1、什么是跨平台
(1)这里的平台是按照CPU的位数来划分,分为32位CPU和64位CPU,不同位数CPU的差异会影响到结构体的解析;
(2)在实际嵌入式开发中,存在"主芯片+从芯片"的多CPU的产品,或者数据需要在不同位数CPU的机器上传输;
(3)一般传输的数据包都会封装成结构体,如果结构体在跨平台上传输就需要消除CPU位数带来的影响,保证数据接收双方对结构体的解析都正确;
2、容易造成错误的原因分析
(1)要消除间隙,避免CPU字长不一样,造成错位:在32位CPU中默认是4字节对齐,64位CPU中默认是8字节对齐,结构体的对齐字节数不相同会导致填充的字节数不相同,也就会造成解析结构体时变量地址错位的现象;
(2)某些数据类型在32位CPU和64位CPU中占用的字节数不相同;
3、结构体成员错位的情况
3.1、示例代码
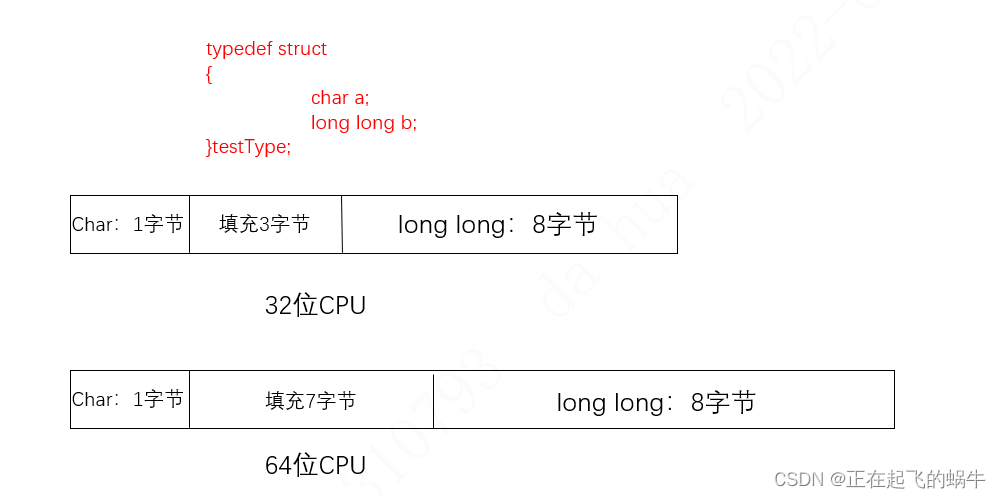
(1)由于默认结构体对齐字节数的不同,导致填充字节数不一样,上面的结构体在32位CPU中占12字节,在64位CPU中占16字节;
(2)如果通信双方是32位CPU和64CPU,各自按照自己的结构体对齐数进行发送、解析结构体,必然会因为结构体内变量地址的错位而导致不能解析出正确的数据;
3.2、解决方法
(1)没有什么特别好的办法,自己定义结构体时注意结构体对齐可能带来的填充字节的问题,比如不要用char类型这种大概率会需要填充的数据类型;
(2)定义检查结构体大小的编译宏,可以在编译阶段帮你检查结构体大小是否符合预期,参考博客:《利用宏定义在编译阶段检查结构体大小的方法》;
4、数据类型大小不一致的情况
4.1、示例代码
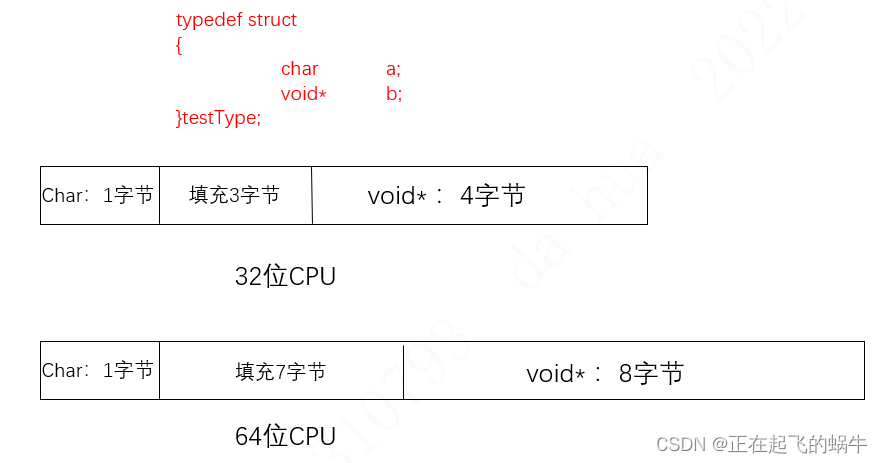
(1)上面结构体中存在的问题,不仅存在因为对齐字节数导致的地址错位问题,还有存在变量类型在不同CPU中所在字节数不同的问题;
(2)指针变量在32位CPU中占4字节,在64位CPU中占8字节;
4.2、解决方法
| C类型 |
32位机器(字节) |
64位机器(字节) |
| char |
1 |
1 |
| short |
2 |
2 |
| int |
4 |
4 |
| long int |
4 |
8 |
| long long |
8 |
8 |
| void*(指针变量) |
4 |
8 |
| float |
4 |
4 |
| double |
8 |
8 |
| char |
1 |
1 |
typedef struct
{
char a;
unsigned long long ptr; //指针变量
}testType;
(1)解决办法就是不要用在不同位数CPU中有歧义的变量类型,全部用不会有歧义的变量类型去替换;
(2)比如:上面的指针变量"void *“类型用"unsigned long long"类型替换,这样确保无论在32位还是64位的CPU上都是占8字节,然后不同的CPU在使用变量时进行强制类型转换成"void *”;