官方文档
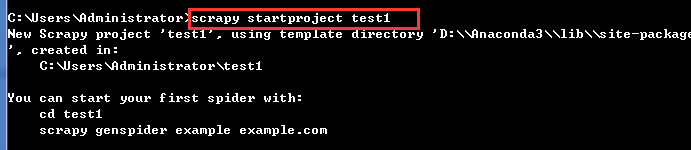
1.创建项目:
scrapy startproject myproject [project_dir]
这将在project_dir目录下创建一个Scrapy项目。如果project_dir没有指定,project_dir将与myproject同名。
接下来,进入新项目目录:
cd project_dir

2.创建爬虫
scrapy genspider mydomain mydomain.com

可用的工具命令
我们始终可以通过运行以获取有关每个命令的更多信息:
scrapy <command> -h
你可以看到所有可用的命令:
scrapy -h
有两种命令,一种只能在Scrapy项目内部工作(特定于项目的命令)和那些在没有活动的Scrapy项目(全局命令)的情况下工作的命令,尽管从项目内部运行时它们可能表现略有不同(因为他们会使用项目覆盖设置)。
全局命令:
(没有项目时也可以使用)
创建爬虫:
scrapy genspider [-t template] <name> <domain>
列出创建spider所有可用模板 :
scrapy genspider -l
指定模板生成spider :
scrapy genspider -t crawl zhihu www.zhihu.com
可以从下图看到,py文件中使用了一个模板:

scrapy fetch <url>

仅限项目的命令:
(只能在有项目存在的情况下使用)
-
crawl
运行爬虫,后面的参数是spider的名称——
scrapy crawl spider

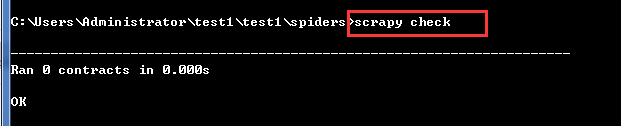
scrapy check