1、post请求
首先从浏览器打开百度翻译,去抓一下接口
右键检查,一开始是network是什么都没有的,如果有,那是你操作步骤快了,抓的信息是网页的信息

然后随便输入一些东西,发现network中多了一些内容,这就是抓到的东西,这里的相关的信息,比如请求方式啊,状态码等等
嗯~既然说到了,就简单介绍一下,当是复习了
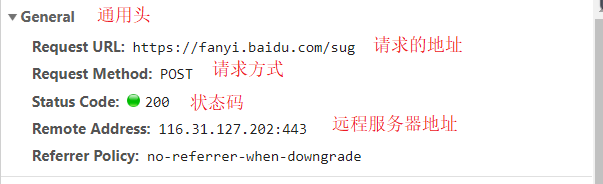
首先这第一个接口,Headers栏这里返回了四大模块:
-
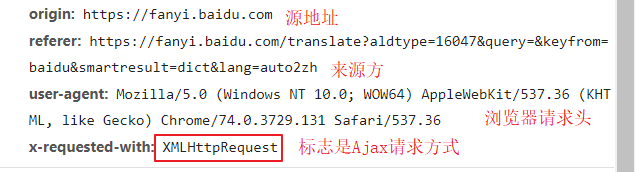
通用头:响应头和请求头中都有的东西
- 响应头
- 请求头
-
表单数据:这里表单数据直接显示出来了,就先介绍,kw(keyword) 也就是关键字,我们搜索只输了一个字母a

然后看一下具体的


2、通过scrapy框架用爬虫发起post请求
首先在黑屏终端使用命令,创建一个项目
scrapy startproject PostDemo
然后使用pycharm打开该项目,在pycharm的Terminal终端输入命令,新建一个爬虫
scrapy genspider fanyi fanyi.baidu.com
当爬虫文件创建后,有start_urls这个字段
引擎调度起来以后,首先创建完爬虫对象以后,会从start_urls里面取出起始url
放入调度器来调度,调度器调度的时候默认发起的是get请求(调度器默认创建的是get请求的下载器)
若要post请求,则需注释start_urls
接下来如果要发起post请求,首先要重写一个周期函数发起post请求
就以上面百度翻译为例,发起一个post请求,输在翻译栏入一个a,我们上面已经抓到过这个接口

这个接口返回的数据是一个json字符串

现在用爬虫的scrapy框架来发起这个post请求
fanyi .py
# -*- coding: utf-8 -*-
import scrapy
class FanyiSpider(scrapy.Spider):
name = 'fanyi'
allowed_domains = ['fanyi.baidu.com']
# start_urls = ['http://fanyi.baidu.com/']
#引擎调度起来以后,首先创建完爬虫对象以后,会从start_urls里面取出起始url
# 放入调度器来调度,调度器调度的时候默认发起的是get请求(调度器默认创建的是get请求的下载器)
# 若要post请求,则需注释start_urls
# 如果要发起post请求,首先要重写一个周期函数(这是一个回调函数)
def start_requests(self):
#这个周期函数,下载器开始下载数据的时候被调用
print('下载器开始请求网络.....')
post_url = 'http://fanyi.baidu.com/sug'
#创建表单数据
data ={
'kw':'a'
}
#现在可以在这个方法中截获调度器的调度,把调度器创建get请求的操作变成创建post请求对象
#scrapy 的下载器常用的有两种,Request对象和FormRequest对象,分别用于处理get和post请求
#发起post请求
yield scrapy.FormRequest(url=post_url,formdata=data,callback=self.parse_post)
#需要定义一个被调函数,用于传递给post下载器对象,让post对象去调用
def parse_post(self, response):
# 下载器(get下载器和post下载器)的回调函数,都要求传递一个参数去接收响应对象
print(response.text)
爬虫文件写好就完了吗?

当然没那么简单
还需要在setting .py文件中修改请求头,将robot协议改为不遵循
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
ROBOTSTXT_OBEY = False
然后,在pycharm终端输入命令
scrapy crawl fanyi
如果Terminal终端有json字符串,说明这个post请求成功

那么学会这个有什么用呢?

好嘞,接下来了解一下比较复杂的post请求,看一下怎么用scrapy破解验证码,登录网站,以以前爬取过的古诗文网站为例
https://www.gushiwen.org/
3、使用Scrapy框架破解验证码

首先,再建一个爬虫文件
scrapy genspider gushiwen gushiwen.org
然后,在setting文件中将下载时延开启
DOWNLOAD_DELAY = 3
由于我们需要用get请求获取登陆页的接口,所以这里的start_url不用再注释了,因为我们需要根据这个get请求回来的登录页的数据发起post请求
把start_url改为登陆页面的url
然后,这时候,回想以前的破解验证码,都是要获取cookie的
那么这个…
scrapy框架中,setting文件下有这些代码

这个cookies是默认打开的,当然,你要是闲的,也可以改成这样
COOKIES_ENABLED = True
好了,其他不用管了,专心关注于爬虫文件就行了
- 首先,通过get请求要获取账户,密码,验证码这些接口

- 破解验证码
- 使用post方式提交数据
具体不多做解释了,代码也不难
gushiwen .py
# -*- coding: utf-8 -*-
import scrapy
import pytesseract
from PIL import Image
class GushiwenSpider(scrapy.Spider):
name = 'gushiwen'
allowed_domains = ['gushiwen.org']
start_urls = ['https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx']
def parse(self, response):
# 从登录页面中提取两个token和一个验证码
item = {}
# 验证码
item['code_url'] = "https://so.gushiwen.org" + response.xpath("//img[@id='imgCode']/@src").extract()[0]
# token
item["__VIEWSTATE"] = response.xpath("//input[@id='__VIEWSTATE']/@value").extract()[0]
item["__VIEWSTATEGENERATOR"] = response.xpath("//input[@id='__VIEWSTATEGENERATOR']").extract()[0]
# 创建一个get请求的下载器,去下载验证码
yield scrapy.Request(url=item["code_url"], callback=self.parse_code, meta={"item": item})
# response对象有一个属性叫做meta,用于记录响应的相关信息,这个meta属性可以自定义,在Request对象发起请求的时候可以提前把一些自定义meta配置写入
# 定义一个回调函数,用于处理下载完成验证码的数据
def parse_code(self, response):
print(
response.meta) # {'depth': 1, 'download_timeout': 180.0, 'download_slot': 'so.gushiwen.org', 'download_latency': 0.06549572944641113}
# 从上级页面的响应体中取出meta中的item信息
item = response.meta["item"]
# print(response.body)
# 将图片写入本地
with open("./code.png", 'wb') as fp:
fp.write(response.body)
# 识别验证码
code = self.identify_code("./code.png")
print(code)
# 发起post请求,去登录
# 登录接口
login_url = "https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx"
# 表单数据
data = {
'__VIEWSTATE': item['__VIEWSTATE'],
'__VIEWSTATEGENERATOR': item['__VIEWSTATEGENERATOR'],
'from': 'http://so.gushiwen.org/user/collect.aspx',
'email': 'fanjianbo666@163.com',
'pwd': '12345678',
'code': code, # 验证码每一次访问登录页面的时候都要刷新,所以要根据登录页面上的验证码进行写入
'denglu': '登录'
}
yield scrapy.FormRequest(url=login_url, formdata=data, callback=self.parse_login)
# 定义一个回调函数,用于处理登录接口的响应体
def parse_login(self, res):
print(res.text)
# 定义一个辅助用于识别验证码
def identify_code(self, filename):
img = Image.open(filename)
# 将图片转成灰度图片
img = img.convert("L")
# 将图片上的像素二值化,我们以某个临界值为基准,如果大于这个临界值就设置为255,小于就设置为0
data = img.load()
h, w = img.size
for i in range(h):
for j in range(w):
if data[i, j] > 100:
data[i, j] = 255
else:
data[i, j] = 0
# img.show()
s = pytesseract.image_to_string(img)
return s