0x01. DoWhy案例分析
本案例依旧是基于微软官方开源的文档进行学习,有想更深入了解的请移步微软官网。
背景:
取消酒店预订可能有不同的原因。客户可能会要求一些无法提供的东西(例如,停车场),客户可能后来发现酒店没有满足他们的要求,或者客户可能只是取消了他们的整个旅行。其中一些问题,如停车,是酒店可以处理的,而另一些问题,如取消行程,则不在酒店的控制范围内。在任何情况下,我们都想更好地了解是哪些因素导致预订取消。
在本例中,我们的研究问题是估计当消费者在预定酒店时,为其分配一间与之前预定过的房间不同的房间对消费者取消当前预定的影响。分析此类问题的标准是 「随机对照试验」(Randomized Controlled Trials),即每位消费者被随机分配到两类干预中的一类:为其分配与之前预定过的房间相同或不同的房间。
我们考虑哪些因素会导致酒店预订被取消。简单经验思考如图:
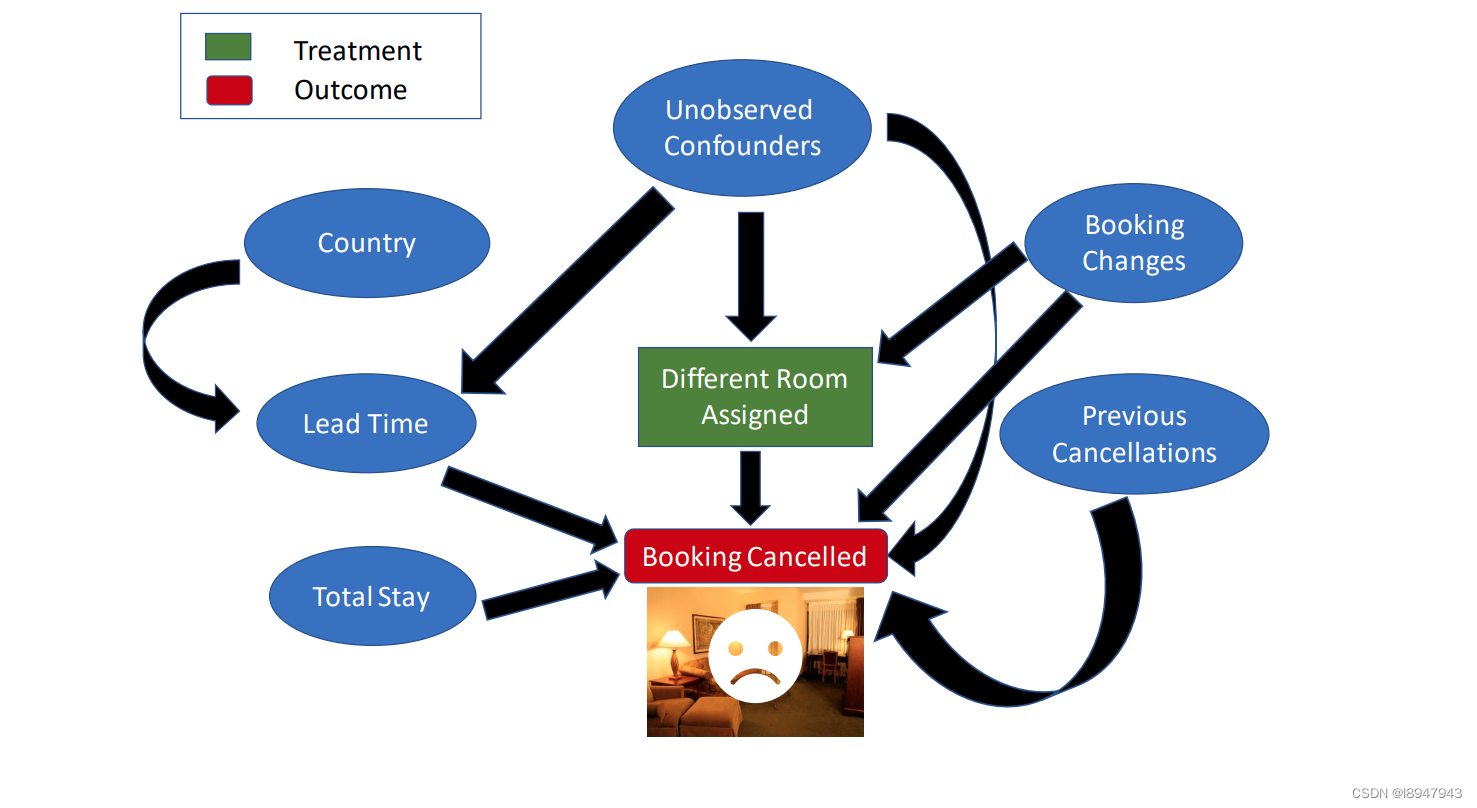
0x02. 实验走起
0x02_1. 导包读数据
有关数据的详细解释请参考:传送门
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import dowhy
dataset = pd.read_csv('https://raw.githubusercontent.com/Sid-darthvader/DoWhy-The-Causal-Story-Behind-Hotel-Booking-Cancellations/master/hotel_bookings.csv')
dataset.columns
该数据集包含如下列:
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'stays_in_weekend_nights',
'stays_in_week_nights', 'adults', 'children', 'babies', 'meal',
'country', 'market_segment', 'distribution_channel',
'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'reserved_room_type',
'assigned_room_type', 'booking_changes', 'deposit_type', 'agent',
'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date'],
dtype='object')
0x02_2. 数据处理
通过特征合并,减少原有特征维度,同时让数据更有使用价值,具体创建的数据如下:
-
Total Stay =
stays_in_weekend_nights + stays_in_week_nights
-
Guests =
adults + children + babies
-
Different_room_assigned = 1 if
reserved_room_type & assigned_room_type are different, 0 otherwise.
操作是基本的pandas操作,跟着实践就好。
# Total stay in nights
dataset['total_stay'] = dataset['stays_in_week_nights']+dataset['stays_in_weekend_nights']
# Total number of guests
dataset['guests'] = dataset['adults']+dataset['children'] +dataset['babies']
# Creating the different_room_assigned feature
dataset['different_room_assigned']=0
slice_indices =dataset['reserved_room_type']!=dataset['assigned_room_type']
dataset.loc[slice_indices,'different_room_assigned']=1
# Deleting older features
dataset = dataset.drop(['stays_in_week_nights','stays_in_weekend_nights','adults','children','babies'
,'reserved_room_type','assigned_room_type'],axis=1)
dataset.columns
数据的列经过处理后,变为:
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'meal', 'country', 'market_segment',
'distribution_channel', 'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'booking_changes', 'deposit_type',
'agent', 'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date', 'total_stay', 'guests',
'different_room_assigned'],
dtype='object')
接着处理空值等问题:
dataset.columns
#%%
dataset.isnull().sum() # Country,Agent,Company contain 488,16340,112593 missing entries
dataset = dataset.drop(['agent','company'],axis=1)
# Replacing missing countries with most freqently occuring countries
dataset['country']= dataset['country'].fillna(dataset['country'].mode()[0])
dataset = dataset.drop(['reservation_status','reservation_status_date','arrival_date_day_of_month'],axis=1)
dataset = dataset.drop(['arrival_date_year'],axis=1)
dataset = dataset.drop(['distribution_channel'], axis=1)
# Replacing 1 by True and 0 by False for the experiment and outcome variables
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(1,True)
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(0,False)
dataset['is_canceled']= dataset['is_canceled'].replace(1,True)
dataset['is_canceled']= dataset['is_canceled'].replace(0,False)
dataset.dropna(inplace=True)
print(dataset.columns)
dataset.iloc[:, 5:20].head(100)
数据输出结果入下:
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_month',
'arrival_date_week_number', 'meal', 'country', 'market_segment',
'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'booking_changes', 'deposit_type',
'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'total_stay', 'guests', 'different_room_assigned'],
dtype='object')
对那些没有使用押金的数据进行统计分析,观测他们是否取消了订单
dataset = dataset[dataset.deposit_type=="No Deposit"]
dataset.groupby(['deposit_type','is_canceled']).count()
结果如下:

对数据进行深拷贝:
dataset_copy = dataset.copy(deep=True)
0x02_3. 简单分析假设
数据预处理完成后,我们首先针对数据进行一定的分析,考察变量之间的关系。针对目标变量 is_cancelled 与 different_room_assigned ,我们随机选取 1000 次观测查看有多少次上述两个变量的值相同(即可能存在因果关系),重复上述过程 10000 次取平均,代码如下:
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset.sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
最终得出的期望频数是 518,即两个变量有约 50% 的时间是不同的,我们还无法判断其中的因果关系。下面我们进一步分析预约过程中没有发生调整时(即变量 booking_changes 为 0) 两个变量相等的期望频数:
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset[dataset["booking_changes"]==0].sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
得出的结果为492。随后我们再分析预约过程中发生调整时的期望频数:
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset[dataset["booking_changes"]>0].sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
结果变成了 663,与之前产生了明显的差异。我们可以不严谨地认为预约调整这一变量是一个「混杂因子」。类似地,我们对其他变量进行分析,并作出一些假设,作为因果推断的先验知识。DoWhy 并不需要完整的先验知识,未指明的变量将作为潜在的混杂因子进行推断。
0x03. 使用DoWhy来估计因果效应
使用因果分析四步进行结果分析,具体如下
0x03_1.创建因果图
本阶段无需创建完整的因果图,即使是部分图表也足够了,其余的可以由DoWhy来计算;我们将一些可能的假设翻译成因果图:
-
market_segment 有两种取值:“TA”指的是“旅行代理商”,“TO”指的是“旅游运营商”,所以它应该会影响提前时间lead_time(即预订和到达之间的天数)。
-
country 会决定一个人是否会提早预订(即影响 lead_time )以及其喜爱的食物(即影响 meal)。
-
lead_time 会影响预订的等待时间( days_in_waiting_list )。
- 预订的等待时间 days_in_waiting_list、总停留时间 total_stay 以及客人数量 guests 会影响预订是否被取消。
- 之前预订的取消情况 previous_bookings_not_canceled 会影响该顾客是否为is_repeated_guest;这两个变量也会影响预订是否被取消。
-
booking_changes 会影响顾客是否被分配到不同的房间,也会影响预订取消情况。
除了 booking_changes 这一混杂因子外,一定还存在着其他混杂因子,同时影响干预和结果。
import pygraphviz
causal_graph = """digraph {
different_room_assigned[label="Different Room Assigned"];
is_canceled[label="Booking Cancelled"];
booking_changes[label="Booking Changes"];
previous_bookings_not_canceled[label="Previous Booking Retentions"];
days_in_waiting_list[label="Days in Waitlist"];
lead_time[label="Lead Time"];
market_segment[label="Market Segment"];
country[label="Country"];
U[label="Unobserved Confounders",observed="no"];
is_repeated_guest;
total_stay;
guests;
meal;
hotel;
U->{different_room_assigned,required_car_parking_spaces,guests,total_stay,total_of_special_requests};
market_segment -> lead_time;
lead_time->is_canceled; country -> lead_time;
different_room_assigned -> is_canceled;
country->meal;
lead_time -> days_in_waiting_list;
days_in_waiting_list ->{is_canceled,different_room_assigned};
previous_bookings_not_canceled -> is_canceled;
previous_bookings_not_canceled -> is_repeated_guest;
is_repeated_guest -> {different_room_assigned,is_canceled};
total_stay -> is_canceled;
guests -> is_canceled;
booking_changes -> different_room_assigned; booking_changes -> is_canceled;
hotel -> {different_room_assigned,is_canceled};
required_car_parking_spaces -> is_canceled;
total_of_special_requests -> {booking_changes,is_canceled};
country->{hotel, required_car_parking_spaces,total_of_special_requests};
market_segment->{hotel, required_car_parking_spaces,total_of_special_requests};
}"""
基于上述因果图,构建模型:
model= dowhy.CausalModel(
data = dataset,
graph=causal_graph.replace("\n", " "),
treatment="different_room_assigned",
outcome='is_canceled')
model.view_model()
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
构建的结果如图:
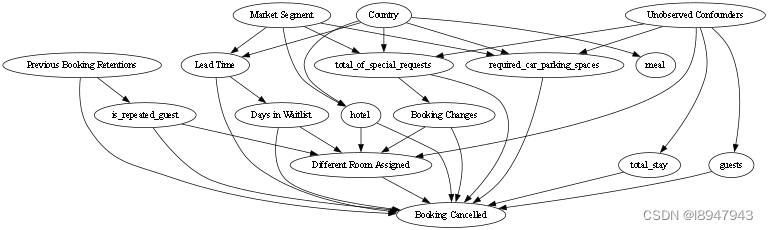
(PS:我也不知道这吊图怎么这么糊,出来就是这样)
0x03_2. 识别因果效应
我们称 干预(Treatment) 导致了结果(Outcome) 当且仅当在其他所有状况不变的情况下,干预的改变引起了结果的改变。因果效应即干预发生一个单位的改变时,结果变化的程度。下面我们将使用因果图的属性来识别因果效应的估计量。
identified_estimand = model.identify_effect()
print(identified_estimand)
输出结果如下:
Estimand type: nonparametric-ate
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
──────────────────────────(E[is_canceled|guests,booking_changes,days_in_waitin
d[different_room_assigned]
g_list,is_repeated_guest,hotel,lead_time,total_of_special_requests,required_car_parking_spaces,total_stay])
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,guests,booking_changes,days_in_waiting_list,is_repeated_guest,hotel,lead_time,total_of_special_requests,required_car_parking_spaces,total_stay,U) = P(is_canceled|different_room_assigned,guests,booking_changes,days_in_waiting_list,is_repeated_guest,hotel,lead_time,total_of_special_requests,required_car_parking_spaces,total_stay)
### Estimand : 2
Estimand name: iv
No such variable(s) found!
### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
0x03_3. 因果效应估计
基于估计量,下面我们就可以根据实际数据进行因果效应的估计了。如之前所述,因果效应即干预进行单位改变时结果的变化程度。DoWhy 支持采用各种各样的方法计算因果效应估计量,并最终返回单个平均值。代码如下所示:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification",target_units="ate")
# ATE = Average Treatment Effect
# ATT = Average Treatment Effect on Treated (i.e. those who were assigned a different room)
# ATC = Average Treatment Effect on Control (i.e. those who were not assigned a different room)
print(estimate)
输出结果如下:
*** Causal Estimate ***
## Identified estimand
Estimand type: nonparametric-ate
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
──────────────────────────(E[is_canceled|guests,booking_changes,days_in_waitin
d[different_room_assigned]
g_list,is_repeated_guest,hotel,lead_time,total_of_special_requests,required_car_parking_spaces,total_stay])
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,guests,booking_changes,days_in_waiting_list,is_repeated_guest,hotel,lead_time,total_of_special_requests,required_car_parking_spaces,total_stay,U) = P(is_canceled|different_room_assigned,guests,booking_changes,days_in_waiting_list,is_repeated_guest,hotel,lead_time,total_of_special_requests,required_car_parking_spaces,total_stay)
## Realized estimand
b: is_canceled~different_room_assigned+guests+booking_changes+days_in_waiting_list+is_repeated_guest+hotel+lead_time+total_of_special_requests+required_car_parking_spaces+total_stay
Target units: ate
## Estimate
Mean value: -0.23589558877628428
0x03_4. 反驳结果
实际上,上述因果并不是基于数据,而是基于我们所做的假设(即提供的因果图),数据只是用于进行统计学的估计。因此,我们需要验证假设的正确性。DoWhy 支持通过各种各样的鲁棒性检查方法来测试假设的正确性。下面进行其中几项测试:
-
添加随机混杂因子。如果假设正确,则添加随机的混杂因子后,因果效应不会变化太多。
refute1_results=model.refute_estimate(identified_estimand, estimate,
method_name="random_common_cause")
print(refute1_results)
结果如下:
Refute: Add a random common cause
Estimated effect:-0.23589558877628428
New effect:-0.2387463245344759
p value:0.19999999999999996
-
安慰剂干预。将干预替换为随机变量,如果假设正确,因果效应应该接近 0。
refute2_results=model.refute_estimate(identified_estimand, estimate,
method_name="placebo_treatment_refuter")
print(refute2_results)
结果如下:
Refute: Use a Placebo Treatment
Estimated effect:-0.23589558877628428
New effect:8.214081490552981e-05
p value:0.98
-
数据子集验证。在数据子集上估计因果效应,如果假设正确,因果效应应该变化不大。
refute3_results=model.refute_estimate(identified_estimand, estimate,
method_name="data_subset_refuter")
print(refute3_results)
结果如下:
Refute: Use a subset of data
Estimated effect:-0.23589558877628428
New effect:-0.23518131741789491
p value:0.8
可以看到,我们的因果模型基本可以通过上述几个测试(即取得预期的结果)。因此,根据估计阶段的结果,我们得出结论:当消费者在预定房间时,为其分配之前预定过的房间(different_room_assigned = 0 )所导致的平均预定取消概率( is_canceled )要比为其分配不同的房间( different_room_assigned = 1 )低 23%。
0x04. 参考
- 微软DoWhy官方教程之酒店预订案例实战
- 因果推断框架 DoWhy 入门