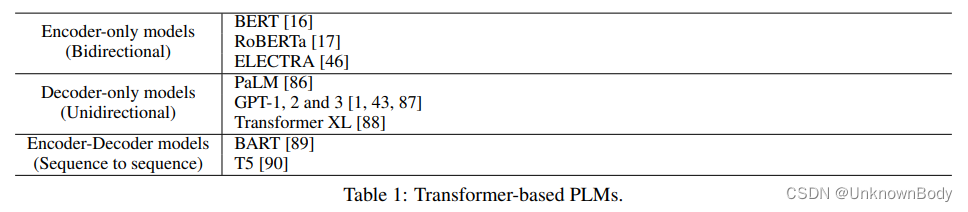
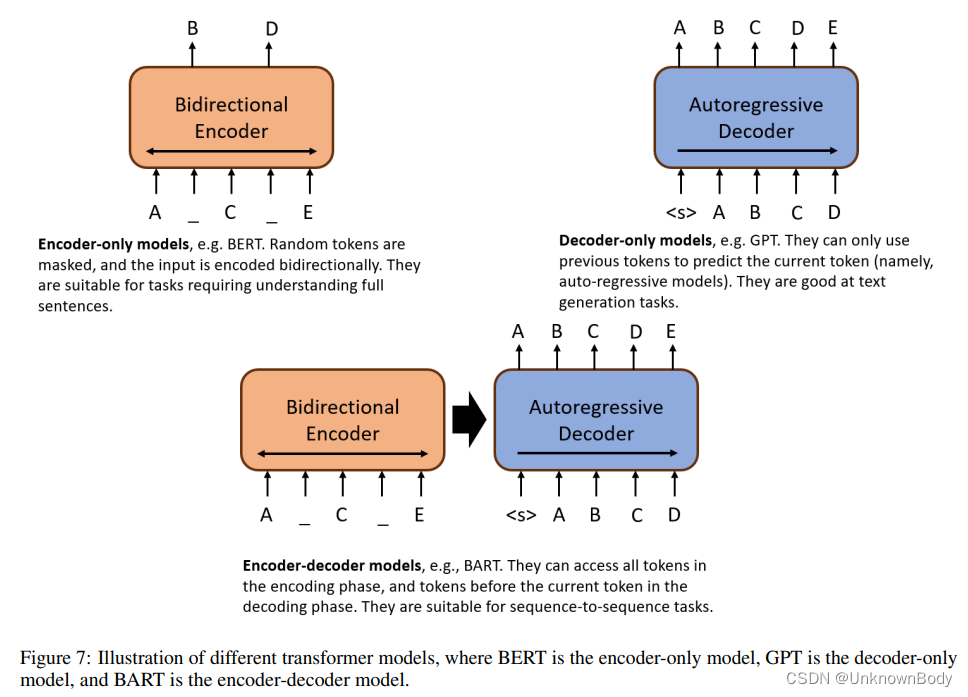
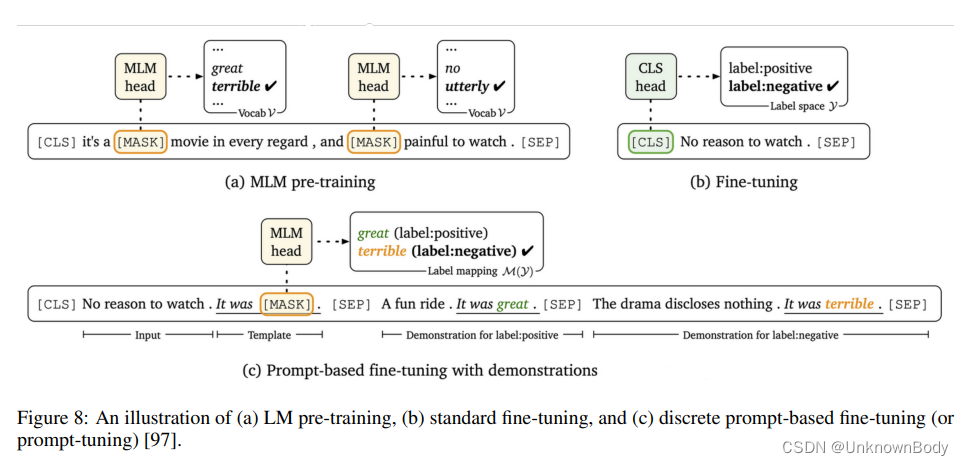
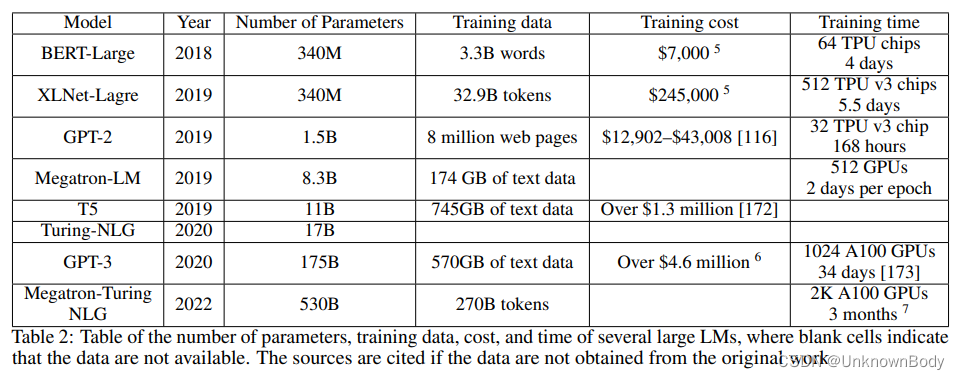
语言建模研究一系列语言单元(如单词)上的概率分布。它是自然语言处理中最基本的任务和长期存在的研究课题之一。所开发的语言模型在许多计算语言学问题中得到了应用,如文本生成、机器翻译、语音识别、自然语言生成、问答系统等。 语言建模有两种主要方法:1)基于相对较小语料库集的统计方法,以及2)基于明显较大语料库集的数据驱动方法。传统的语言模型以因果方式预测语言序列的概率。它们可以通过两种语言建模方法来学习。数据驱动方法已成为当今的主流。它利用大量的语料库来训练神经网络模型,从而产生预训练语言模型(PLM)。然后使用特定任务的数据集和下游应用程序的目标对PLM进行微调。在这篇综述文章中,我们将CLM定义为以因果方式预测语言序列概率的语言模型。相比之下,PLM指的是针对广泛的语言任务和目标预先训练的语言模型。需要注意的是,这两个概念并非排他性的。一个LM可以分为两类。例如,GPT模型可以以因果方式预测语言序列的概率。他们还接受了各种下游任务的预先训练。我们对CLM和PLM进行了概述,并从五个角度对其进行了研究:1)语言单元,2)架构,3)训练方法,4)评估方法和5)应用。最后,我们指出了未来的几个研究方向。 CLM的目标是对语言单元序列上的概率分布进行建模:
P
(
u
1
,
u
2
,
⋯
,
u
t
)
,
\begin{equation}P(u_1,u_2,\cdots,u_t), \end{equation}
P(u1,u2,⋯,ut), 其中
u
i
u_i
ui可以是字符、单词、短语或其他语言单位。CLM试图在给定其先前上下文的情况下预测文本序列中的下一个语言单元:
P
(
u
t
∣
u
<
t
)
,
\begin{equation}P(u_t|u_{<t}), \end{equation}
P(ut∣u<t), CLM也称为自回归语言模型,因为单位是以因果方式预测的。如等式(1)所示估计文本序列的概率直接遇到数据稀疏性问题。CLM通常通过将文本序列分解成更小的单元来估计文本序列的联合概率。例如,CLM利用链式规则和条件概率来估计以下形式的联合概率
P
(
u
1
,
u
2
,
⋯
,
u
t
)
=
P
(
u
1
)
P
(
u
2
∣
u
1
)
P
(
u
3
∣
u
1
,
u
2
)
⋯
P
(
u
t
∣
u
1
,
u
2
,
⋯
,
u
t
−
1
)
.
\begin{equation}P(u_1,u_2,\cdots,u_t)=P(u_1)P(u_2|u_1)P(u_3|u_1,u_2)\cdots P(u_t|u_1,u_2,\cdots,u_{t-1}). \end{equation}
P(u1,u2,⋯,ut)=P(u1)P(u2∣u1)P(u3∣u1,u2)⋯P(ut∣u1,u2,⋯,ut−1). 在预训练时代之前,CLM通常是用训练语料库从头开始训练的,然后通过各自的应用预测文本序列的概率。代表性模型包括N-gram LM、指数LM和早期神经LM。CLM为在现实世界中频繁出现的自然文本序列提供了很高的概率。因此,它们在文本生成、语音识别和机器翻译中发挥着基本作用,直到PLM的出现。如今,高性能PLM是许多NLP系统的主干。它们不限于CLM的因果预测功能,并提供更多不同类型的LM。 预训练时代之前的CLM和PLM之间的差异可以总结如下。
因果关系约束。PLM在预测语言单位时不一定遵循CLM,如等式(2)所示。例如,双向LM通过概率估计使用先前和后续上下文来预测缺失的语言单元:
P
(
u
t
∣
u
<
t
,
u
>
t
)
.
\begin{equation}P(u_t|u_{<t},u_{>t}). \end{equation}
P(ut∣u<t,u>t). 双向LMs不遵循等式(3)中的因果关系约束和链式规则,访问文本序列的概率,这使其与CLM本质上不同。
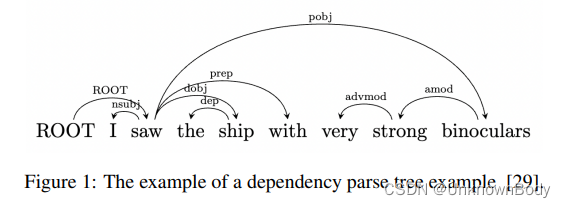
结构LM不是按顺序或反向顺序预测语言单元,而是基于预定义的语言结构(如依赖或成分解析树)预测语言单元。结构LMs利用语言结构使语言相关的上下文更接近要预测的语言单元。例如,给定一个解析树结构,结构LM可以将
u
t
u_t
ut的祖先上下文
A
(
u
t
)
A(u_t)
A(ut)定义为从根节点到
u
t
u_t
ut的父节点的序列。例如,单词“strong”的祖先序列是图1中的{“bicatears”、“saw”、root}。然后,结构LM使用树中的祖先上下文来预测下一个语言单元为
P
(
u
t
∣
A
(
u
t
)
)
,
\begin{equation}P(u_t|A(u_t)), \end{equation}
P(ut∣A(ut)), 其中
A
(
u
t
)
A(u_t)
A(ut)是语言单元
u
t
u_t
ut的祖先上下文。与CLM类似,结构LMs被设计用于对文本序列的概率进行建模。不同的是,结构LMs按照其合成结构的顺序解码序列概率。它已成功应用于句子补全和语音识别。
2.2 双向LM
双向LMs不是使用因果上下文来进行预测,而是使用来自两个方向的上下文,如等式(4)所示。掩蔽LM是一种代表性的双向LM。它屏蔽了文本序列中的语言单元,然后对其前后上下文进行编码,以预测被屏蔽的语言单元。形式上,预测可以定义为对以下条件概率的估计
P
(
u
m
∣
S
ˉ
)
,
\begin{equation}P(u_m|\bar S), \end{equation}
P(um∣Sˉ), 其中
u
m
u_m
um是掩蔽的语言单元,
S
ˉ
\bar S
Sˉ是通过用[MASK]符号替换一定数量的语言单元而损坏的文本序列。双向LMs的目标是以无监督的方式学习语言单元之间的内部依赖关系。训练后的模型可以继承大规模未标记语料库的语义。与旨在对文本序列的生成概率进行建模的CLM不同,在各种下游应用中,预训练的双向LMs被用作通过进一步微调来传递所学知识的骨干。
2.3 置换LM
CLM和掩蔽LMs有各自的优点和缺点。掩码LM需要创建诸如[mask]之类的人工token,这些token从不出现在下游任务中,而CLM仅以前面的上下文为条件。置换LM是最近提出的LM,它利用了CLM和掩蔽LM。给定语言单元的输入序列,排列LMs将输入语言单元的顺序随机化,并构造输入序列的不同排列。图2显示了给定输入文本序列的不同排列的示例。设
Z
\mathbb{Z}
Z是所有可能排列的集合。置换LMs预测序列的一个置换
Z
Z
Z中的下一个语言单元
u
t
u_t
ut,基于
P
(
u
t
∣
u
<
t
Z
)
,
Z
∈
Z
.
\begin{equation}P(u_t|u^Z_{<t}),Z\in\mathbb{Z}. \end{equation}
P(ut∣u<tZ),Z∈Z.
图3给出了在一个小字典上进行的BPE合并操作的说明。 WordPiece。WordPiece是另一种数据驱动的子字算法。WordPiece和BPE之间的区别在于,如果A和B在每个迭代步骤中具有最高分数
P
(
A
B
)
/
P
(
A
)
P
(
B
)
P(AB)/P(A)P(B)
P(AB)/P(A)P(B)(而不是最高频率
P
(
A
B
)
P(AB)
P(AB))。例如,WordPiece合并图3中的“u”和“g”对,只有当它们与其他对相比具有最高值
P
(
′
u
g
′
)
/
P
(
′
u
′
)
P
(
′
g
′
)
P('ug')/P('u')P('g')
P(′ug′)/P(′u′)P(′g′)时。在BERT、DistilBERT和Electra中,WordPiece被用作标记化方法。 还有其他基于统计的子词标记器,如Unigram。SentencePiece、Huggingface标记器和OpenNMT都是流行的标记器。它们的实现包含基于统计的子词标记化。研究了不同的子词标记器及其性能比较。
一个N-gram由一个文本序列中的N个连续标记组成。N-gram LM假设一个token的概率仅取决于其前面的N-1个token,并且它独立于其他上下文。这就是所谓的马尔可夫假设。因此,N元LMs不使用所有历史上下文,而是仅使用先前的N-1个token来预测当前token;即
P
(
u
t
∣
u
<
t
)
=
P
(
u
t
∣
u
t
−
N
+
1
:
t
−
1
)
.
\begin{equation}P(u_t|u_{<t})=P(u_t|u_{t-N+1:t-1}). \end{equation}
P(ut∣u<t)=P(ut∣ut−N+1:t−1). N-gram LMs通过计算给定训练语料库的N-gram的出现时间来计算条件概率
P
(
u
t
∣
u
t
−
N
+
1
:
t
−
1
)
=
C
(
u
t
−
N
+
1
:
t
)
C
(
u
t
−
N
+
1
:
t
−
1
)
.
\begin{equation}P(u_t|u_{t-N+1:t-1})=\frac{C(u_{t-N+1:t})}{C(u_{t-N+1:t-1})}. \end{equation}
P(ut∣ut−N+1:t−1)=C(ut−N+1:t−1)C(ut−N+1:t). N-gram LMs简化了基于先前N-1个token的token概率计算,但它们遇到了两个稀疏性问题。首先,如果训练语料库中从未出现N-gram
(
u
t
−
N
+
1
:
t
)
(u_{t-N+1:t})
(ut−N+1:t),则下一个token为
u
t
u_t
ut的概率为零。其次,如果分母中的(N-1)gram
(
u
t
−
N
+
1
:
t
−
1
)
(u_{t-N+1:t-1})
(ut−N+1:t−1)从未发生,我们就无法计算任何token的概率。这些稀疏性问题可以通过平滑技术来缓解。一种简单的平滑方法,称为加法平滑,是在每N-gram的计数上加一个小值,以避免等式(9)中分子和分母为零。然而,这种简单的平滑仍然是不足的,因为它为训练语料库中从未出现的N-grams分配了相同的概率。 有更先进的平滑技术,如后退和插值,可以实现更好的概率估计。在退避中,如果没有出现高阶N-gram,则使用低阶N-gram进行概率估计。例如,如果
C
(
u
t
−
3
:
t
−
1
)
=
0
C(u_{t-3:t-1})=0
C(ut−3:t−1)=0,则我们回退到计算
P
(
u
t
∣
u
t
−
2
:
t
−
1
)
P(u_t|u_{t-2:t-1})
P(ut∣ut−2:t−1)。在插值中,条件概率计算考虑了不同的N-grams。从数学上讲,N-gram概率由
P
(
u
t
∣
u
t
−
N
+
1
:
t
−
1
)
=
λ
N
P
(
u
t
∣
u
t
−
N
+
1
:
t
−
1
)
+
λ
N
−
1
P
(
u
t
∣
u
t
−
N
:
t
−
1
)
+
λ
N
−
2
P
(
u
t
∣
u
t
−
N
−
1
:
t
−
1
)
+
⋯
+
λ
1
P
(
u
t
)
.
\begin{gather}P(u_t|u_{t-N+1:t-1})=\lambda_NP(u_t|u_{t-N+1:t-1})+\lambda_{N-1}P(u_t|u_{t-N:t-1}) \notag \\ +\lambda_{N-2}P(u_t|u_{t-N-1:t-1})+\cdots+\lambda_1P(u_t). \end{gather}
P(ut∣ut−N+1:t−1)=λNP(ut∣ut−N+1:t−1)+λN−1P(ut∣ut−N:t−1)+λN−2P(ut∣ut−N−1:t−1)+⋯+λ1P(ut). 其中
λ
i
\lambda_i
λi是每一个n-gram的权重,同时
∑
i
=
1
N
λ
i
=
1.
\sum^N_{i=1}\lambda_i=1.
∑i=1Nλi=1.
4.2 最大熵模型
最大熵模型(也称为指数模型)使用以下形式的特征函数来估计文本序列的概率
P
(
u
∣
h
)
=
e
x
p
(
a
T
f
(
u
,
u
<
t
)
)
∑
u
′
e
x
p
(
a
T
f
(
u
′
,
u
<
t
′
)
)
,
\begin{equation}P(u|h)=\frac{exp(a^Tf(u,u_{<t}))}{\sum_{u'}exp(a^Tf(u',u'_{<t}))}, \end{equation}
P(u∣h)=∑u′exp(aTf(u′,u<t′))exp(aTf(u,u<t)), 其中
f
(
u
,
u
<
t
)
f(u,u_{<t})
f(u,u<t)是特征函数,生成token
u
u
u的特征和它的历史上下文
u
<
t
u_{<t}
u<t,
∑
u
′
e
x
p
(
a
T
f
(
u
′
,
u
<
t
′
)
)
\sum_{u'}exp(a^Tf(u',u'_{<t}))
∑u′exp(aTf(u′,u<t′))是归一化因子,同时
a
a
a是通过广义迭代缩放算法导出的参数向量。这些特征通常是由N-grams生成的。
4.3 前向神经网络模型
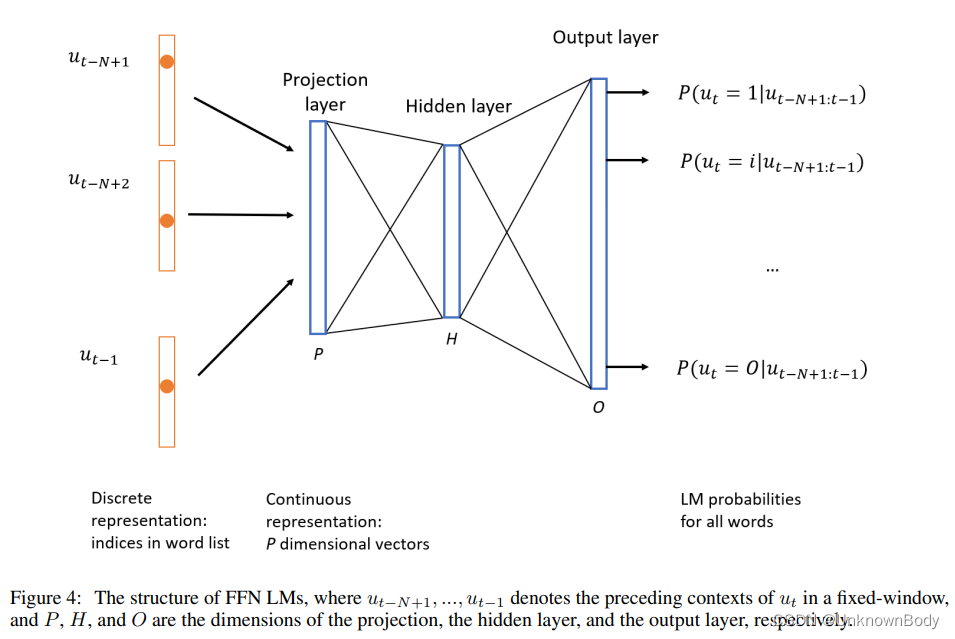
即使使用先进的平滑技术,N-gram模型的离散性也是其性能瓶颈。神经LMs采用连续嵌入空间(分布式表示)来克服数据稀疏性问题。前馈神经网络(FNN)LMs是早期的神经网络模型之一。 FNN LM以历史上下文为输入,并输出token的概率分布。如图4所示,前面上下文中的每个token都通过投影层(即嵌入矩阵)表示为向量。token的这些向量被发送到具有H个隐藏单元的隐藏层,随后是非线性激活。然后,使用softmax函数来获得候选token的后验概率
P
(
u
t
=
i
∣
u
t
−
N
−
1
:
t
−
1
)
P(u_t=i|u_{t-N-1:t-1})
P(ut=i∣ut−N−1:t−1),其是给定由语言模型预测的特定历史的token的概率。 FNN LM使用固定窗口来收集固定长度的上下文。它本质上是N-gram LMs的神经版本。FNN-LM通过将token投影到连续空间中而比N-gram LM具有几个优点。首先,它可以通过将每个token表示为具有密集向量空间的N-gram来处理看不见的N-gram。其次,它是存储高效的,因为它不需要计算和存储传统N-gram模型的转移概率。
4.4 循环神经网络模型
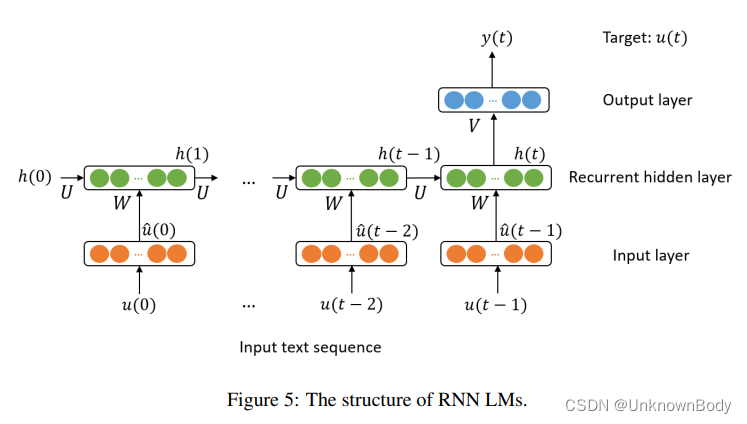
使用固定长度的历史上下文来预测下一个token显然是不够的。与N-gram、最大熵和FNN LMs中使用的有限历史上下文相反,递归神经网络(RNN)LMs可以利用任意长的历史来预测下一个token。 朴素RNN LM的结构如图5所示。位置
i
i
i中的token
u
(
i
)
u(i)
u(i)首先被转换为独热表示
u
^
(
i
)
\hat u(i)
u^(i)。然后,使用先前的隐藏状态
h
(
i
)
h(i)
h(i)和token
u
(
i
)
u(i)
u(i)的独热表示
u
^
(
i
)
\hat u(i)
u^(i)来计算当前的隐藏状态
h
(
i
+
1
)
h(i+1)
h(i+1)
h
(
i
+
1
)
=
f
(
W
u
^
(
i
)
+
U
h
(
i
)
)
,
\begin{equation}h(i+1)=f(W\hat u(i)+Uh(i)), \end{equation}
h(i+1)=f(Wu^(i)+Uh(i)), 其中
f
(
⋅
)
f(\cdot)
f(⋅)是非线性激活函数,W是从输入层到隐藏层的连接的权重矩阵,U分别是先前和当前隐藏层之间的连接。通过迭代计算隐藏状态,RNN LMs可以对不同长度的历史上下文进行编码。最后,输出层给出了toekn
y
(
t
)
=
g
(
V
h
(
t
)
)
y(t)=g(Vh(t))
y(t)=g(Vh(t))的条件概率,其中V是连接隐藏层和输出层的权重矩阵,
g
(
⋅
)
g(\cdot)
g(⋅)是softmax激活函数。 在理论上,RNN LMs不需要马尔可夫假设。他们可以使用所有先前的历史来预测下一个token。然而,RNN固有的梯度消失问题阻碍了模型的学习。由于梯度在长距离内可能会变得非常小,因此在实践中,模型权重实际上是由附近的上下文更新的。通常,RNN LMs无法了解当前token与其遥远的历史上下文之间的依赖关系。尽管可以在RNN中引入注意力机制来缓解这个问题。RNN固有的顺序性使其不如具有自注意机制的基于Transformer的LMs强大。
自回归LM。LM估计文本序列的概率。好的LM为自然文本序列分配更高的概率,为不真实或随机文本序列分配更低的概率。困惑是一个常见的评估指标。给定一个测试文本序列,困惑(由P P L表示)被定义为通过token数量归一化的序列的逆概率。从数学上讲,我们有
P
P
L
(
S
)
=
1
P
(
u
1
u
2
⋯
u
N
)
,
N
\begin{equation}PPL(S)=\sqrt[N]{\frac{1}{P(u_1u_2\cdots u_N)},} \end{equation}
PPL(S)=NP(u1u2⋯uN)1, 其中
S
=
u
1
u
2
⋯
u
N
S=u_1u_2\cdots u_N
S=u1u2⋯uN是测试文本序列。困惑度可以被重写为
P
P
L
(
S
)
=
∏
i
=
1
N
1
P
(
u
i
∣
u
1
⋯
u
i
−
1
)
.
N
\begin{equation}PPL(S)=\sqrt[N]{\prod^N_{i=1}\frac{1}{P(u_i|u_1\cdots u_{i-1})}.} \end{equation}
PPL(S)=Ni=1∏NP(ui∣u1⋯ui−1)1. 一个好的LM应该最大化文本集的概率。这相当于最大限度地减少了困惑。困惑越低,LM越好。 双向语言模型。为了计算等式(13)中的逆概率,自回归LM可以使用条件概率序列。然而,这种方法不适用于双向LMs(或屏蔽LMs)。已经为双向LMs提出了几个内在的评估指标。伪对数似然分数(PLL)定义为
P
P
L
(
S
)
=
∑
i
=
1
∣
S
∣
log
P
(
u
i
∣
S
\
i
)
,
\begin{equation}PPL(S)=\sum^{|S|}_{i=1}\log P(u_i|S_{\backslash i}), \end{equation}
PPL(S)=i=1∑∣S∣logP(ui∣S\i), 其中
log
P
(
u
i
∣
S
\
i
)
\log P(u_i|S_{\backslash i})
logP(ui∣S\i)是句子S中的token
u
i
u_i
ui与所有剩余token的条件概率。一个好的双向LM应该在给定其他token的情况下最大化文本序列中每个token的概率,而不是最大化整个文本序列的联合概率。基于PLLs,语料库C的伪困惑(PPPL)定义为
P
P
P
L
(
C
)
=
e
x
p
(
−
1
N
∑
S
∈
C
P
L
L
(
S
)
)
.
\begin{equation}PPPL(C)=exp(-\frac{1}{N}\sum_{S\in C}PLL(S)). \end{equation}
PPPL(C)=exp(−N1S∈C∑PLL(S)). PLL和PPPL都为双向LM提供了测量句子自然度的有效手段。例如,[105]中显示,PLL和PPPL与LM在下游任务(如自动语音识别和机器翻译)上的性能密切相关。
自动语音识别(ASR)是一种语音到文本的生成任务,旨在将原始音频输入转换为相应的文本序列。LM在ASR系统中起着至关重要的作用。首先,它有助于解决声学上模棱两可的话语。其次,它可以通过将搜索空间约束在一组概率较高的单词中来降低计算成本。传统的ASR系统包含两个独立的模型,一个声学模型和一个语言模型,它们通过以下互相关联
P
(
w
o
r
d
∣
s
o
u
n
d
)
∝
P
(
s
o
u
n
d
∣
w
o
r
d
)
P
(
w
o
r
d
)
.
\begin{equation}P(word|sound)\propto P(sound|word)P(word). \end{equation}
P(word∣sound)∝P(sound∣word)P(word). 声学模型以电话
P
(
s
o
u
n
d
∣
w
o
r
d
)
P(sound|word)
P(sound∣word)为条件,而LM给出由
P
(
w
o
r
d
)
P(word)
P(word)表示的单词分布。LMs有助于在识别过程中搜索单词假设。在ASR中已经探索了不同类型的LM,如N-gram、FFNN、RNN和Transformer。 随着深度学习技术的发展,端到端(E2E)ASR系统已成为当今该领域的主导方法。E2E ASR系统不独立地训练声学模型和语言模型,而是使用单个网络架构。例如,Listen,Attend and Spell(LAS)模型包含编码器、解码器和注意力网络,它们被联合训练以预测输出文本序列。E2E ASR系统中的LM分量是从转录的语音数据中隐式学习的。为了解决LM训练的有限转录语音数据的挑战,一种解决方案是使用LM集成来集成在广泛的文本语料库上训练的外部语言模型。浅融合在解码阶段考虑来自E2E ASR模型和外部LM的分数之间的对数线性插值。深度融合通过融合外部LM和E2E ASR模型的隐藏状态来整合它们。与分别训练E2E ASR模型和外部LM的浅融合和深融合不同,冷融合和分量融合联合训练E2E ASR模型和外部LM。