscape类别和通道的对应: