一、问题与数据
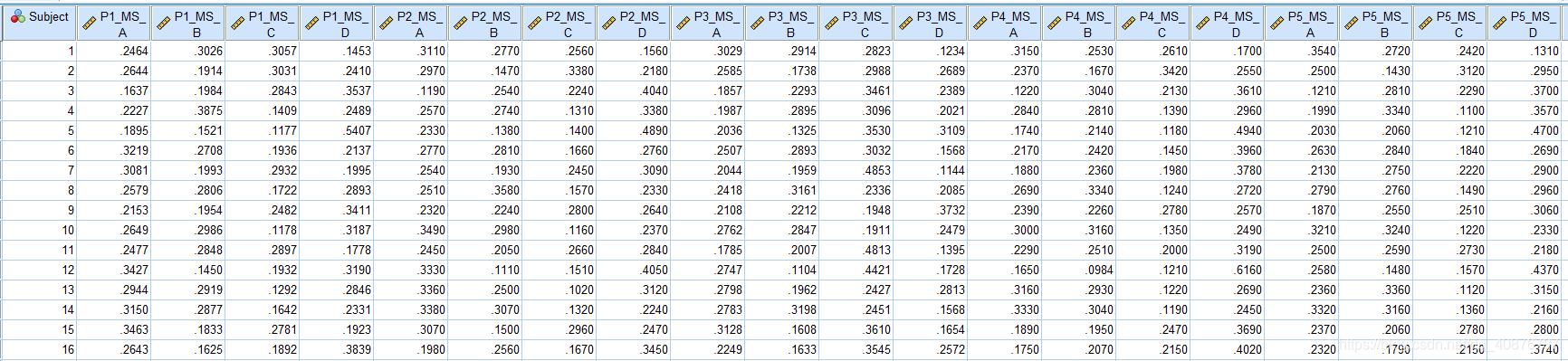
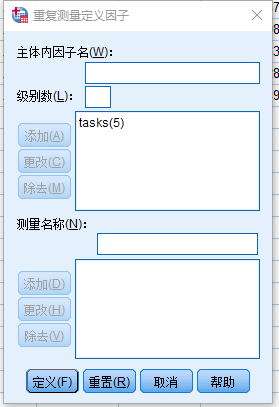
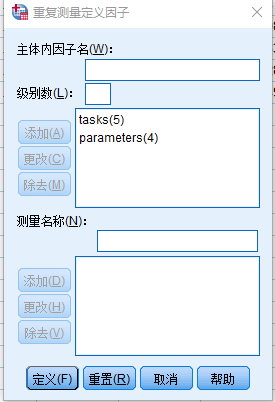
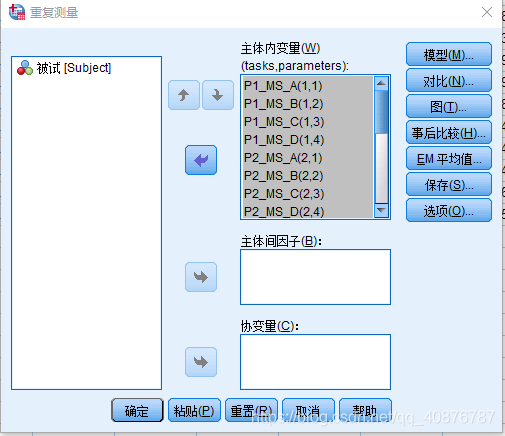
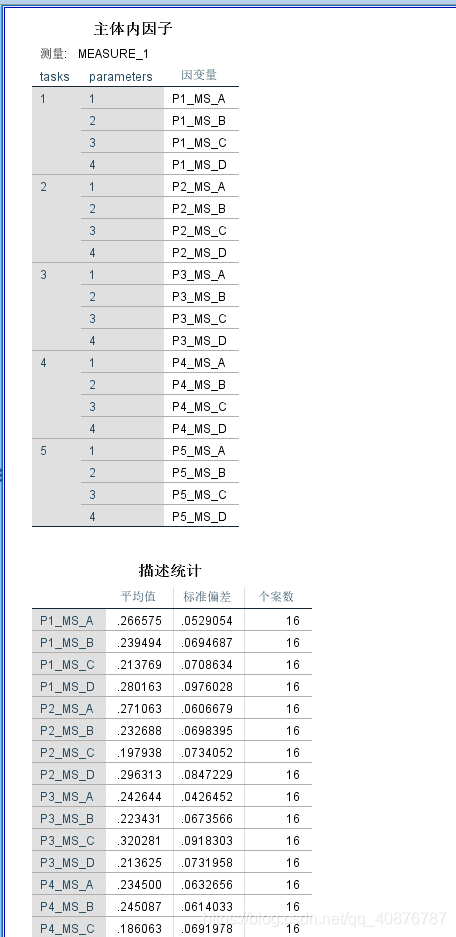
研究者研究了16名健康人在五种状态(P1、P2、P3、P4、P5)下的参数(MS_A、MS_B、MS_C、MS_D)是否存在显著性差异;每种状态下均有参数(MS_A、MS_B、MS_C、MS_D)。
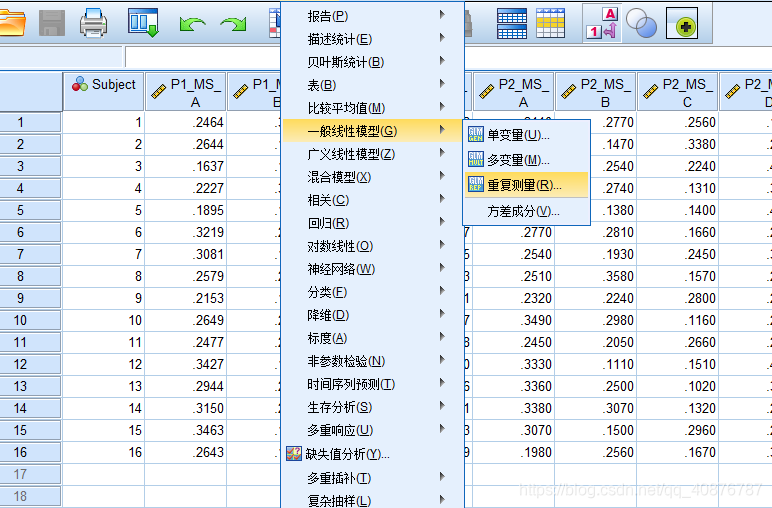
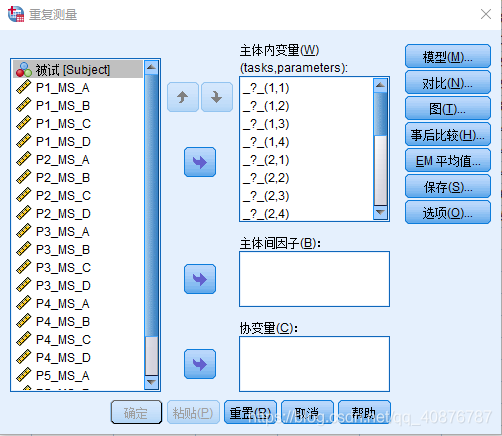
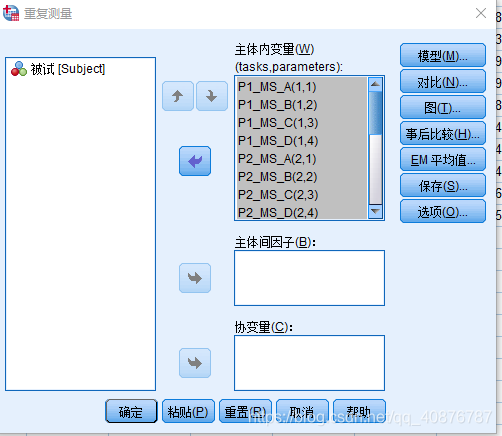
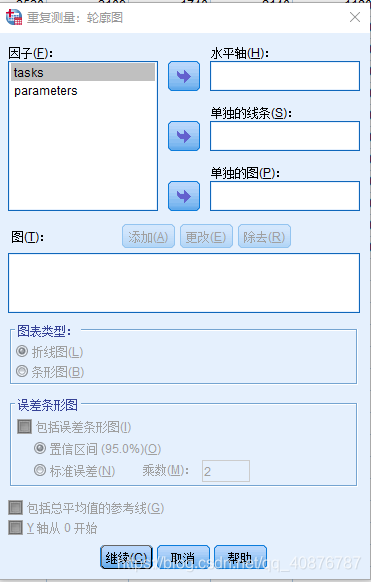
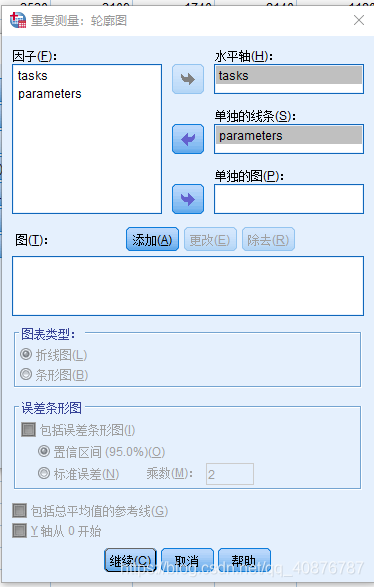
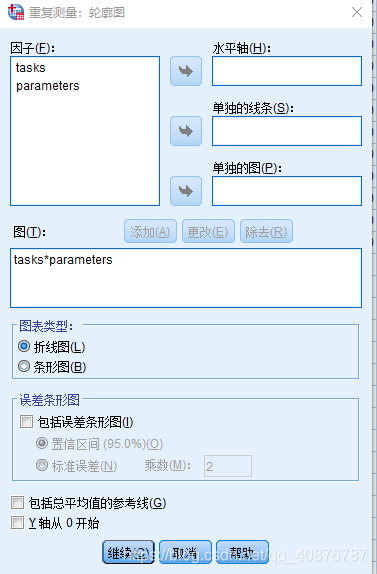
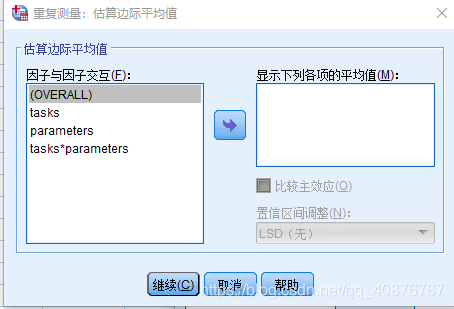
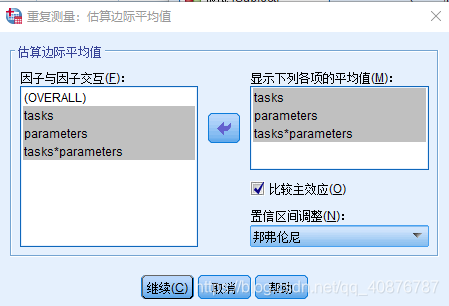
因为自变量均为Within-subject factors时,故用Two-way repeated-measures ANOVA。
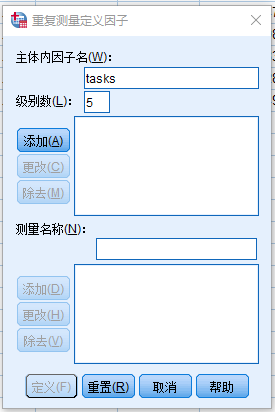
两因素分别为:不同的状态(P1、P2、P3、P4、P5)和不同的参数(MS_A、MS_B、MS_C、MS_D)
部分数据如下表: 二、SPSS操作