Abstract&Introduction&Related Work
- 研究任务
改进大模型遵循指令的能力,SELF-INSTRUCT提供了一种几乎无需注释的方法来使预训练语言模型与指令对齐
- 已有方法和相关工作
- 许多研究提出使用语言模型进行数据生成(Schick和Schütze,2021; Wang等,2021; Liu等,2022; Meng等,2023)或数据增强(Feng等,2021; Yang等,2020; Mekala等,2022)
- 知识蒸馏。知识蒸馏(Hinton等,2015; Sanh等,2019; West等,2021; Magister等,2022)通常涉及将大型模型的知识转移给较小的模型。SELF-INSTRUCT也可以被看作是一种“知识蒸馏”的形式,然而,它与知识蒸馏的区别在于:(1)蒸馏的源和目标是相同的,即模型的知识被蒸馏到自身;(2)蒸馏的内容以任务的形式存在(即定义任务的指令和一组实例)
- Bootstrapping with limited resources.:最近的一系列研究使用语言模型通过专门的方法进行自助引导。NPPrompt(Zhao等,2022)提供了一种方法,在没有进行微调的情况下生成语义标签的预测。它使用模型自身的嵌入来自动找到与数据样本标签相关的单词,从而减少了从模型预测到标签(verbalizers)的手动映射的依赖性。STAR(Zelikman等,2022)通过迭代地利用少量的含有理由的示例和大量不含理由的数据集,来引导模型进行推理能力的自助引导。Self-Correction(Welleck等,2023)将一个不完善的基础生成器(模型)与一个独立的校正器分开,后者学会迭代地纠正不完善的生成结果,并在基础生成器上展示了改进
- 面临挑战
收集指令数据代价很大并且多样性有限,
- 创新思路
- 使用模型自身的指令信号来调优预训练的语言模型。整个过程是一个迭代的自举算法
- 实验结论
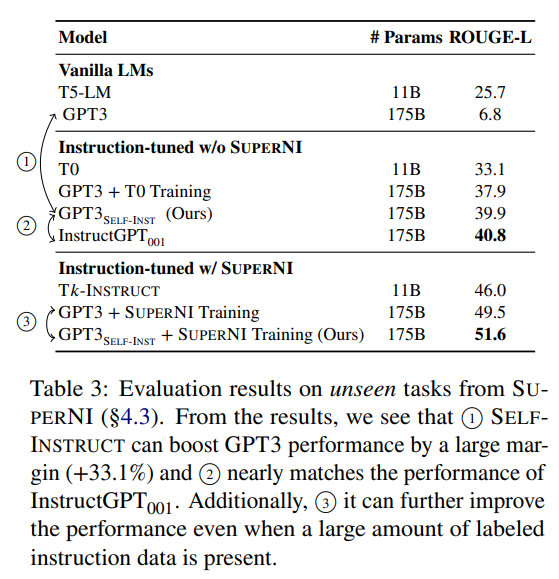
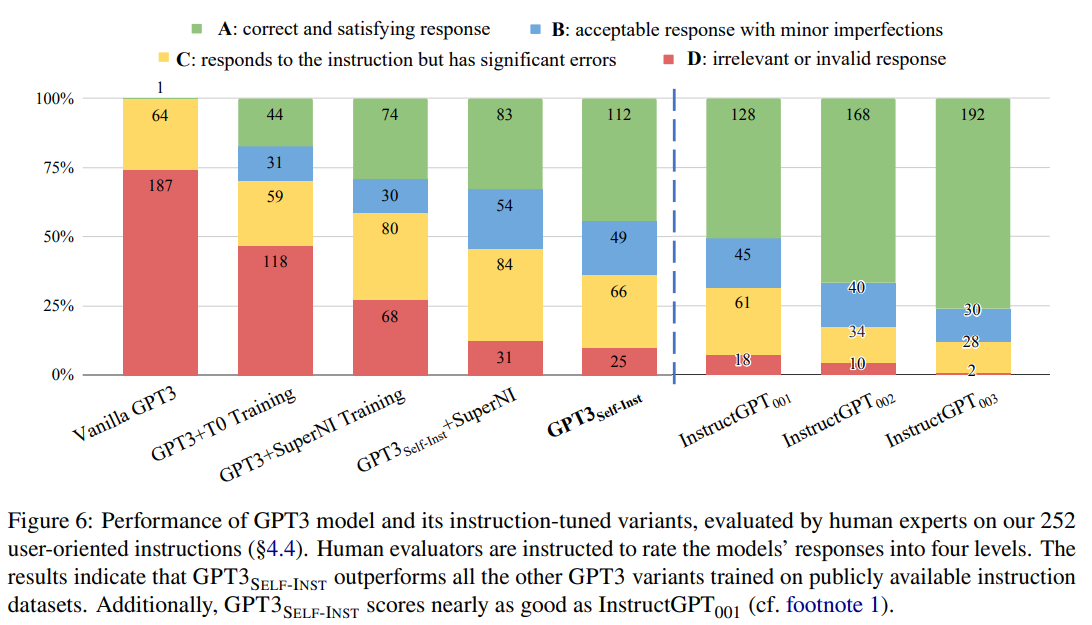
GPT3SELF-INST的性能大幅优于GPT3(原始模型)(+33.1%),并且几乎与InstructGPT001的性能相当
用GPT3生成的instructions
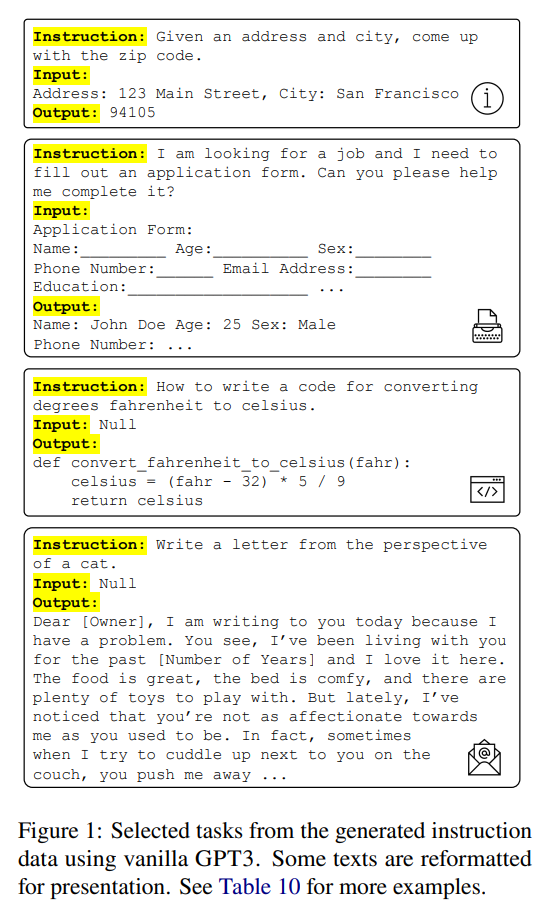
贡献:
(1) 我们引入了SELF-INSTRUCT,一种使用最少人工标记数据诱导指令遵循能力的方法;(2) 我们通过广泛的指令调优实验证明了其有效性;(3) 我们发布了一个大规模的合成数据集,包含52,000个指令,以及一组手动编写的新任务,用于构建和评估未来的指令遵循模型。
- 首先从一个有限的(比如研究中的175个)手动撰写的任务种子集开始,用于指导整体生成
- 在第一阶段,模型被提示为新任务生成instruction。这一步利用现有的指令集来创建更广泛覆盖的instruction,用于定义(通常是新的)任务
- 在得到新生成的指令集后,该框架还为它们创建输入-输出实例,这些实例可以在后续的指令调优过程中用于监督
- 最后在将低质量或重复的指令自动过滤掉之前,使用各种启发式方法将剩余的有效任务添加到任务池中。这个过程可以重复多次,直到获得大量任务

SELF-INSTRUCT是一种生成任务指令数据的方法,它使用预训练的普通语言模型自身来生成任务,经过过滤和调优,可以让模型更好地遵循指令。方法的流程包括定义指令数据、自动指令数据生成、过滤和后处理以及LM调优。
- 定义指令数据:指令数据包含一组指令,每个指令用自然语言描述一个任务,并包含对应的输入-输出实例。模型被期望根据指令和输入生成相应的输出
- 自动指令数据生成:使用自助引导的方式从一小组人工撰写的种子指令中生成新的指令。根据生成的指令是否表示分类任务,使用先输入后输出或先输出后输入的方法生成实例,并过滤低质量数据
- 过滤和后处理:为了鼓励多样性,只有当新的指令与已有指令的ROUGE-L相似度小于0.7时,才将新的指令添加到任务池中。同时,过滤掉完全相同或输入相同但输出不同的实例,并排除一些特定关键词的指令
- LM调优:使用创建的指令数据对原始LM进行微调,通过将指令和实例输入连接在一起进行监督训练,使模型更好地遵循指令。
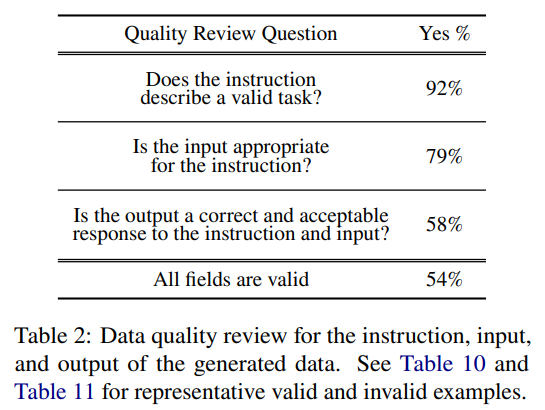
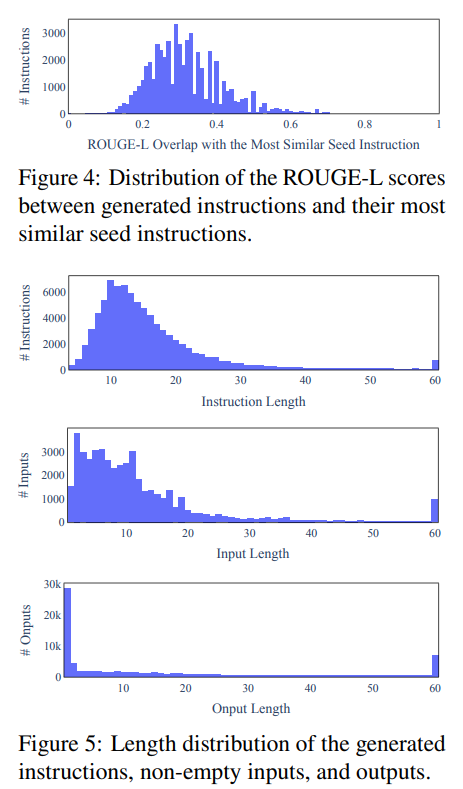
在应用SELF-INSTRUCT到GPT3的案例研究中,研究了生成数据的多样性和质量。生成的指令包含多样的意图和文本格式,与种子指令有较低的重叠。在质量方面,大部分生成的指令都是有意义的,生成的实例可能会包含一些噪声,但仍有用于训练模型遵循指令的价值
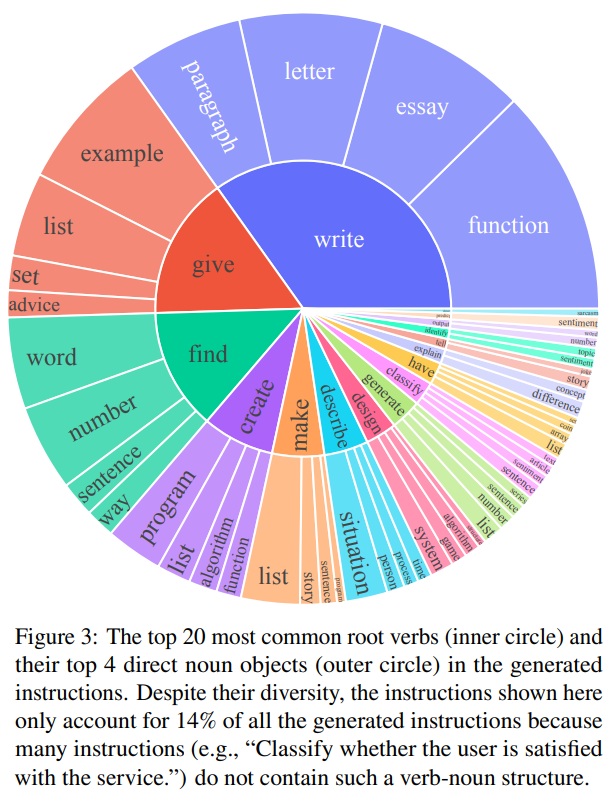
SELF-INSTRUCT方法通过自动生成指令和实例数据,克服了人工标注大规模指令数据的挑战。通过自我引导的方式,不断扩充任务池,生成更多的任务指令和实例,从而实现了大规模数据的生成。方法中提到使用多个模板来处理不同格式的指令和实例输入,这样能够提高模型的鲁棒性。生成的数据具有一定的多样性,涵盖了不同的意图和文本格式,这有助于提高模型的泛化能力。
在质量方面,生成的数据虽然可能存在一些噪声,但大多数仍然是正确格式或部分正确的,这为训练模型遵循指令提供了有用的指导。这意味着自动生成的数据虽然不完美,但仍然具有一定的实用性和可行性,为解决大规模任务指令数据标注的瓶颈问题提供了新的思路和方法。这对于推动自然语言处理领域的发展,特别是在通用模型和多任务学习方向上,具有重要的意义。然而,还需要进一步研究和改进,以提高自动生成数据的质量和适用性
Experiments
Conclusions
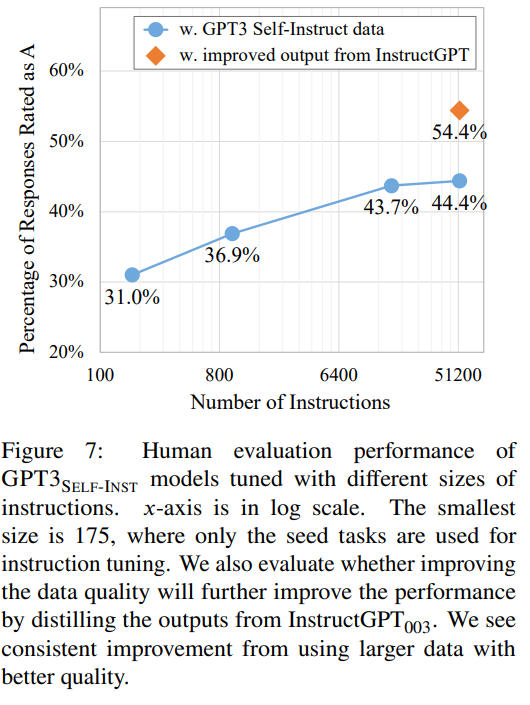
文章引入了SELF-INSTRUCT,一种通过其自己生成的指令数据来改进语言模型(LM)的遵循指令能力的方法。在对普通的GPT3进行实验后,我们自动生成了一个包含52,000个指令的大规模数据集,涵盖了多样化的任务。将GPT3在这个数据集上进行微调后,在SUPERNI任务上相对于原始的GPT3取得了33%的绝对改进。此外,我们策划了一组由专家撰写的用于新任务的指令。对这组数据进行人工评估显示,使用SELF-INSTRUCT微调的GPT3在性能上大幅优于使用现有公共指令数据集,并且接近于InstructGPT001的表现。我们希望SELF-INSTRUCT可以作为第一步,将预训练的语言模型与人类指令保持一致,未来的研究可以在此基础上继续改进遵循指令的模型。
Remark
一种有意思的用自监督来克服数据资源不够的困境的方法,期待后续工作改进