2022年华中杯数学建模
B题 量化投资问题
原题再现:
量化投资是指通过数量化方式及计算机程序化发出买卖指令,以获取稳定收益为目的的交易方式。投资者通过数据分析探索市场运行规律,并预测市场走势,从而进行决策交易。随着大数据技术的发展,量化投资在全球金融交易市场上的地位愈加重要。但是由于市场信息十分庞杂,同时产品的价格也受到其他诸多因素的影响,如何从海量的市场信息中提取出有效指标,制订交易策略,是一个具有挑战性的工作。
本题附表提供的数据指标,主要包括:①宏观市场指标(采购经理指数、社会消费品零售总额、居民消费价格指数、国内生产总值、人民币存款利率、人民币贷款利率);②国内股票市场指标(上证综合指数成交量、上证综合指数成交金额、股票市场总值、股票市场流通值(股票流通市值)、沪深 300 指数、上证综合指数、中证 500 指数、创业板指数、上证 50 指数、上证 A 股指数、深证成份指数、深证综合指数科创 50 指数);③技术指标(VMA、VMACD、ARBR、OBV、BBI、DMA、MA、EXPMA、MTM、MACD、BIAS、KDJ、RSI、BOLL);④国际股票市场指标(道琼斯工业指数、纳斯达克综合指数、标准普尔 500 指数、美国证交所指数、美元/人民币汇率、香港恒生指数、东京日经 225 指数、伦敦金融时报100 指数、法国巴黎 CAC40 指数、荷兰 AEX 指数、俄罗斯 RTS 指数、意大利 MIB 指数、欧元/美元汇率);⑤“数字经济”板块信息(每 5 分钟开盘价、每 5 分钟收盘价、每 5 分钟最高价、每 5 分钟最低价、每 5 分钟成交量,每 5 分钟金额);⑥其他板块信息(“数字媒体”板块指数、“数字孪生”板块指数、“快手概念”板块指数、“互联网电商”板块指数、“互联网”板块指数)。
请参赛团队基于 2021 年 7 月 14 日至 2022 年 1 月 28 日每 5 分钟的“数字经济”板块给出的数据信息,完成以下任务:
(1)对所提供的各项指标进行分析,从中提取出与“数字经济”板块有关的主要指标。
(2)以 2021 年 7 月 14 日至 2021 年 12 月 31 日的每 5 分钟“数字经济”板块指数为训练集,以 2022 年 1 月 4 日至 2022 年 1 月 28 日的每 5 分钟“数字经济”板块指数为测试集。根据问题(1)提取出来的各项指标对“数字经济”板块指数每 5 分钟成交量进行预测。
(3)以 2021 年 7 月 14 日至 2021 年 12 月 31 日的每 5 分钟“数字经济”板块指数为训练集,以 2022 年 1 月 4 日至 2022 年 1 月 28 日的每 5 分钟“数字经济”板块指数为测试集。根据(1)和(2)建立模型对每 5 分钟的“数字经济”板块指数(收盘价)进行预测。
(4)假设以“数字经济”板块指数为交易对象(在实际交易中指数无法交易,只能交易其中的个股),给定初始资金 100 万元,交易佣金为 0.3%,根据(3)得到的结果对“数字经济”板块每 5 分钟频率价格进行买卖交易,计算在 2022 年 1 月 4 日至 2022 年 1月 28 日期间交易的总收益率、信息比率、最大回撤率。

整体求解过程概述(摘要)
本文针对股票各项指标对量化投资的影响问题,对股票的各项影响因素与“数字经济”板块的关系进行了分析研究,建立均值插补模型、皮尔逊相关系数模型、基于 LSTM 神经网络的股票预测模型等多种数学模型,分析出与“数字经济”板块有关的主要指标,从而对“数字经济”板块指数进行预测,给出预测结果及总收益率等参数值。
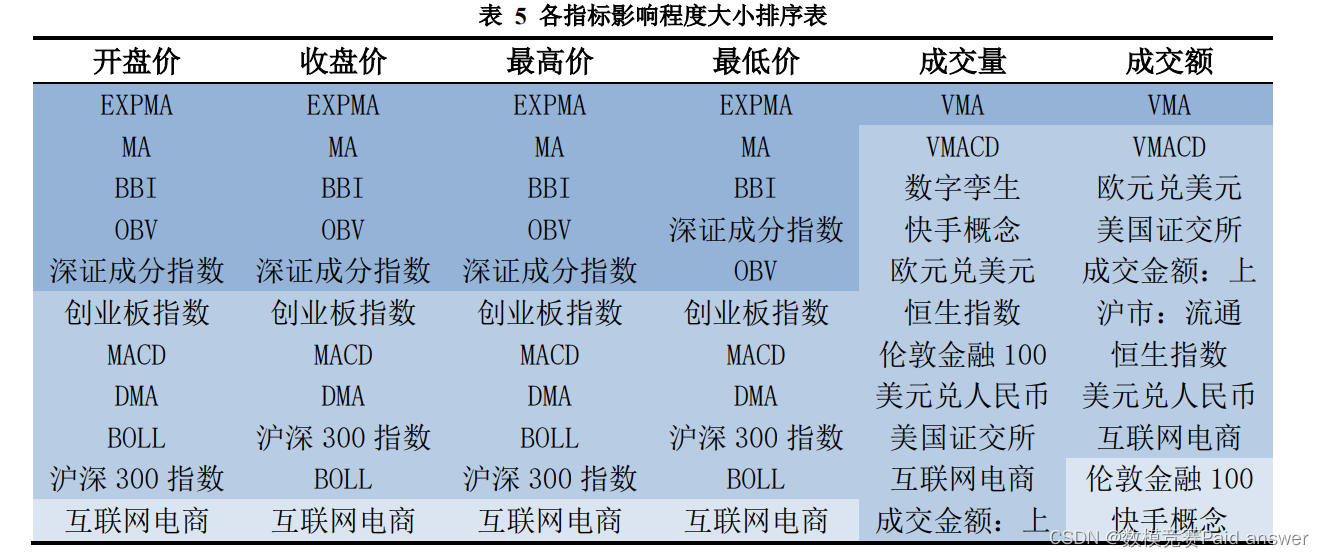
针对问题一,首先对各项指标信息进行数据预处理,删除不在分析时间范围内的数据,通过建立均值插补模型,完善缺失数据。以日作为研究单位,分别求出“数字经济”板块各项每日的均值作为当日该类的平均水平。建立评价指标规范化模型,将所有数据标准化、无量纲化处理。最后,绘制并观察各指标图像的变化规律,建立皮尔逊相关系数模型,计算各项指标与上述六项信息的相关性数值并排序,分别得到各指标对于开盘价、收盘价、最高价、最低价、成交量和成交额各项指数的影响程度。再计算出各指标对于上述六项信息的相关性系数的均值,仅保留均值大于 0.6 的强相关性和极强相关性指标,从而得出与“数字经济”板块有关的 9 项主要指标为:EXPMA、MA、BBI、BOV、创业板块指数、VMA、深证成分指数、BOLL、互联网电商。
针对问题二,参考问题一所得出的对于成交量的 12 项主要指标,建立基于LSTM 神经网络的股票预测模型。由于无法在股票交易当天就获知上述 12 项指标的全部当日数据。因此,本问选用 2021 年 7 月 13 日至 2021 年 12 月 30 日的指标数据为输入层特征值,2021 年 7 月 14 日至 2021 年 12 月 31 日的每日每五分钟成交量为输出值,对 LSTM 神经网络模型进行训练,从而得出 12 项指标与成交额之间的非线性映射关系。最后,将 2022 年 1 月 3 日至 2022 年 1 月 27 日的指标数据作为输入,测试该神经网络,预测出 2022 年 1 月 4 日至 2022 年 1月 28 日每日每五分钟的股票成交量。
针对问题三,本问直接参考问题二所建立的 LSTM 神经网络模型和训练集数据,对 2022 年 1 月 4 日至 2022 年 1 月 28 日每五分钟的收盘价进行预测。
针对问题四,基于问题三所得的 2022 年 1 月 4 日至 2022 年 1 月 28 日,共852 个“数字经济”板块收盘价数据,以 100 万元为初始资金,先对总收益率进行分析。建立基于数据降维法的收益最大化模型,同时考虑交易佣金和投资者获利需求,给出交易者最合理的投资策略,从而得到最大的投资总收益率。接着,根据题目所给公式计算出信息比率和最大回撤率,分别反映出一段时间内的收益和该股票的投资风险。最后,利用题目所给的 2022 年 1 月 4 日至 2022 年 1 月28 日的实际收盘价计算相应的总收益率、信息比率和最大回撤率,与使用预测
值计算的结果相比较,从而得出预测值的准确性。综上所述,本文通过建立多个数学模型,依据题目所给数据对股票的各项影响指标与“数字经济”板块数据的关系进行了分析研究,给出了对板块指数的预测结果及总收益率等参数值。最后,对模型进行了优缺点的评价及推广,使其更具现实意义。
关键词:均值插补模型;皮尔逊相关系数;LSTM 神经网络;数据降维
问题分析:
问题一要求根据附件所提供的指标信息,分析得出与“数字经济”板块有关的主要影响指标。首先,对附件所提供的各项指标数据进行数据清洗和筛选。采用均值插补法,将缺失数据完善。以日作为单位进行研究,将“数字经济”板块的六项信息分别看作独立的一类,以各类每日的均值作为当日该类的平均水平。接着,建立评价指标规范化模型,将各项指标的数据进行标准化、无量纲化处理。最后,绘制出各指标数据的变化规律图像。观察曲线的变化规律,建立皮尔逊相关系数模型,确定各项指标与上述六项信息的相关系数值。将六项信息与各指标的相关系数分别排序,得到各指标对于开盘价、收盘价、最高价、最低价、成交量和成交额各项的影响程度。再计算出各指标对于上述六项信息的相关性系数的均值,舍去其中均值小于 0.6 的指标,仅保留强相关性和极强相关性的指标,从而得出与“数字经济”板块有关的主要指标。
问题二要求根据问题一所提取的各项指标,对“数字经济”板块指数每 5分钟成交量进行预测。使用 2021 年 7 月 14 日至 2021 年 12 月 31 日的“数字经济”板块指数为训练集,2022 年 1 月 4 日至 2022 年 1 月 28 日数据为测试集。首先,根据问题一的分析结果,提取出了与“数字经济”板块相关性最强的 12项指标。因此,本问的预测将基于上述 12 项指标,建立基于 LSTM 神经网络的股票预测模型,利用问题一中 2021 年 7 月 13 日至 2021 年 12 月 30 日规范化处理后的数据,对所建立的 LSTM 神经网络模型进行学习训练。神经网络通过学习可以得到 12 项指标与成交额之间的非线性映射关系,从而建立起该神经网络的输入输出关系。最后,将 2022 年 1 月 4 日至 2022 年 1 月 28 日的数据作为输入,测试该神经网络,得出该时间段内每日每五分钟的股票成交量。
问题三需要在问题一和问题二所建立的数学模型的基础上,来预测每 5 分钟的“数字经济”板块指数的收盘价。本文可直接参考问题二所建立的 LSTM 神经网络模型,对未来一段时间的收盘价进行预测。
问题四要求根据问题三所得结果,以 100 万元为初始资金,0.3%为交易佣金,对“数字经济”板块指数进行交易。从而得出 2022 年 1 月 4 日至 2022 年 1 月28 日期间交易的总收益率、信息比率和最大回撤率。首先,利用问题三所得的2022 年 1 月 4 日至 2022 年 1 月 28 日,共 852 个“数字经济”板块收盘价数据,以 100 万元为初始资金,先对总收益率进行分析。建立基于数据降维法的收益最大化模型,同时考虑交易佣金和投资者获利需求,给出交易者最合理的投资策略,从而得到最大的投资总收益率。接着,根据题目所给公式计算出信息比率和最大回撤率,分别反映出一段时间内的收益和该股票的投资风险。最后,利用题目所给的 2022 年 1 月 4 日至 2022 年 1 月 28 日的实际收盘价计算相应的总收益率、信息比率和最大回撤率,与使用预测值计算的结果相比较,从而得出预测值的准确性。
模型的建立与求解:
问题一要求根据附件所提供的指标信息,分析得出与“数字经济”板块有关的主要影响指标。首先,由于分析是基于 2021 年 7 月 14 日至 2022 年 1 月 28日的数字经济板块的数据,要先对附件所提供的各项指标进行数据清洗和筛选。对于各项指标中不在上述日期范围内的数据,本文分析暂时不作考虑,可直接删除;对于在分析时间范围内的数据,观察发现有部分指标的数据缺失。通过建立均值插补模型,将缺失数据完善。
由于“数字经济”板块信息是以每五分钟为一周期的统计数据,而各项指标数据大多以每日为一个周期;因此,本问将以日作为单位进行研究。(对于宏观市场指标 1 和宏观市场指标 2,由于其变化周期分别为每月和每季度,数据过少且参考价值不高,本文不对其进行分析)。将“数字经济”板块的六项信息分别看作独立的一类,以各类每日的均值作为当日该类的平均水平。接着,为防止各项指标因数量级大小不同对分析造成影响,建立评价指标规范化模型,将各项指标的数据进行标准化、无量纲化处理,得到标准数据。
最后,绘制出各指标数据的变化规律图像。通过观察各指标与“数字经济”板块的六项信息的曲线变化规律,建立皮尔逊相关系数模型,确定各项指标与上述六项信息的相关性数值。将六项信息与各指标的相关系数排序,分别得到各指标对于开盘价、收盘价、最高价、最低价、成交量和成交额各项的影响程度。再计算出各指标对于上述六项信息的相关性系数的均值,舍去其中均值小于 0.6 的指标,仅保留强相关性和极强相关性的指标,从而得出与“数字经济”板块有关的主要指标。
具体思维流程图如下:
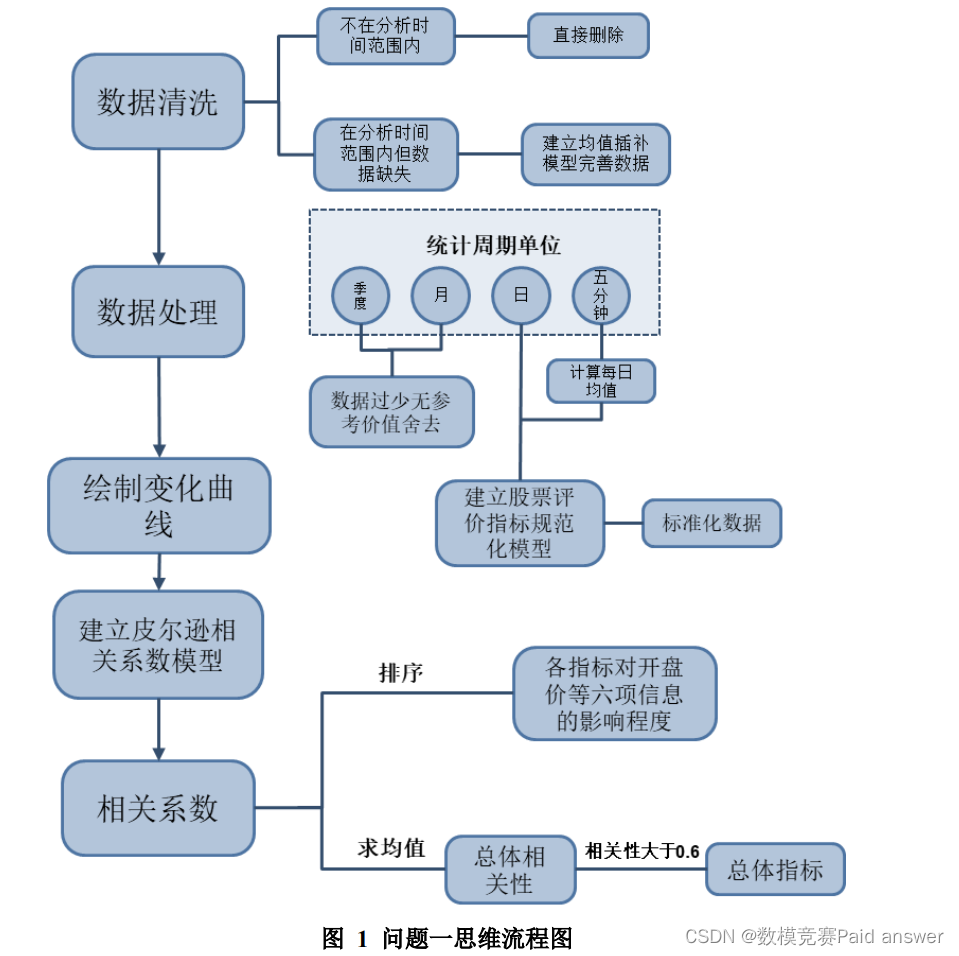
均值插补模型的建立

评价指标规范化模型的建立
为防止各项指标因数量级大小不同对分析造成影响,此处对各项指标的数据进行一致化、无量纲化处理。
评价指标规范化模型的建立
为防止各项指标因数量级大小不同对分析造成影响,此处对各项指标的数据进行一致化、无量纲化处理。

模型的求解
(一)将“数字经济”板块的六项信息分别看作单独的一类,计算各类每日的均值作为当日该类的平均水平进行分析,计算部分结果如下表:
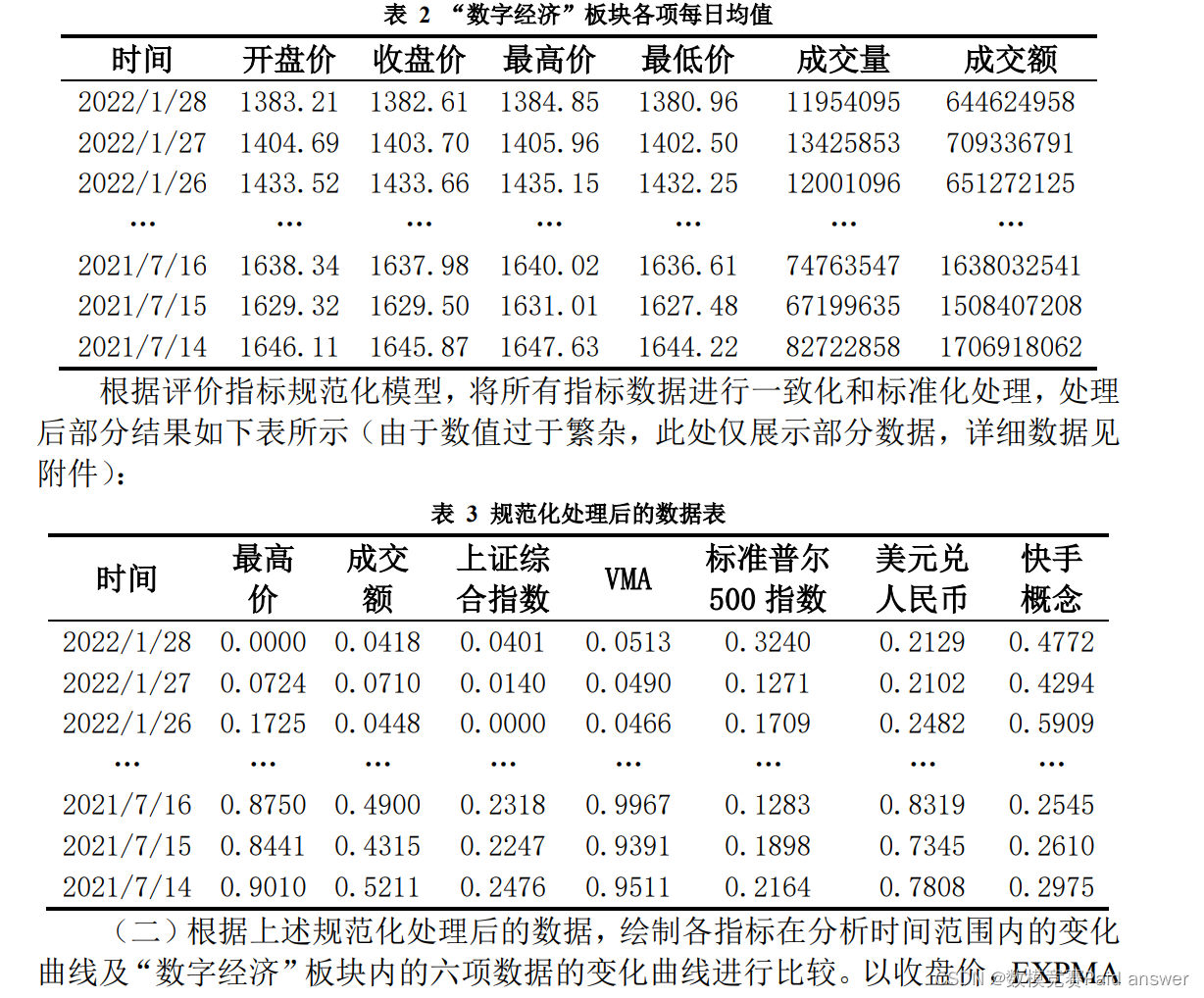
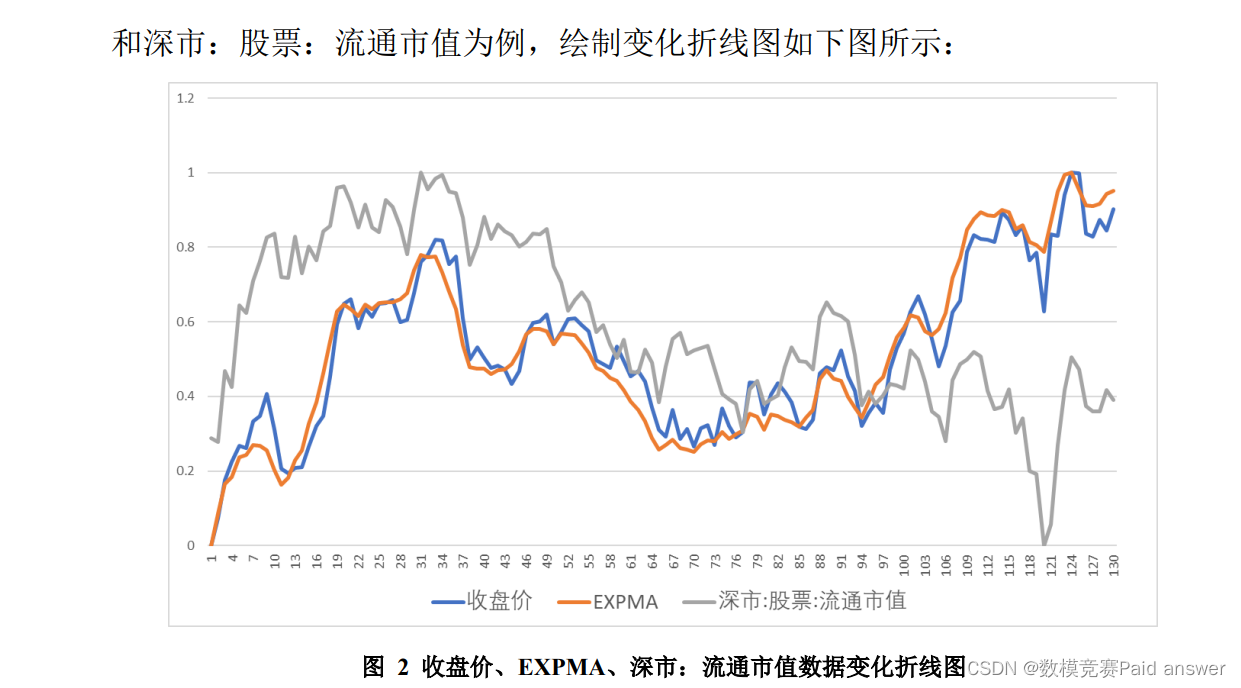

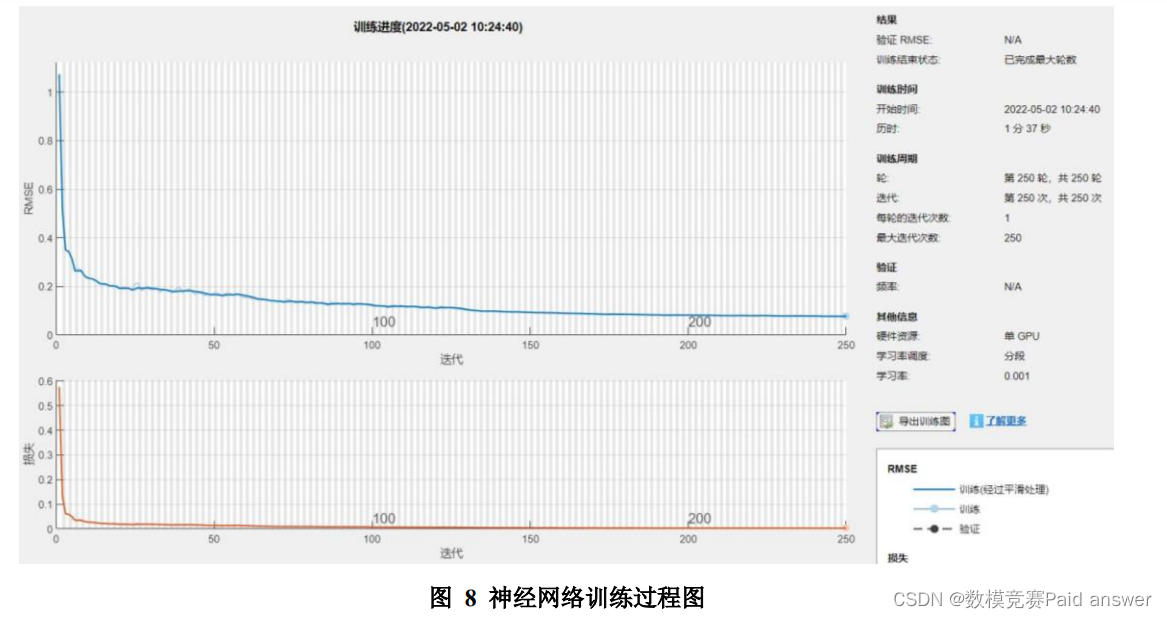
问题二要求根据问题一所提取的各项指标,使用 2021 年 7 月 14 日至 2021年 12 月 31 日的“数字经济”板块指数为训练集,对 2022 年 1 月 4 日至 2022年 1 月 28 日 “数字经济”板块指数每 5 分钟成交量进行预测。首先,根据问题一的分析,提取出了 VMA、VMACD、欧元兑美元等 12 项与“数字经济”板块相关性最强指标。因此,本问的预测将基于上述 12 项指标。根据预测数据的特点,本问选择建立基于 LSTM 神经网络的股票预测模型进行求解。通过查找相关数据可知,无法在股票交易当天就获知上述 12 项指标的全部当日数据。因此,对于神经网络的训练集,本文选用交易前一日的 12 项指标数据和交易当日的成交量作为一组训练数据。即以问题一中 2021 年 7 月 13日至 2021 年 12 月 30 日规范化处理后的指标数据为输入层特征值,以问题一中2021 年 7 月 14 日至 2021 年 12 月 31 日规范化处理后的每日每五分钟的成交量为输出值,对所建立的 LSTM 神经网络模型进行学习训练。神经网络通过学习得出 12 项指标与成交额之间的非线性映射关系,从而建立起该神经网络的输入输出关系。最后,将 2022 年 1 月 3 日至 2022 年 1 月 27日的指标数据作为输入,测试该神经网络得出 2022 年 1 月 4 日至 2022 年 1月 28 日每日每五分钟的股票成交量。构建 LSTM 神经网络模型,并将训练集输入,令该神经网络进行机器学习,该过程如下图所示:
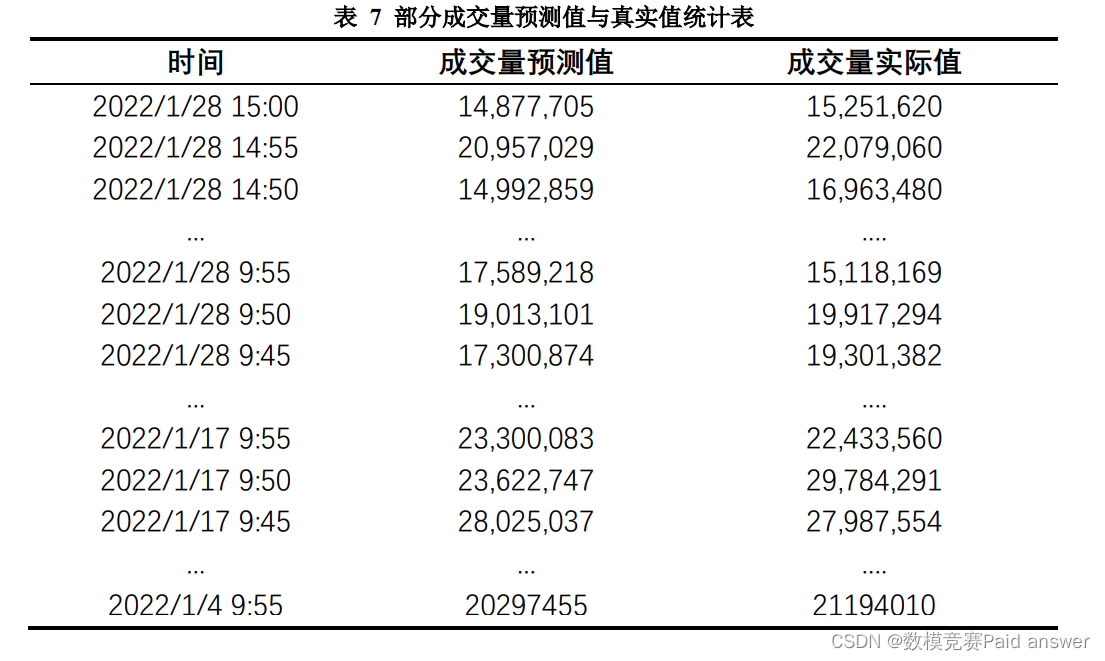
使用 2021 年 7 月 13 日至 2021 年 12 月 30 日的“数字经济”板块指数对基于 LSTM 神经网络的股票预测模型进行训练,从而得出 2022 年 1 月 4 日至 2022年 1 月 28 日“数字经济”板块指数每 5 分钟成交量的部分预测值如下表所示:

绘制成交量预测结果与真实值曲线对比图和训练数据测试结果残差图如下图所示:
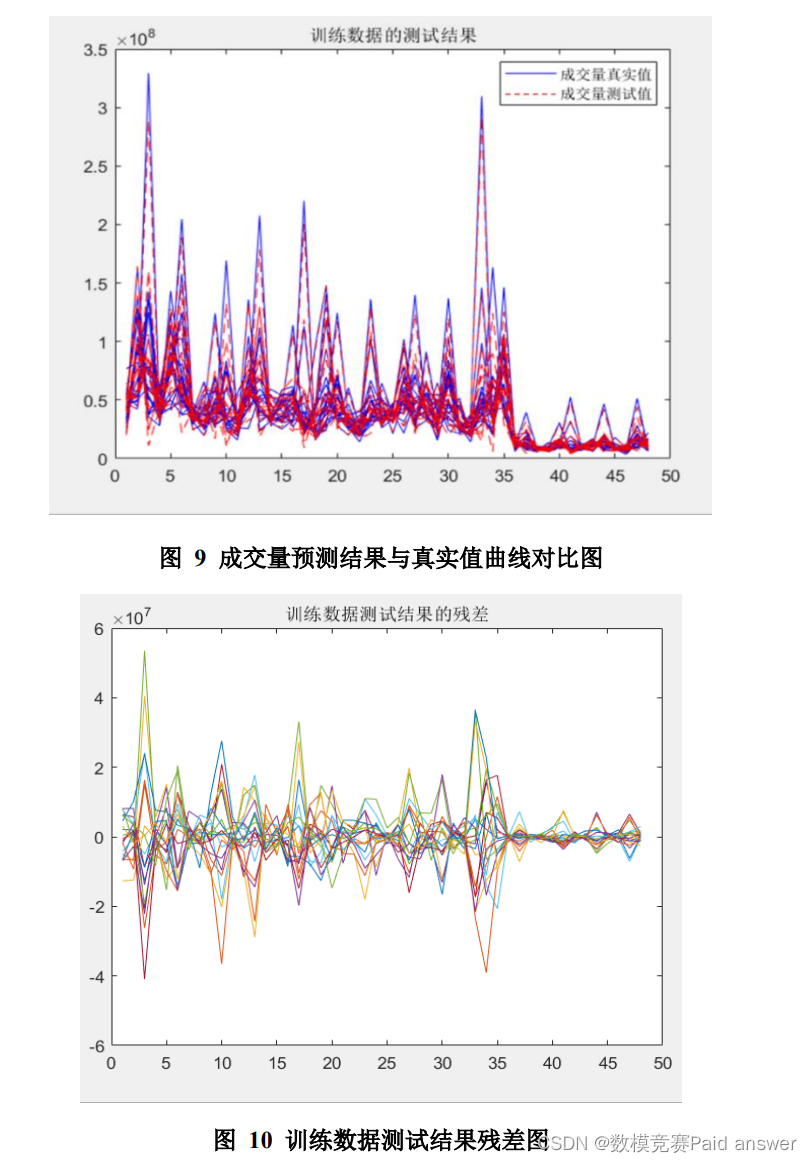
残差图中横坐标表示每天的 48 个五分钟,纵坐标表示测试结果的残差,不同颜色的折线则表示预测的 19 天数据。由上面两图可以看出,成交量的预测值与实际值十分接近,证明预测结果较为准确。
问题三需要在问题一和问题二所建立的数学模型的基础上,来预测每 5 分钟的“数字经济”板块指数的收盘价。本文可直接参考问题二所建立的 LSTM 神经网络模型,对未来一段时间的收盘价进行预测。

模型的求解
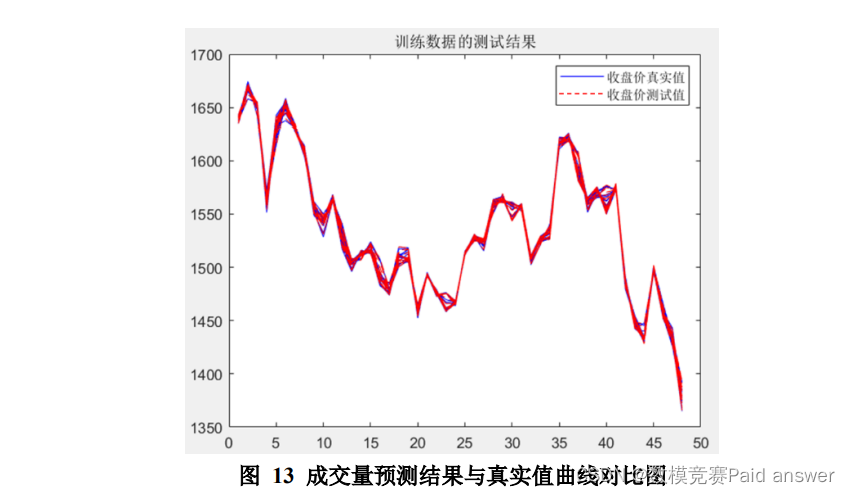
(一)根据问题要求以 2021 年 7 月 14 日至 2021 年 12 月 31 日的每 5 分钟“数字经济”板块指数为训练集,以 2022 年 1 月 4 日至 2022 年 1 月 28 日的每 5 分钟“数字经济”板块指数为测试集。训练集的天数与测试集的天数共 130 天,有10个主要指标影响着收盘价。将上述时间序列做成一个130×10的一个矩阵。将该矩阵按训练时间与测试时间划分,前 111 天作为训练集,训练完成后来预测后 19 天的收盘价。在 matlab 中建立一个 LSTM 神经训练网络如下图所示:

问题四要求根据问题三所得结果,以 100 万元为初始资金,0.3%为交易佣金,对“数字经济”板块指数进行交易。从而得出 2022 年 1 月 4 日至 2022 年 1 月28 日期间交易的总收益率、信息比率和最大回撤率。首先,利用问题三所得的2022 年 1 月 4 日至 2022 年 1 月 28 日,共 852 个“数字经济”板块收盘价数据,以 100 万元为初始资金,先对总收益率进行分析。由于每笔交易需支出 0.3%的佣金,同时考虑到一般投资者想尽可能多获利的心理。本文基于数据降维法,建立收益最大化模型,给出交易者最合理的投资策略,从而得到最大的投资总收益率。接着,根据题目所给公式计算出信息比率和最大回撤率,分别反映出一段时间内的收益和该股票的投资风险。
最后,利用题目所给的 2022 年 1 月 4 日至 2022 年 1 月 28 日的实际收盘价计算相应的总收益率、信息比率和最大回撤率,与使用预测值计算的结果相比较,从而得出预测值的准确性。
总收益率、信息比率、最大回撤率计算方法

模型基本结构如下图所示:
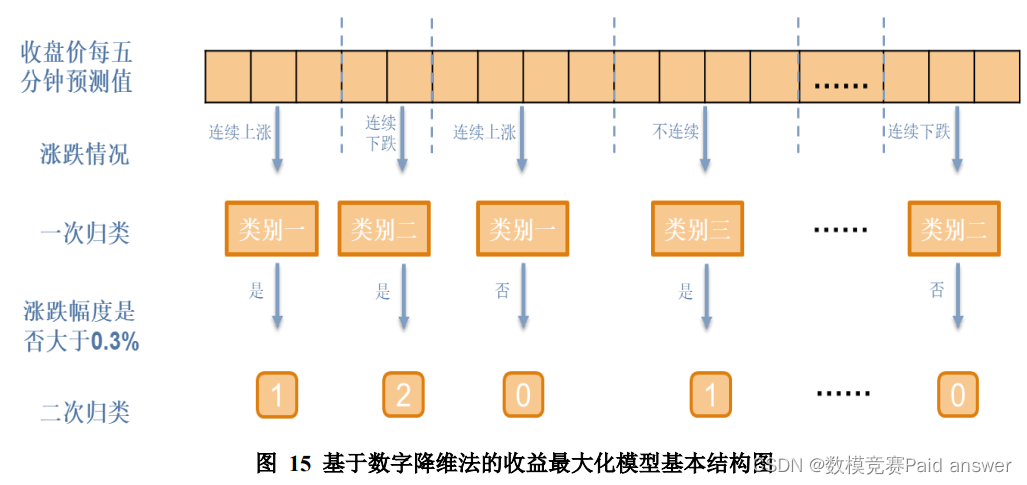
针对上述结果,采用高抛低吸法。以每一类别为一个阶段。若未来阶段收盘价上涨超过 0.3%则买入,下跌超过 0.3%则卖出,变化幅度低于 0.3%则持有。即1 表示买入,2 表示卖出,0 表示持有。
模型的求解
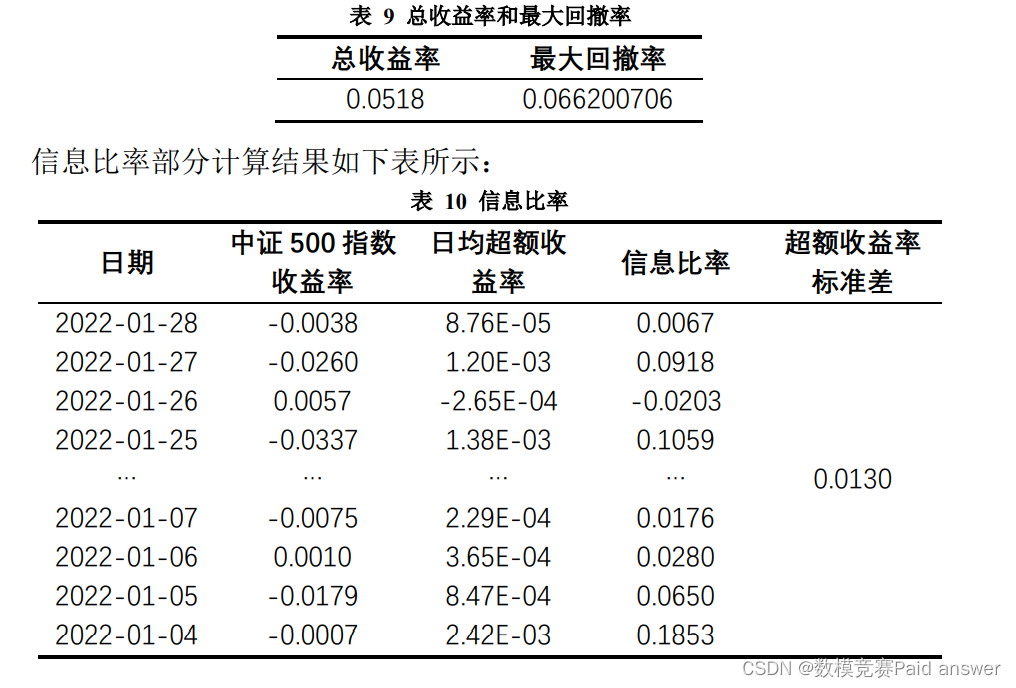
(一)首先,根据上述模型,利用问题三所得数据对总收益率和最大回撤率进行计算,计算部分结果如下表所示:
(二)根据真实值数据对总收益率和最大回撤率进行计算,计算部分结果如下表所示:
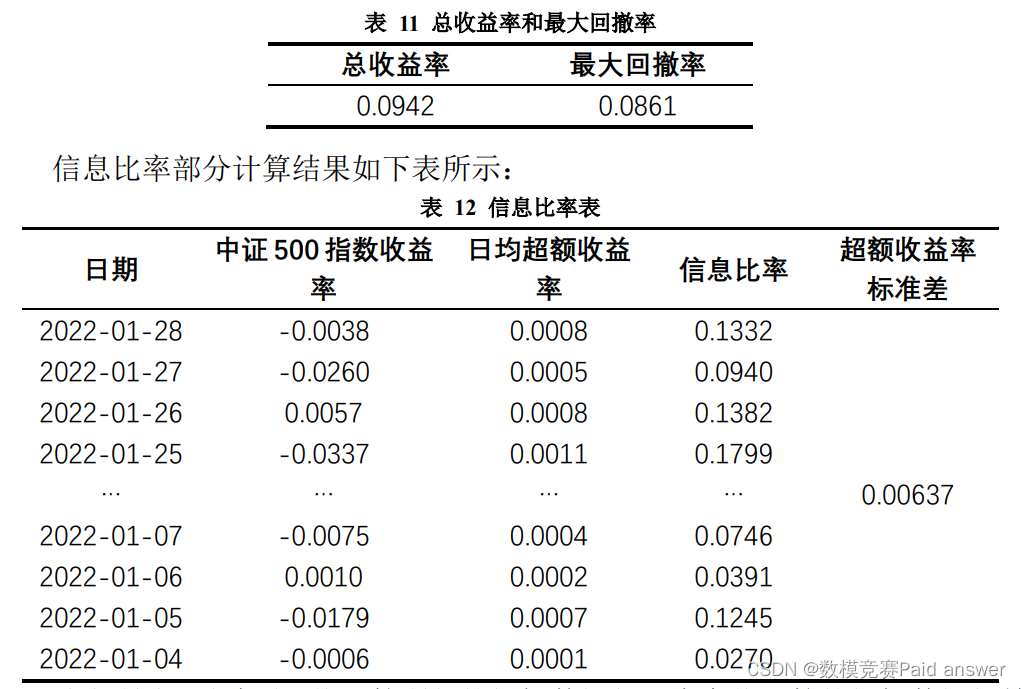
综上所述,通过预测值计算所得的指标数据与用真实值计算的指标数据相差不大,且总收益率相对较高,最大回撤率较低。由此可反映出问题二、三中建立的预测模型和本文中建立的组合交易模型的优良性。
论文缩略图:


程序代码:
k=1; %排序收盘价训练集
for i=1:130 %导入各个指标
for j=1:48
D1(k,1)=X1(i,1); D2(k,1)=X2(i,1);
D3(k,1)=X3(i,1); D4(k,1)=X4(i,1);
D5(k,1)=X5(i,1); D6(k,1)=X6(i,1);
D7(k,1)=X7(i,1); D8(k,1)=X8(i,1);
D9(k,1)=X9(i,1); D10(k,1)=X10(i,1);
k=k+1;
end
end
k=1; %排序成交量训练集
for i=1:130
for j=1:48
W1(k,1)=Y1(i,1); W2(k,1)=Y2(i,1);
W3(k,1)=Y3(i,1); W4(k,1)=Y4(i,1);
W5(k,1)=Y5(i,1); W6(k,1)=Y6(i,1);
W7(k,1)=Y7(i,1); W8(k,1)=Y8(i,1);
W9(k,1)=Y9(i,1); W10(k,1)=Y10(i,1);
W11(k,1)=Y11(i,1); W12(k,1)=Y12(i,1);
k=k+1;
end
end
j=1; %求上下反转各个训练集
for i=6240: -1:1
L1(j,1)=D1(i,1); L2(j,1)=D2(i,1);
L3(j,1)=D3(i,1); L4(j,1)=D4(i,1);
L5(j,1)=D5(i,1); L6(j,1)=D6(i,1);
L7(j,1)=D7(i,1); L8(j,1)=D8(i,1);
L9(j,1)=D9(i,1); L10(j,1)=D10(i,1);
M1(j,1)=W1(i,1); M2(j,1)=W2(i,1);
M3(j,1)=W3(i,1); M4(j,1)=W4(i,1);
M5(j,1)=W5(i,1); M6(j,1)=W6(i,1);
M7(j,1)=W7(i,1); M8(j,1)=W8(i,1);
M9(j,1)=W9(i,1); M10(j,1)=W10(i,1);
M11(j,1)=W11(i,1); M12(j,1)=W12(i,1);
C(j,1)=CG(i,1); S(j,1)=SP(i,1); j=j+1;
end
%预测代码
load 'T1';%时间序列
load 'T';%目标序列
A=T; B=T1; x=A'; y=B';
[d,mse1,test_ty]=shengjingwangluo(x,y)
yuce=test_ty;
D=d; M=mse1;
disp('预测值') yuce
disp('均方误差')
function [d,mse1,test_ty]=shengjingwangluo(x,y)
trainx =x; trainy =y;
[ww,mm]=size(trainx); testx = x;
%% 创建神经网络
% 包含 15 个神经元,训练函数为 traingdx
net=elmannet(1:2,15,'traingdx');
% 设置显示级别
net.trainParam.show=1;
% 最大迭代次数为 10000 次
net.trainParam.epochs=1000;
% 误差容限,达到此误差就可以停止训练
net.trainParam.goal=0.00001;
% 最多验证失败次数
net.trainParam.max_fail=5;
% 对网络进行初始化
net=init(net);
%% 网络训练
%训练数据归一化
[trainx1, st1] = mapminmax(trainx);
[trainy1, st2] = mapminmax(trainy);
% 测试数据做与训练数据相同的归一化操作
testx1 = mapminmax('apply',testx,st1);
% 输入训练样本进行训练
[net,per] = train(net,trainx1,trainy1);
%% 测试。输入归一化后的数据,再对实际输出进行反归一化
% 将训练数据输入网络进行测试
train_ty1 = sim(net, trainx1);
train_ty = mapminmax('reverse', train_ty1, st2);
% 将测试数据输入网络进行测试
test_ty1 = sim(net, testx1);
test_ty = mapminmax('reverse', test_ty1, st2);
%% 显示结果
% 1.显示训练数据的测试结果
figure(1)
x=1:length(train_ty);
% 显示真实值
plot(x,trainy,'b-');
hold on
% 显示神经网络的输出值
plot(x,train_ty,'r--')
legend('收盘价真实值','收盘价测试值')
title('训练数据的测试结果');
% 显示残差
figure(2)
plot(x, train_ty - trainy)
title('训练数据测试结果的残差')
% 显示均方误差
%mse1 = mse(train_ty - trainy);
%fprintf(' mse = \n %f\n', mse1)
% 显示相对误差
disp(' 相对误差:')
d=(train_ty - trainy)./trainy;
fprintf('%f ', (train_ty - trainy)./trainy );
fprintf('\n')
% 显示预测值
disp(' 预测值:')
fprintf('%f ', test_ty );
fprintf('\n')
mse1 = mse(train_ty - trainy);
fprintf(' mse = \n %f\n', mse1)
获取论文及程序见最下方