矩阵乘法——基于GPU的并行编程模型CUDA程序设计

1 题目描述
题目1:编写一个矩阵乘法的GPU并行程序,并且与对应规模的串行程序进行运行时间的比对(n=500,1000,1500,2000,3000,5000),画出规模和时间对比图。
矩阵A(n,n)
矩阵B(n,n)
C = A x B
要求:
1、完成程序的开发并验证其正确性,完成一个实验报告(程序源代码、变量和语句的详细说明;
2、在实验报告中通过图表说明CPU串行和GPU并行在各种规模的运行时间;
3、在实验报告中通过图表说明GPU并行不同的数据分配在各种规模的运行时间
2 设计思路
CPU串行程序:对于矩阵A(n,n),矩阵B(n,n)做矩阵乘运算得到C = A x B。矩阵乘的基本操作为:元素Cij=A的第i行x B的第j列。所以我们通过三层for循环嵌套来计算矩阵的乘法。
CUDA并行程序:矩阵相乘过程中,结果矩阵C中的每个元素都是可以独立计算的,即彼此之间并无依赖性。所以我们可以让矩阵C中的每个元素都有一个单独的线程去计算,这样将会显著地提高矩阵相乘的计算效率。但是实际中通常不可能有像矩阵元素那么多的线程和处理器资源,这时我们就应该把矩阵分块,分成一个个的子矩阵,让每个线程去计算每个子矩阵,最后再把每个线程得到的结果组合起来就可以得到矩阵相乘的最终结果。
实验环境
操作系统:Windows10
开发环境:Visual Studio 2019 + CUDA Toolkit 11.0
3 源码
3.1 串行程序
矩阵乘法的CPU程序
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <iomanip>
#include "ctime"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
using namespace std;
#define MATRIX_SIZE 500
//构造矩阵
void BuildMatrix(float* a, int n) {
for (int i = 0; i < n * n; i++) {
a[i] = 2.0;
}
return;
}
//输出矩阵
void printfMatrix(float* a, int n) {
for (int i = 0; i < n * n; i++) {
printf("%lg\t", a[i]);
if ((i + 1) % n == 0)
printf("\n");
}
return;
}
int main() {
float* a, * b, * c, * d;
int n = MATRIX_SIZE;
//分配内存
a = (float*)malloc(sizeof(float) * n * n);
b = (float*)malloc(sizeof(float) * n * n);
c = (float*)malloc(sizeof(float) * n * n);
d = (float*)malloc(sizeof(float) * n * n);
BuildMatrix(a, n);
BuildMatrix(b, n);
//printfMatrix(a, n);
//printfMatrix(b, n);
/*CPU矩阵乘法,存入矩阵d*/
//cpu计时开始
cudaEvent_t cpustart, cpustop;
float cpuelapsedTime = 0.0;
cudaEventCreate(&cpustart);
cudaEventCreate(&cpustop);
cudaEventRecord(cpustart, 0);
clock_t begin_time, end_time;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
double t = 0;
for (int k = 0; k < n; k++) {
t += a[i * n + k] * b[k * n + j];
}
d[i * n + j] = t;
}
}
//cpu计时结束
cudaEventRecord(cpustop, 0);
cudaEventSynchronize(cpustop);
cudaEventElapsedTime(&cpuelapsedTime, cpustart, cpustop);
cudaEventDestroy(cpustart);
cudaEventDestroy(cpustop);
double cputime = cpuelapsedTime;
cout << setiosflags(ios::fixed) << setprecision(6) << "CPU time: " << (cputime) / 1000 << " s" << endl;
return 0;
}
3.2 并行程序
矩阵乘法的GPU程序并用CPU计算结果进行结果检验
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include<iomanip>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
using namespace std;
#define THREAD_NUM 256
#define MATRIX_SIZE 500
const int blocks_num = (MATRIX_SIZE * MATRIX_SIZE + THREAD_NUM - 1) / THREAD_NUM;
//构造矩阵
void BuildMatrix(float* a, int n)
{
for (int i = 0; i < n * n; i++)
{
a[i] = 2.0;
}
return;
}
//输出矩阵
void printfMatrix(float* a, int n) {
for (int i = 0; i < n * n; i++) {
printf("%lg\t", a[i]);
if ((i + 1) % n == 0)
printf("\n");
}
return;
}
// __global__ 函数 并行计算矩阵乘法
__global__ static void matMultCUDA(const float* a, const float* b, float* c, int n)
{
//表示目前的 thread 是第几个 thread(由 0 开始计算)线程
const int tid = threadIdx.x;
//表示目前的 thread 属于第几个 block(由 0 开始计算)块
const int bid = blockIdx.x;
//从 bid 和 tid 计算出这个 thread 应该计算的 row 和 column
const int idx = bid * THREAD_NUM + tid;
const int row = idx / n;
const int column = idx % n;
//计算矩阵乘法
if (row < n && column < n)
{
float t = 0;
for (int i = 0; i < n; i++)
{
t += a[row * n + i] * b[i * n + column];
}
c[row * n + column] = t;
}
return;
}
int main()
{
float* a, * b, * c, * d;
int n = MATRIX_SIZE;
//分配内存
a = (float*)malloc(sizeof(float) * n * n);
b = (float*)malloc(sizeof(float) * n * n);
c = (float*)malloc(sizeof(float) * n * n);
d = (float*)malloc(sizeof(float) * n * n);
BuildMatrix(a, n);
BuildMatrix(b, n);
//printfMatrix(a, n);
//printfMatrix(b, n);
/*CUDAgpu并行开始 a*b=c */
//cudaMalloc 取得一块显卡内存
float* cuda_a, * cuda_b, * cuda_c;
cudaMalloc((void**)&cuda_a, sizeof(float) * n * n);
cudaMalloc((void**)&cuda_b, sizeof(float) * n * n);
cudaMalloc((void**)&cuda_c, sizeof(float) * n * n);
//cudaMemcpy 将产生的矩阵复制到显卡内存中:cudaMemcpyHostToDevice - 从内存复制到显卡内存,cudaMemcpyDeviceToHost - 从显卡内存复制到内存
cudaMemcpy(cuda_a, a, sizeof(float) * n * n, cudaMemcpyHostToDevice);
cudaMemcpy(cuda_b, b, sizeof(float) * n * n, cudaMemcpyHostToDevice);
//CUDA计时开始
cudaEvent_t gpustart, gpustop;
float gpuelapsedTime = 0.0;
cudaEventCreate(&gpustart);
cudaEventCreate(&gpustop);
cudaEventRecord(gpustart, 0);
// 在CUDA 中执行函数 语法:函数名称<<<block 数目, thread 数目>>>(参数...);
matMultCUDA << < blocks_num, THREAD_NUM >> > (cuda_a, cuda_b, cuda_c, n);
cudaDeviceSynchronize();//同步CPU和gpu,否则测速结果为cpu启动内核函数的速度
//CUDA计时结束
cudaEventRecord(gpustop, 0);
cudaEventSynchronize(gpustop);
cudaEventElapsedTime(&gpuelapsedTime, gpustart, gpustop);
cudaEventDestroy(gpustart);
cudaEventDestroy(gpustop);
double gputime = gpuelapsedTime;
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(c, cuda_c, sizeof(float) * n * n, cudaMemcpyDeviceToHost);
//释放内存
cudaFree(cuda_a);
cudaFree(cuda_b);
cudaFree(cuda_c);
cudaFree(time);
/*CPU矩阵乘法,存入矩阵d*/
//cpu计时开始
cudaEvent_t cpustart, cpustop;
float cpuelapsedTime = 0.0;
cudaEventCreate(&cpustart);
cudaEventCreate(&cpustop);
cudaEventRecord(cpustart, 0);
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
double t = 0;
for (int k = 0; k < n; k++)
{
t += a[i * n + k] * b[k * n + j];
}
d[i * n + j] = t;
}
}
//cpu计时结束
cudaEventRecord(cpustop, 0);
cudaEventSynchronize(cpustop);
cudaEventElapsedTime(&cpuelapsedTime, cpustart, cpustop);
cudaEventDestroy(cpustart);
cudaEventDestroy(cpustop);
double cputime = cpuelapsedTime;
/*验证正确性与精确性*/
float max_err = 0;
float average_err = 0;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (d[i * n + j] != 0)
{
//fabs求浮点数x的绝对值
float err = fabs((c[i * n + j] - d[i * n + j]) / d[i * n + j]);
if (max_err < err) max_err = err;
average_err += err;
}
}
}
/*输出结果*/
cout << setiosflags(ios::fixed) << setprecision(6) << "MAX ERROR: " << max_err << endl;
cout << setiosflags(ios::fixed) << setprecision(6) << "AVERAGE ERROR: " << average_err / (n * n) << endl;
cout << setiosflags(ios::fixed) << setprecision(6) << "GPU time: " << (gputime) / 1000 << " s" << endl;
//cout << setiosflags(ios::fixed) << setprecision(6) << "CPU time: " << (cputime) / 1000 << " s" << endl;
return 0;
}
3.3 性能对比与分析
CPU串行和GPU并行(ThreadsPerBlock=256,ThreadsPerBlock:每个线程块所拥有的线程数量)在各种规模的运行时间如图1所示。在数据规模N比较小时,CPU串行和GPU并行程序运行消耗的时间相差不大。当数据规模N逐步增大时,CPU串行程序运行消耗时间的增长速度远远超过GPU并行程序运行消耗时间的增长速度。
当数据规模N=5000时,CPU串行程序运行消耗时间已经是GPU并行程序运行消耗时间的12.41倍,消耗的时间达到了693.44s。而从图2中可以预见的是CPU串行程序运行消耗的时间将会很大很大,很有可能呈现指数级增长趋势
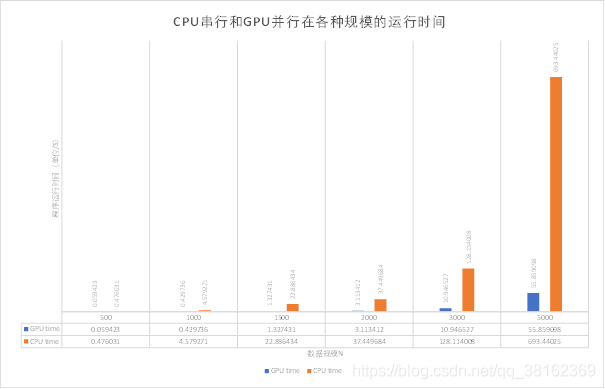
图1 CPU串行和GPU并行在各种规模的运行时间
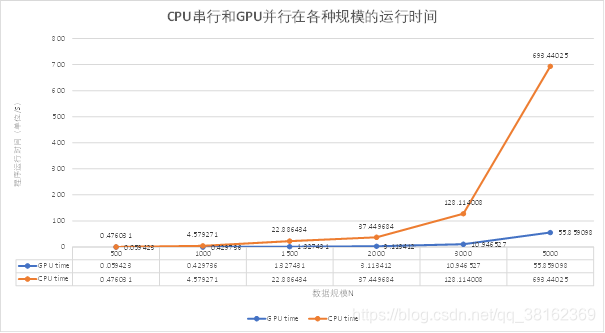
图2 CPU串行和GPU并行在各种规模的运行时间趋势图
GPU并行不同的数据分配(ThreadsPerBlock:每个线程块所拥有的线程数量)在各种规模下的运行时间如图3所示。在数据规模N比较小的时候,不同的数据分配方式下程序运行消耗时间没有显著差异。随着数据规模N的增大,不同的数据分配方式下程序运行消耗时间的差异开始显现。
当数据规模N=5000时,我们可以明显的看出在ThreadsPerBlock=256时程序运行消耗时间比在其他条件下小。程序运行消耗时间呈两边高,中间低的趋势,每个线程块所拥有的线程数量最少和最多的程序运行消耗的时间分别是最多的和次多的。
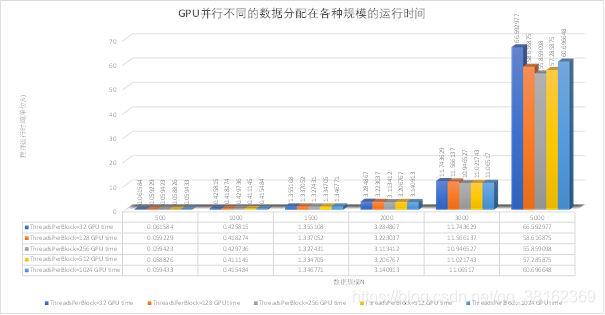
图3 GPU并行不同的数据分配在各种规模的运行时间