HD-VILA-100M是什么?
HD-VILA-100M是一个大规模、高分辨率、多样化的视频语言数据集,有助于多模态表示学习。

数据统计
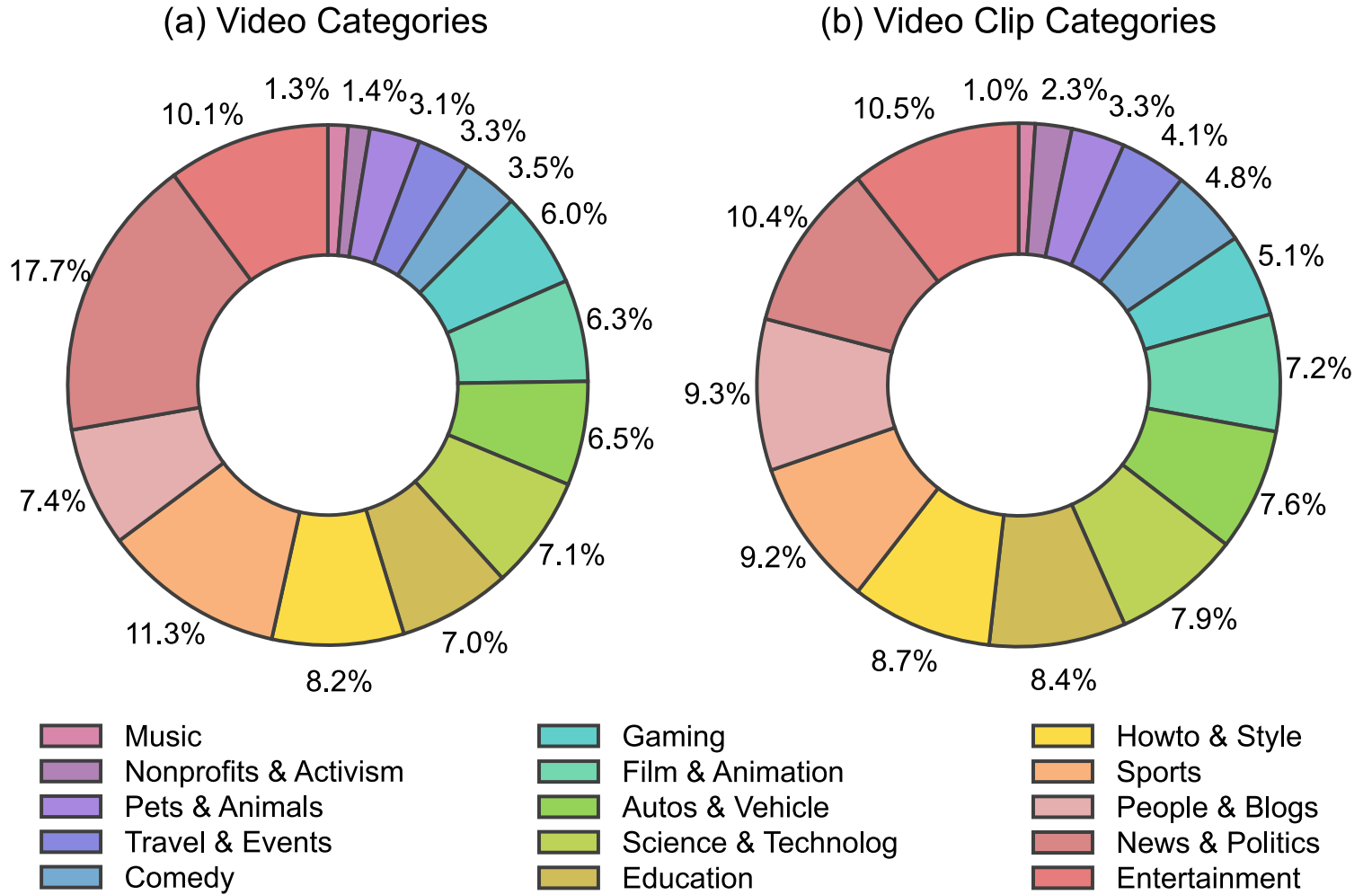
该数据集共包含330万个视频,视频质量较高,均衡分布在15个类别中。
下载(Download)
您可以通过此链接下载所有视频链接:视频链接。
原始视频下载:
您可以根据上面的视频链接使用 下面代码 从 YouTube 下载原始视频
下载原始视频使用的是youtube-dl这个命令行下载工具,需要注意版本和补丁问题,这里提供了大部分youtube-dl运行问题和速度慢等解决方案:https://github.com/ytdl-org/youtube-dl/issues/30839
from joblib import Parallel, delayed
import multiprocessing
import youtube_dl
import jsonlines
import json
import argparse
from tqdm import tqdm
import time
import os
import logging
from urllib.request import urlopen
def parse_args():
parser = argparse.ArgumentParser(description='youtube video downloader')
parser.add_argument('--workdir', default='hdvila_100m',type=str, help='Working Directory')
parser.add_argument('--metafile', default='hdvila_part0.jsonl', type=str, help='youtube video meta')
parser.add_argument('--log', default='log_part0.log', type=str, help='log')
parser.add_argument('--audio_only', action='store_true')
args = parser.parse_args()
return args
def check_dirs(dirs):
if not os.path.exists(dirs):
os.makedirs(dirs, exist_ok=True)
print(f'no path{dirs}')
else:
print(f'exists: {dirs}')
class YouTubeVideoDownloader():
def __init__(self, metafile, workdir):
self.videourls = self.readvideourls(metafile)
self.workdir = workdir
def readvideourls(self, metafile):
vs = []
with open(metafile,'r') as f:
for l in jsonlines.Reader(f):
vs.append(l['url'])
logger.info('Number of videos to download: %d', len(vs))
return vs
def downloadvideo(self,vurl):
format_id='22' # for 720p videos with audio
if args.audio_only:
format_id='140' # audio_only
ydl_opts = {
'outtmpl':os.path.join(self.workdir, 'download_videos') +'/%(id)s.%(ext)s',
'merge_output_format':'mp4',
'format':format_id, # 720P
'skip_download':False,
'ignoreerrors':True,
'quiet':True
}
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
start = time.time()
result = ydl.download([vurl])
end = time.time()
if result != 0:
logger.error('Fail to download %s', vurl)
logger.info('Time for download video %.2f sec', end-start)
return result
def downloadallParallel(self):
num_cores = multiprocessing.cpu_count()
logger.info(f"num cores: {num_cores}")
results = Parallel(n_jobs=50, backend='threading')(delayed(self.downloadvideo)(v) for v in tqdm(self.videourls))
results = [x for x in results if x is not None]
logger.info(f"Number of videos downloaded: {len(results)}")
if __name__ == '__main__':
args = parse_args()
metafile = os.path.join(args.workdir, 'metafiles', args.metafile)
logdir = os.path.join(args.workdir,'download_video_log')
check_dirs(os.path.join(args.workdir, 'download_videos'))
check_dirs(logdir)
logging.basicConfig(level=logging.INFO,
filename=os.path.join(logdir, args.log),
datefmt='%Y/%m/%d %H:%M:%S',
format='%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(module)s - %(message)s')
logger = logging.getLogger(__name__)
logger.info(args)
yvd = YouTubeVideoDownloader(metafile, args.workdir)
yvd.downloadallParallel()
youtube访问过高有ip反爬,可以通过修改下面代码设置代理ip:
import youtube_dl
# 设置代理IP
proxy_ip = 'YOUR_PROXY_IP_ADDRESS'
proxy_port = 'YOUR_PROXY_PORT'
# 创建ydl_opts字典并设置代理
ydl_opts = {
'proxy': f'http://{proxy_ip}:{proxy_port}',
}
# 使用带有代理设置的YoutubeDL对象
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
# 在这里添加您的代码逻辑
pass
视频剪切为剪辑
import jsonlines
import os
from tqdm import tqdm
import logging
import argparse
import re
import subprocess
import multiprocessing
from joblib import Parallel, delayed
def parse_args():
parser = argparse.ArgumentParser(description='youtube video processing')
parser.add_argument('--workdir', default='./hdvila_100m',type=str, help='Working Directory')
parser.add_argument('--metafile', default='meta_part0.jsonl', type=str, help='youtube video meta')
parser.add_argument('--resultfile', default='cut_part0.jsonl', type=str, help='processed videos')
parser.add_argument('--log', default='log_part0.log', type=str, help='log')
args = parser.parse_args()
return args
def check_dirs(dirs):
if not os.path.exists(dirs):
os.makedirs(dirs, exist_ok=True)
class Cutvideos():
def __init__(self, metafile, workdir, resultfile):
self.workdir = workdir
self.metafile = metafile
self.resultfile = resultfile
self.metas = self.loadmetas()
def loadmetas(self):
metas = []
with open(self.metafile, 'r') as f:
for l in jsonlines.Reader(f):
metas.append(l)
return metas
def hhmmss(self, timestamp1, timestamp2):
hh,mm,s = timestamp1.split(':')
ss,ms = s.split('.')
timems1 = 3600*1000*int((hh)) + 60*1000*int(mm) + 1000*int(ss) + int(ms)
hh,mm,s = timestamp2.split(':')
ss,ms = s.split('.')
timems2 = 3600*1000*int((hh)) + 60*1000*int(mm) + 1000*int(ss) + int(ms)
dur = (timems2 - timems1)/1000
return str(dur)
def run(self, cmd):
proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
out, _ = proc.communicate()
return out.decode('utf-8')
def extract_single_clip(self,sb, in_filepath, out_filepath):
cmd = ['ffmpeg', '-ss', sb[0], '-t', self.hhmmss(sb[0], sb[1]),'-accurate_seek', '-i', in_filepath, '-c', 'copy',
'-avoid_negative_ts', '1', '-reset_timestamps', '1',
'-y', '-hide_banner', '-loglevel', 'panic', '-map', '0',out_filepath]
self.run(cmd)
if not os.path.isfile(out_filepath):
raise Exception(f"{out_filepath}: ffmpeg clip extraction failed")
def extract_clips(self, meta):
clips = meta['clip']
vid = meta['video_id']
outfolder = os.path.join(self.workdir,'video_clips', vid)
check_dirs(outfolder)
result = []
# try:
for c in clips:
self.extract_single_clip(c['span'], os.path.join(self.workdir,'download_videos', vid + '.mp4'), os.path.join(outfolder, c['clip_id']))
result.append(c['clip_id'])
# except:
# pass
return result
def extract_all_clip(self):
results = []
for v in tqdm(self.metas):
result = self.extract_clips(v)
results.extend(result)
logger.info(f"Number of clips processed: {len(results)}")
with jsonlines.open(os.path.join(self.workdir, 'cut_video_results', self.resultfile), 'w') as f:
for l in results:
f.write(l)
if __name__ == '__main__':
args = parse_args()
metafile = os.path.join(args.workdir, 'metafiles', args.metafile)
logdir = os.path.join(args.workdir,'cut_video_log')
check_dirs(os.path.join(args.workdir, 'video_clips'))
check_dirs(os.path.join(args.workdir, 'cut_video_results'))
check_dirs(logdir)
logging.basicConfig(level=logging.INFO,
filename=os.path.join(logdir, args.log),
datefmt='%Y/%m/%d %H:%M:%S',
format='%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(module)s - %(message)s')
logger = logging.getLogger(__name__)
logger.info(args)
cvd = Cutvideos(metafile, args.workdir, args.resultfile)
cvd.extract_all_clip()
如果您发现该数据集对您的研究有用,请记得点赞关注收藏!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)