相关文章链接
时间序列预测——ARIMA模型 https://blog.csdn.net/beiye_/article/details/123317316?spm=1001.2014.3001.5501
https://blog.csdn.net/beiye_/article/details/123317316?spm=1001.2014.3001.5501
案例:基于ARIMA模型对螺纹钢价格预测——以南昌市为例
钢铁作为我国经济发展主要战略原材料,其价格成本也是工程造价预算的重要组成部分,利用时间序列预测未来短期钢材价格,有助于对钢材价格特征变化规律深入探索。本文就螺纹钢价格为研究对象,以南昌市2015年1月~2022年3月直径16mm至25mmHRB400E型螺纹钢价格为例,运用时间序列预测分析方法和数据分析软件SPSS建立ARIMA模型,并预测未来9个月南昌市该型号螺纹钢价格。对研究结果进行分析,得出了预测曲线,且确定相对误差在允许的误差范围内,为施工企业在建筑钢材采购以及投标策略上提供策略支撑。
一、ARIMA模型的建模流程
第一.收集差分数据并用于制作差分时序图表和检验差分平稳性。第二,对差分非平稳性数据进行差分平稳化后的处理,差分d值的确定。第三,根据差分次数公式d,建立差分序列。第四,模型进行识别和定阶,利用自相关差分函数(ACF)和偏自相关方差函数(PACF)确定p阶和q阶。第五,模型参数的参数估计分析和适应性检验。第六,利用ARIMA(p,d,q)模型对系统进行预测。
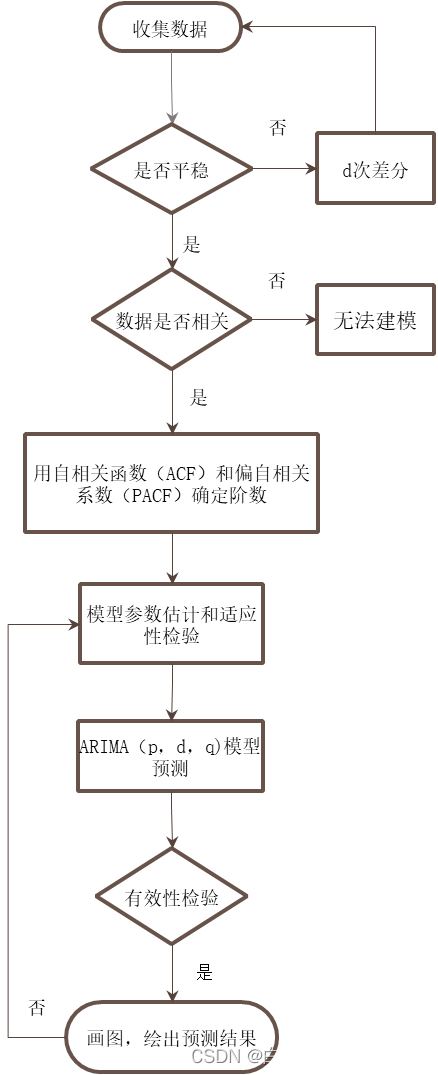
图 ARIMA建模流程图
二、数据集
本文中价格数据选用南昌市从2015年1月起至2022年3月直径由内径16mm区间到直径25mm区间内的HRB400E钢材价格信息作为数据分析或研究对象。共已完成采集和记录采集到的样本数据值共达2645个,由于因各种因素数据值存在有一定的部分的数据缺失值,为更充分地保证已采集到样本数据准确性,本文采用SPSS软件来对样本的缺失部分数据值进行分析,并通过利用本软件中其数据缺失值分析功能的补充功能来尝试将丢失样本数据补齐。
三、利用SPSS软件对ARIMA时间序列预测操作的基本步骤
1、确定数据
选择数据:南昌市从2015年1月起至2022年3月直径由内径16mm区间到直径25mm区间内的HRB400E钢材价格信息

2、导入数据
将收集到到原始数据导入SPSS软件中

3、定义时间日期
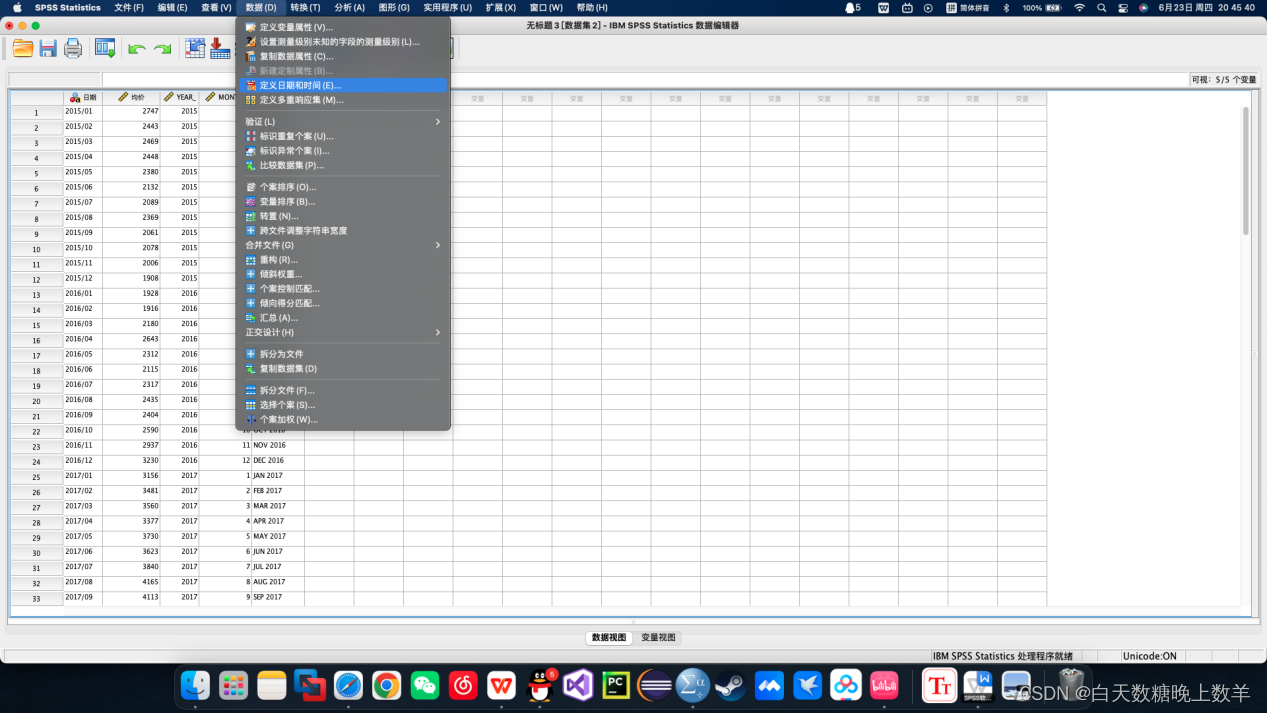
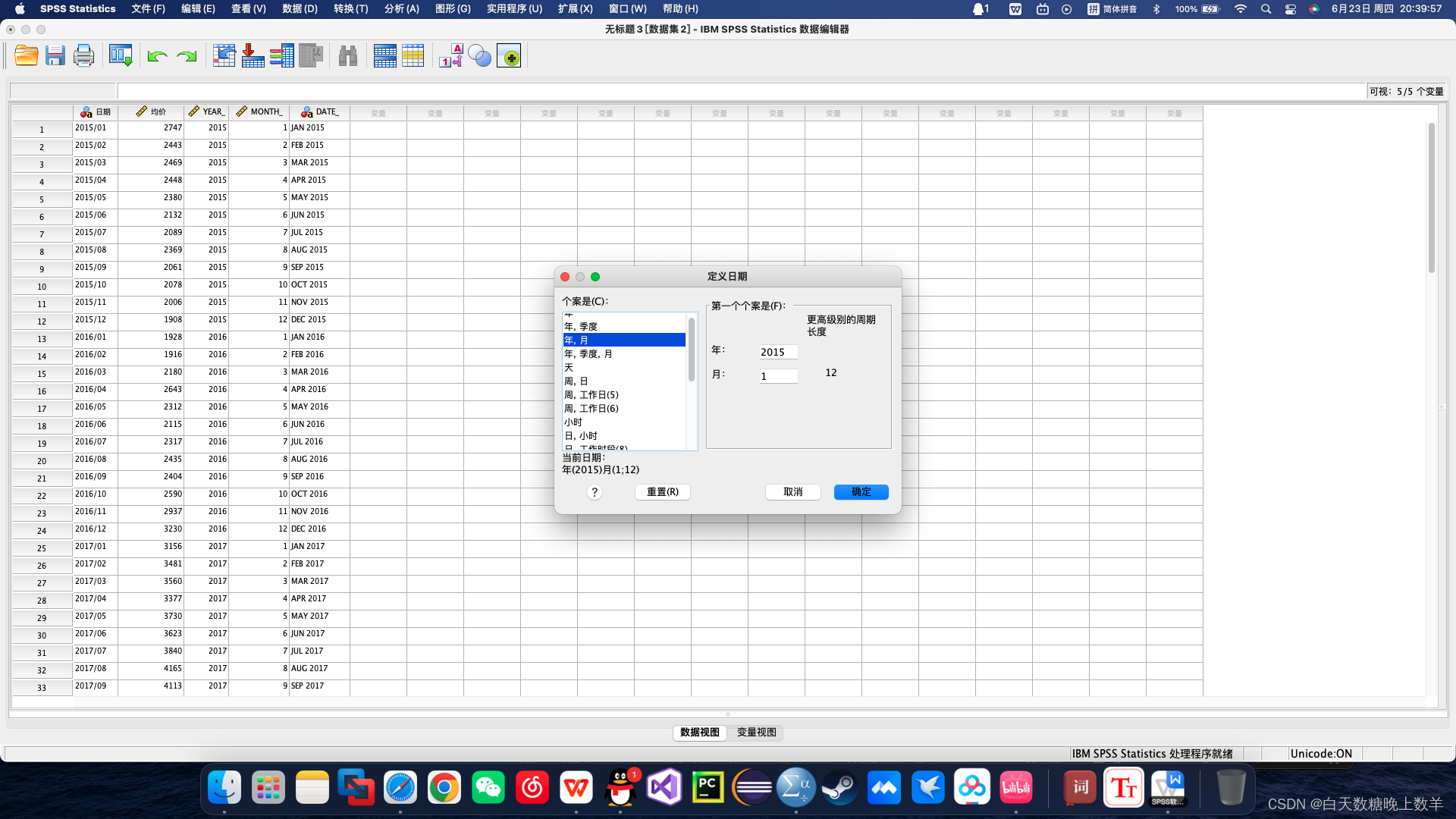
4、图像化观察
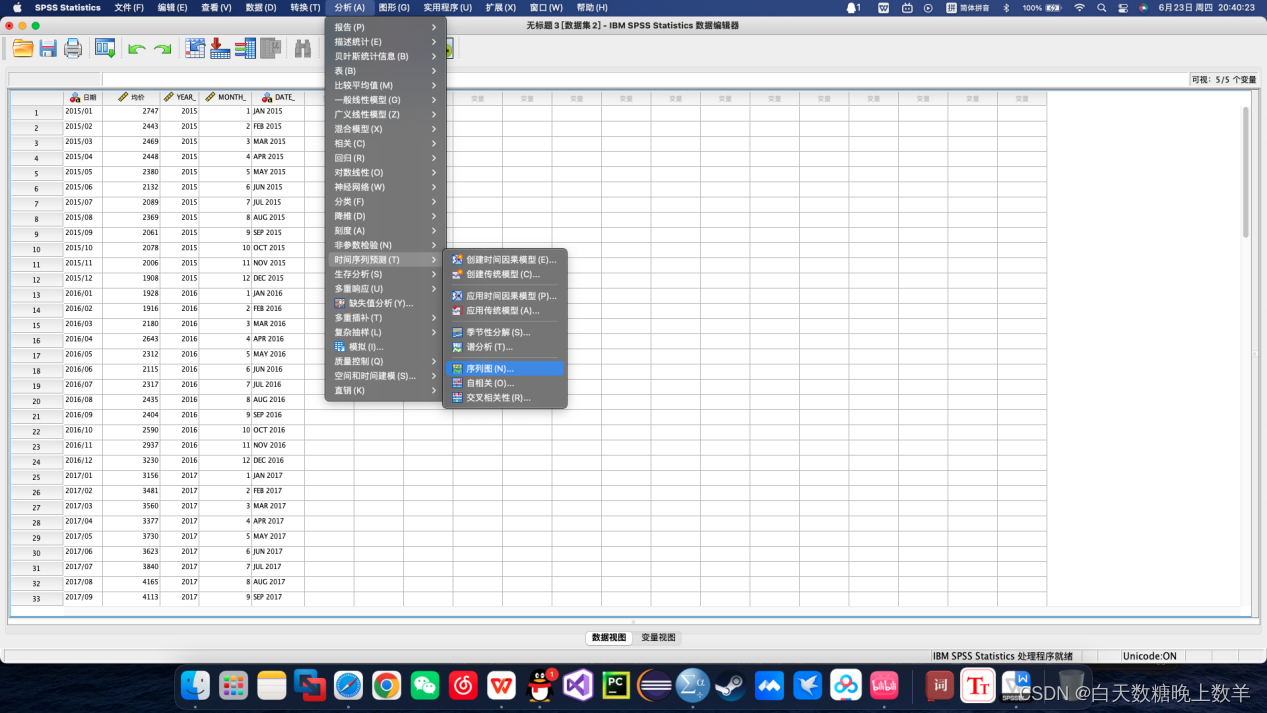
选择要显示的变量,此处是均价,时间轴标签选定义时间日期后的标签项,点击确定得到序列图。
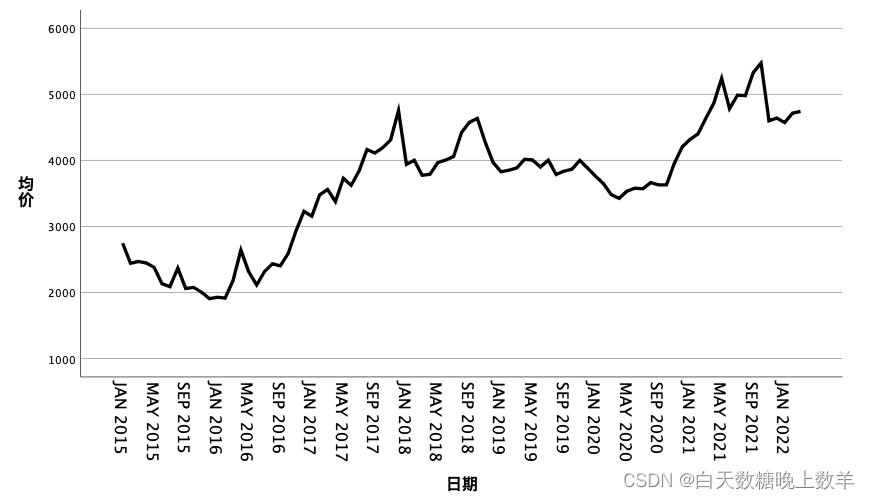
序列图如下:
5、平稳性分析
ARIMA模型要求序列是平稳序列,因此要对数据进行平稳性分析。下面做螺纹钢价格序列的自相关图和偏自相关图。
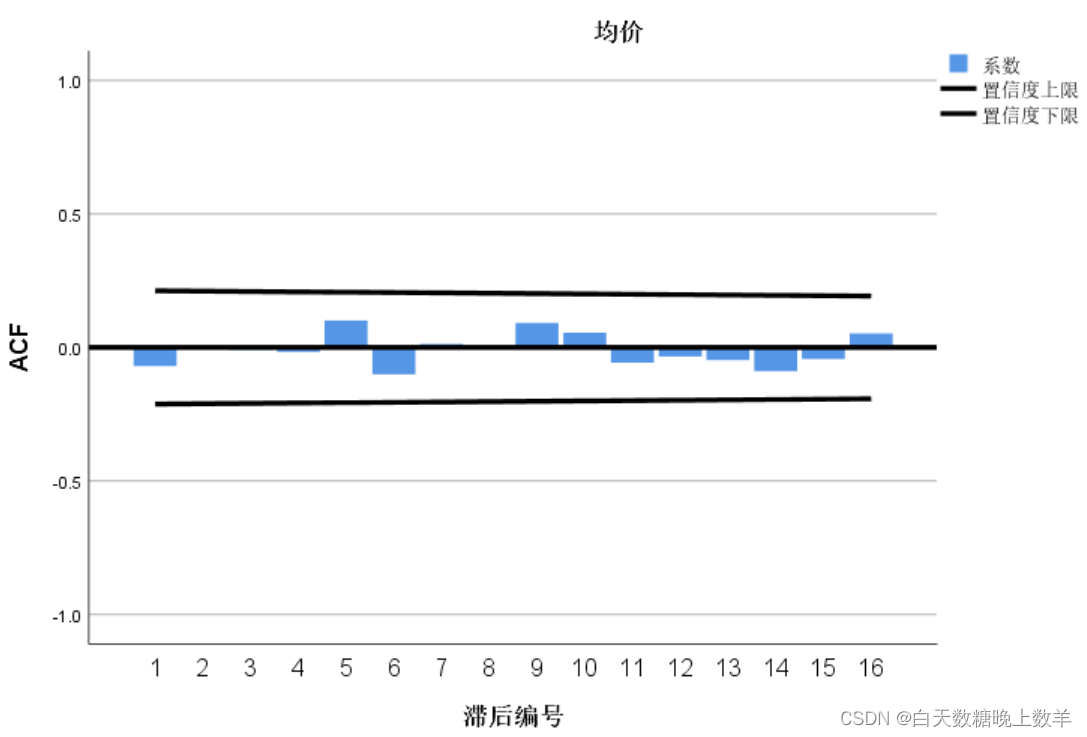
自相关图:
偏自相关图:
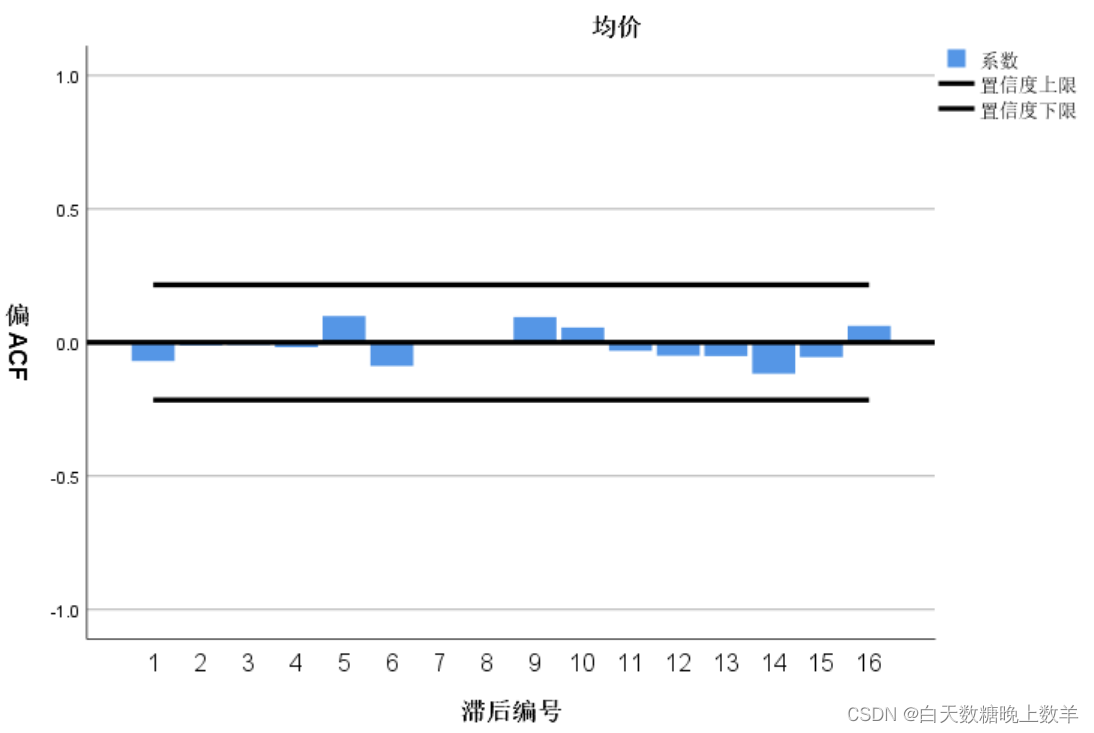
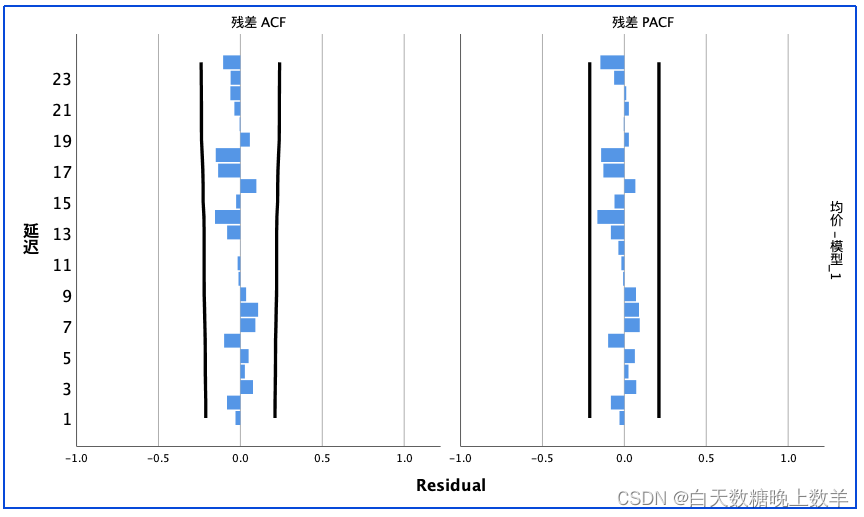
从图中可以看出,序列的自相关图(ACF)和偏自相关图(偏ACF)大部分编号位于置信区间内部,说明序列是基本平稳的。
6、构建ARIMA模型
在【分析】中选择【时间序列预测】,选择【创建传统模型】。
在【变量】页面,选择方法:ARIMA;由上述ACF和PACF选定条件
在【统计】页面,根据自己需要勾选显示的数据;
在【图】页面,选自自己需要输出的图形数据;
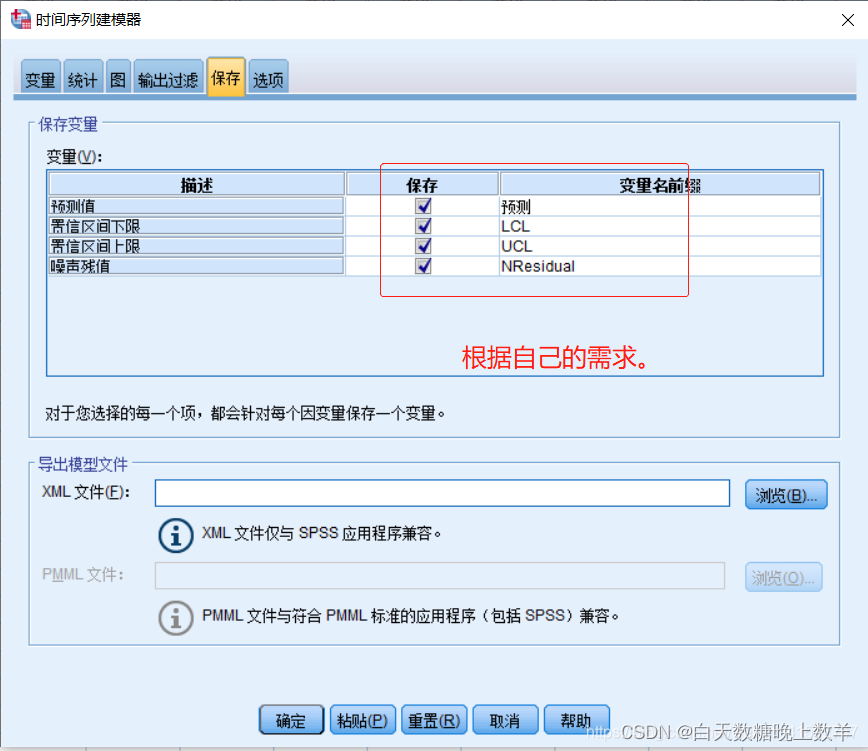
在【保存】页面,勾选自己需要保存的内容。
7、输出结果

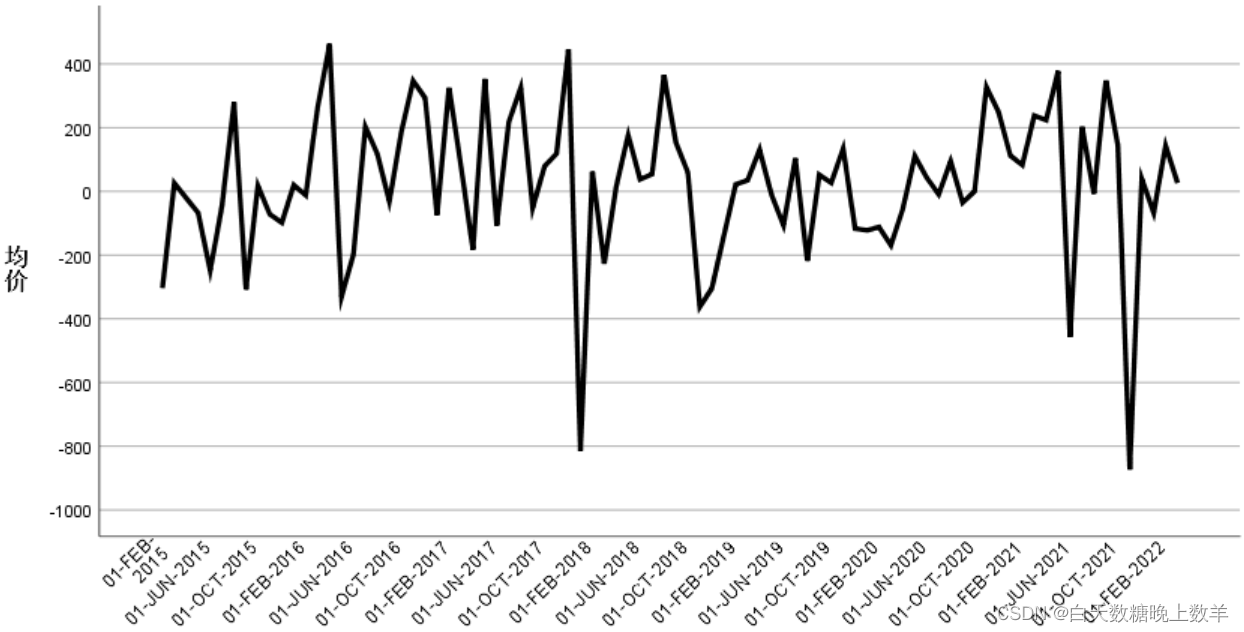
一阶差分后时序图:
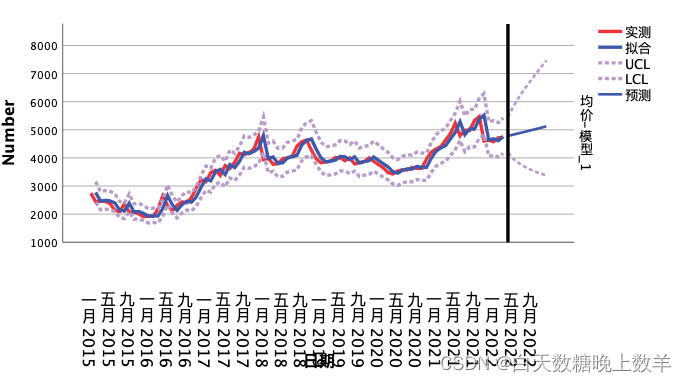
预测结果:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)