背景:
目前公司业务需要统计超过7天以上的特征统计,但是kafka只存7天的数据,如果只想通过flink sql去计算30天的用户特征要求当天生效,这是完不成的,但是看到下面的分享,感觉未来的方向有了。
一、2021 Apache Flink Meetup - Hosted by Netflix 的youtobe视频分享
目前这是Netflix的分享,目前还未将backfilling 的功能贡献回 iceberg 社区
https://www.youtube.com/watch?v=rtz3p_iijP8&feature=youtu.be(第45分钟开始)
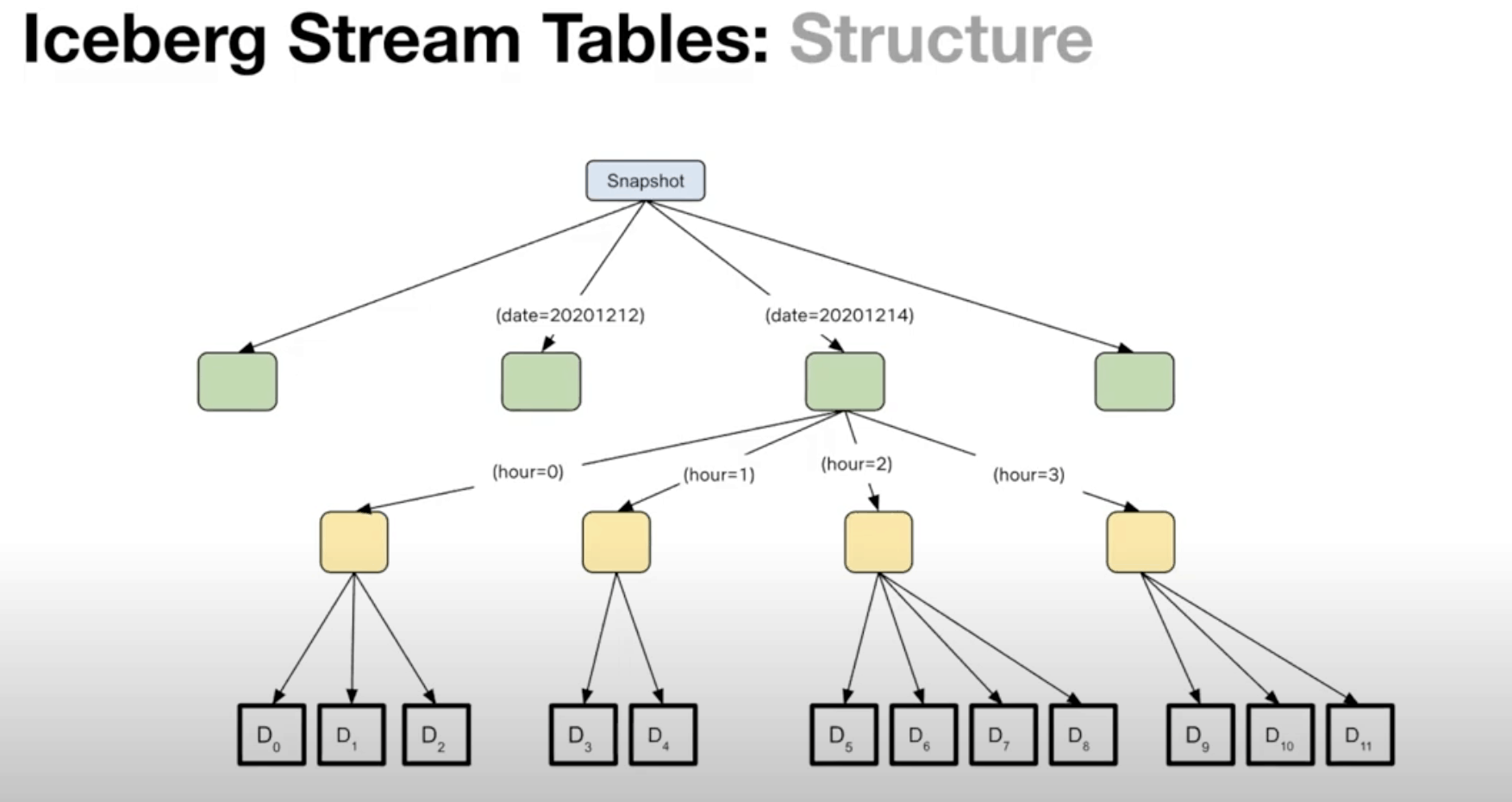
二、简单的截图分享(重点看第四点)
1、标题

2、提高流利用数据的存活时间
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gDutKmBv-1612260316010)(https://secure-static.wolai.com/static/gYWsDLFqQtkk91zogvqQ8Y/image.png)]
3、对比kafka和第三方存储的价格优势

4、Backfilling在Iceberg的使用,这个是重点,能够替代kafka存更多之前的数据,同时又能

5、Iceberg的流表结构