主机与设备之间的同步,分为隐式和显式。
一.隐式:cudaMemcpy函数的作用在于传输传输,但在执行结束之前会产生阻塞。许多与内存相关的操作都会产生阻塞,这些不必要的阻塞会对性能产生较大的影响。如:锁页主机内存分配,设备内存分配,设备内存初始化,同一设备间的内存复制,一级缓存和共享存储配置的修改等等。
二.显式:下面三种函数均可实现主机与设备间的同步。
cudaDeviceSynchronize()-设备同步:
使主机线程等待和当前设备相关的计算和通信完成。尽量少用,避免拖延主机执行。
cudaStreamSynchronize()-流同步:
可以阻塞主机知道流中的操作全部完成为止。cudaStreamQuery可以查询流的执行状态,检测是否全部完成。
cudaEventSynchronize()-事件同步.
事件同步和流同步基本一致,可实现细粒度的阻塞和同步。。cudaEvnetQuery可以查询事件的执行状态,检测是否全部完成。
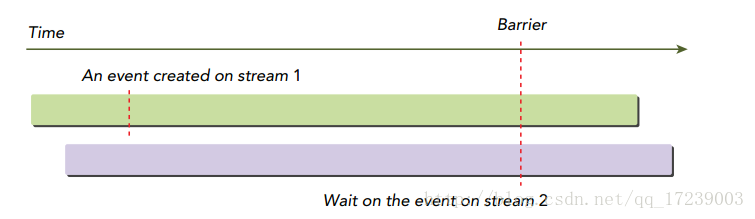
此外:cudaStreamWaitEvent()可使得指定流等待指定事件,用于处理流间的依赖关系。如图所示,在跨流之间,流2发布的等待可以确保流1创建的事件是满足依赖关系的,然后继续执行。