工作中常会接触到强化学习的内容,自己以gym环境中的Cartpole为例动手实现一下,记录点实现细节。环境:python = 3.6.13; pytorch = 1.10.2
目录
1. gym-CartPole环境准备
2. PID控制
3. DQN控制
3.1 问题1:网络要训成什么样才算能用?
3.2 问题2:调整哪些细节可以提升网络表现?
4. 遗留问题
5. DQN改进
1. gym-CartPole环境准备
环境是用的gym中的CartPole-v1,就是火柴棒倒立摆。gym是openai的开源资源,具体如何安装可参照:
强化学习一、基本原理与gym的使用_wshzd的博客-CSDN博客_gym 强化学习
这个环境的具体细节(参考gym源码cartpole.py):
action只有向左向右两个选择,离散量
观测值有4个,x, x_dot, theta, theta_dot,源文件里也给了具体的值域范围,超过这个范围,会认为done。另外这个环境超过500步就会认为是done了。
| Num | Observation | Min | Max |
|-----|-----------------------|----------------------|--------------------|
| 0 | Cart Position | -4.8 | 4.8 |
| 1 | Cart Velocity | -Inf | Inf |
| 2 | Pole Angle | ~ -0.418 rad (-24°) | ~ 0.418 rad (24°) |
| 3 | Pole Angular Velocity | -Inf | Inf |
2. PID控制
这个问题其实是个很基本的控制问题,也不太涉及到要靠什么多步决策优化来搞,所以简单搞了个PID控一下,主要为了熟悉下这个环境,具体没啥好解释的,直接放一下代码,因为随便玩一下,参数没有细调,大概能用。
import gym
from matplotlib import animation
import matplotlib.pyplot as plt
env = gym.make('CartPole-v1')
obs = env.reset()
kp = 0.000
kv = -0.002
ka = -0.3
kav = -0.01
ks = -0.000
sum_angle = 0.000
frames = []
def save_gif(frames):
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=5)
anim.save('./CartPortCtrl.gif', writer='imagemagick', fps=30)
def CalcAction(obs):
action = 0 # 0 meanleft, 1 means right
global sum_angle
sum = kp * obs[0] + kv * obs[1] + ka * obs[2] + kav * obs[3] + ks * sum_angle
sum_angle += obs[2]
if (sum < 0.0):
action = 1
else:
action = 0
return action
for _ in range(200):
frames.append(env.render(mode='rgb_array'))
action = CalcAction(obs)
print('action = %d' % action)
obs, reward, done, info = env.step(action)
env.close()
save_gif(frames)
具体效果见上面,200步内还是比较稳的,但是到300-400步,会渐渐发散掉。
3. DQN控制
因为是离散型问题,选用了最简单的DQN实现,用Pytorch实现的,这里代码实现很多参考的是:
强化学习算法实例DQN代码PyTorch实现 - -Rocky- - 博客园
另外有些基本概念学习了下莫烦的视频:
强化学习 (Reinforcement Learning) | 莫烦Python
基本公式:

上述这两个资料只能教你最简单的实现,将程序搭到一个能跑通的状态,但如何得到一个好用的网络 & 调试中的trick没有仔细介绍,为此本文记录了一些细节。调试过程中困惑我比较久的一个问题:根据网上的方法训练的网络loss看上去收敛了,其实并不能很好地控制CartPole,所以这里尝试回答两个问题:
问题1:网络要训成什么样才算能用?
问题2:调整哪些细节可以提升网络表现?
先放代码再回答问题:
GitHub - BITcsy/gymTest https://github.com/BITcsy/gymTest本文涉及的两段代码都可以在上述地址找到。
https://github.com/BITcsy/gymTest本文涉及的两段代码都可以在上述地址找到。
import gym
from matplotlib import animation
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torch
import numpy as np
class Net(nn.Module):
def __init__(self, n_states, n_actions):
super(Net, self).__init__()
self.fc1 = nn.Linear(n_states, 10)
self.fc2 = nn.Linear(10, n_actions)
self.fc1.weight.data.normal_(0, 0.1)
self.fc2.weight.data.normal_(0, 0.1)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
out = self.fc2(x)
return out
class DQN:
def __init__(self, n_states, n_actions):
print("<DQN init>")
self.eval_net, self.target_net = Net(n_states, n_actions), Net(n_states, n_actions) # nit two nets
self.loss = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=0.01)
self.n_actions = n_actions
self.n_states = n_states
# 使用变量
self.learn_step_counter = 0 # target网络学习计数
self.memory_counter = 0 # 记忆计数
self.memory = np.zeros((2000, 2 * n_states + 1 + 1)) # s, s', a, r
self.cost = [] # 记录损失值
self.done_step_list = []
def choose_action(self, state, epsilon):
state = torch.unsqueeze(torch.FloatTensor(state), 0) # (1,2)
if np.random.uniform() < epsilon:
action_value = self.eval_net.forward(state)
action = torch.max(action_value, 1)[1].data.numpy()[0] # d the max value in softmax layer. before .data, it is a tensor
else:
action = np.random.randint(0, self.n_actions)
# print("action=", action)
return action
def store_transition(self, state, action, reward, next_state):
# print("<store_transition>")
transition = np.hstack((state, [action, reward], next_state))
index = self.memory_counter % 2000 # 满了就覆盖旧的
self.memory[index, :] = transition
self.memory_counter += 1
def learn(self):
# print("<learn>")
# target net 更新频率,用于预测,不会及时更新参数
if self.learn_step_counter % 100 == 0:
self.target_net.load_state_dict((self.eval_net.state_dict()))
# print("update eval to target")
self.learn_step_counter += 1
# 使用记忆库中批量数据
sample_index = np.random.choice(2000, 16) # 200个中随机抽取32个作为batch_size
memory = self.memory[sample_index, :] # 取的记忆单元,并逐个提取
state = torch.FloatTensor(memory[:, :self.n_states])
action = torch.LongTensor(memory[:, self.n_states:self.n_states + 1])
reward = torch.LongTensor(memory[:, self.n_states + 1:self.n_states + 2])
next_state = torch.FloatTensor(memory[:, self.n_states + 2:])
# 计算loss,q_eval:所采取动作的预测value,q_target:所采取动作的实际value
q_eval = self.eval_net(state).gather(1, action) # eval_net->(64,4)->按照action索引提取出q_value
q_next = self.target_net(next_state).detach()
# torch.max->[values=[],indices=[]] max(1)[0]->values=[]
q_target = reward + 0.9 * q_next.max(1)[0].unsqueeze(1) # label
loss = self.loss(q_eval, q_target) # td error
self.cost.append(loss)
# 反向传播更新
self.optimizer.zero_grad() # 梯度重置
loss.backward() # 反向求导
self.optimizer.step() # 更新模型参数
def plot_cost(self):
plt.subplot(1,2,1)
plt.plot(np.arange(len(self.cost)), self.cost)
plt.xlabel("step")
plt.ylabel("cost")
plt.subplot(1,2,2)
plt.plot(np.arange(len(self.done_step_list)), self.done_step_list)
plt.xlabel("step")
plt.ylabel("done step")
plt.show()
def save_gif(frames):
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=5)
anim.save('./CartPortRL.gif', writer='imagemagick', fps=30)
if __name__ == "__main__":
env = gym.make('CartPole-v1')
frames = []
# train
counter = 0
done_step = 0
max_done_step = 0
num = 200000
negative_reward = -10.0
x_bound = 1.0
state = env.reset()
model = DQN(
n_states=4,
n_actions=2
) # 算法模型
model.cost.clear()
model.done_step_list.clear()
for i in range(num):
# env.render()
# frames.append(env.render(mode='rgb_array'))
epsilon = 0.9 + i / num * (0.95 - 0.9)
# epsilon = 0.9
action = model.choose_action(state, epsilon)
# print('action = %d' % action)
state_old = state
state, reward, done, info = env.step(action)
x, x_dot, theta, theta_dot = state
# r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8 # x_threshold 4.8
# r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
if (abs(x) > x_bound):
r1 = 0.5 * negative_reward
else:
r1 = negative_reward * abs(x) / x_bound + 0.5 * (-negative_reward)
if (abs(theta) > env.theta_threshold_radians):
r2 = 0.5 * negative_reward
else:
r2 = negative_reward * abs(theta) / env.theta_threshold_radians + 0.5 * (-negative_reward)
reward = r1 + r2
if done:
reward += negative_reward
# print("x = %lf, r1 = %lf, theta = %lf, r2 = %lf" % (x, r1, theta, r2))
model.store_transition(state_old, action, reward, state)
if (i > 2000 and counter % 10 == 0):
model.learn()
counter = 0
counter += 1
done_step += 1
if (done):
# print("reset env! done_step = %d, epsilon = %lf" % (done_step, epsilon))
if (done_step > max_done_step):
max_done_step = done_step
state = env.reset()
model.done_step_list.append(done_step)
done_step = 0
#model.plot_cost() # 误差曲线
#print("reccurent time = %d, max done step = %d, final done step = %d" % (retime, max_done_step, model.done_step_list[-1]))
# test
state = env.reset()
for _ in range(400):
frames.append(env.render(mode='rgb_array'))
action = model.choose_action(state, 1.0)
state, reward, done, info = env.step(action)
if (done):
state = env.reset()
print("test try again")
break
env.close()
save_gif(frames)
基本语法:(遗留)
3.1 问题1:网络要训成什么样才算能用?
这个算法里loss就是TD error,起初训练出来的网络在loss图上已经收敛了,如图:
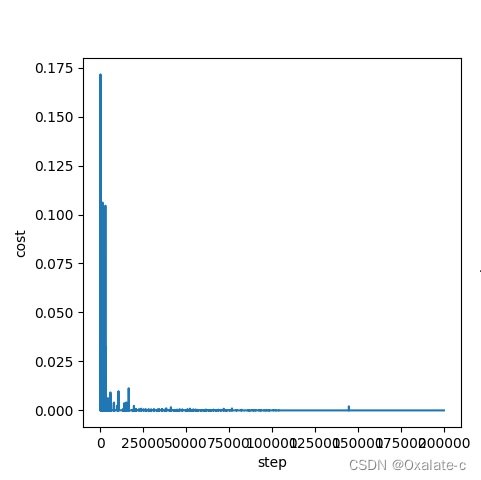
但是用这个网络实际控制CartPole完全就是在乱动,一味地增大训练步数效果甚微。考虑到这个任务其实是希望将CartPole立住更长的时间,因此通过训练过程中训练能走到的最大步数作为判断网络质量的依据,这里提了两个指标:训练中达到的最大步数 & 训练截止前最后一次网络坚持到的步数(这么定不完全严谨,因为DQN在选动作的过程中是会有随机因素在,不过多次测试可以大致反应训练效果了。严谨的做法就是直接用这个网络去控制CartPole看效果。)
3.2 问题2:调整哪些细节可以提升网络表现?
直觉上猜测主要的影响因素:训练步长,epsilon,reward设计。其中reward设计是看了莫烦的视频得到的启发,因为CartPole环境里默认的reward实在太粗糙了,只有0,1,没法表征出比较连续的量。所以我尝试了一下下面这些因素,指标用的是3.1小节里提到的那两个步数,为了避免随机因素的影响,每组参数我做了10组实验,通过均值比对分析了下各个指标的影响:
- 因素1:训练步数,默认10万步
- 因素2:异常结束(没有到500步)失败reward惩罚
- 因素3:rewad = r1 + r2(同莫烦视频)
- 因素4:reward基准数值(莫烦视频里r1,r2分别有个-0.8和-0.5的偏移量,我个人存疑所以试了一下)
- 因素5:epsilon渐变(0.9->0.95渐变)
- 因素6:target网络同步频率,就是对应于DQN里的fix target策略,要多久一次更新一下target
- 因素7:batch size
- 因素8:Gamma折扣系数
直接看结果:
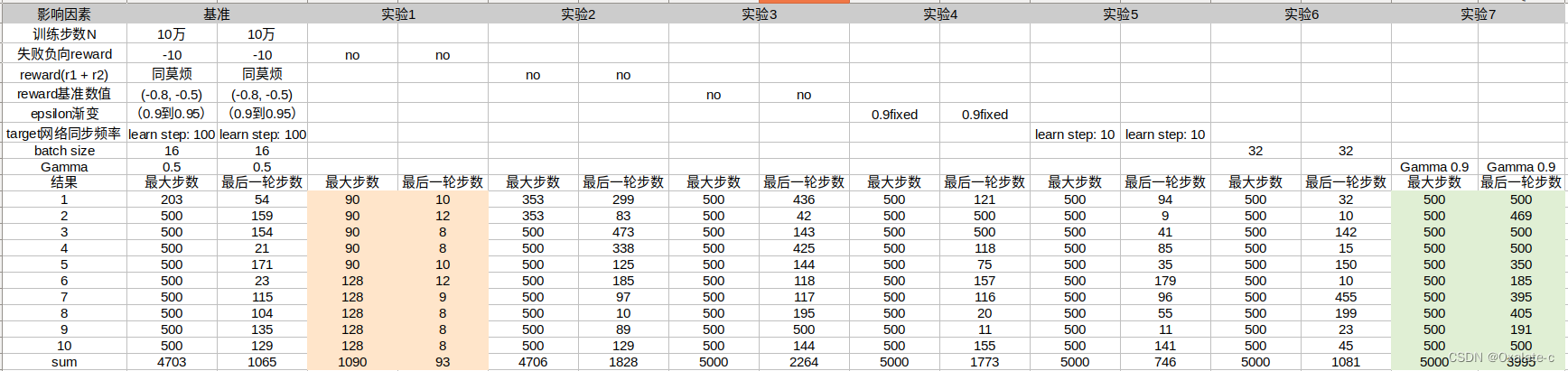
结论:
- 因素1:训练步数。表格中没给对比结果,我实验过程中有明显影响,得保证一定量才行,这个问题推荐20万步以上。
- 因素2:异常结束(没有到500步)失败reward惩罚。影响很大,如果没有网络基本不能用,这是该任务关键的稀疏奖励。
- 因素3:rewad = r1 + r2(同莫烦视频)。有负向影响,去掉反而更好了。
- 因素4:reward基准数值(同莫烦视频)。有负向影响,去掉反而更好了。
- 因素5:epsilon渐变(0.9->0.95渐变)。直接用0.9反而更好了,训练过程中发现使用可变epsilon的时候如果网络还没有收敛到比较好的解,epsilon就比较大了,网络可能就崩了,再也回不来了。如图:

- 因素6:target网络同步频率。影响很大,太小的话不利于收敛。侧面反应fix target的重要性,不能同步太快。
- 因素7:batch size。没太大影响。
- 因素8:Gamma折扣系数。影响很大,最开始没注意到这个数太小,调成0.9网络效果要好很多。
最后做了几个调整:
- 训练20万步
- 配合负向reward,做整个reward的渐变,防止reward跳变导致reward太稀疏
- Gamma = 0.9
- target同步频率:训练100次同步一次
最后效果:可以达到500步,不过网络训练有随机性,训练多版网络不能保证每个网络都很稳:
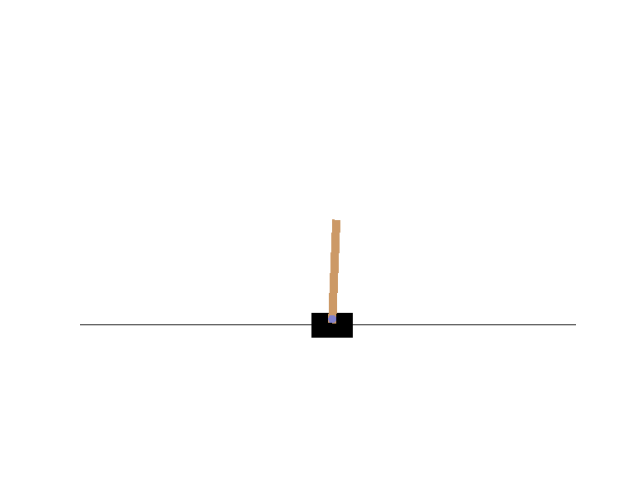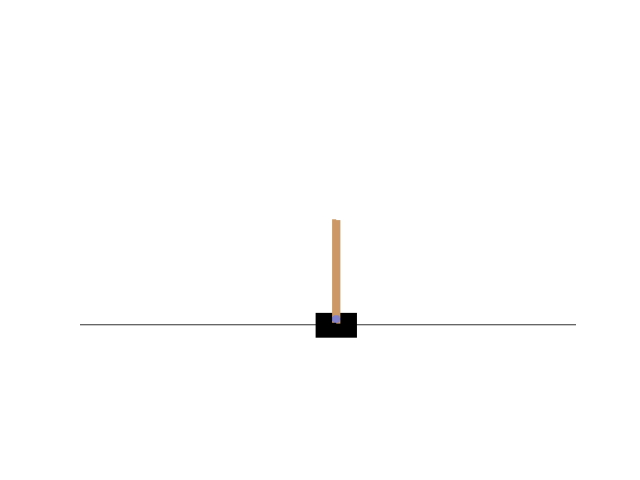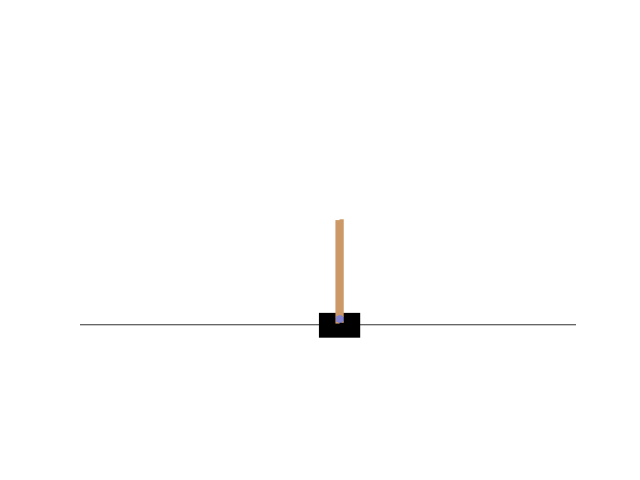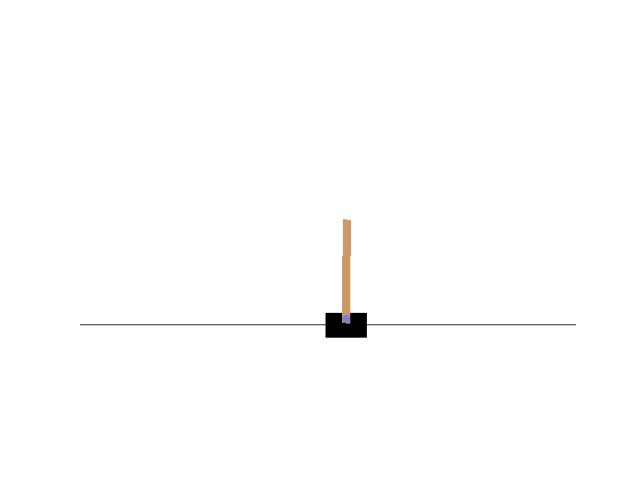
4. 遗留问题
在训练过程中思考了强化学习在实际工业场景中使用的几个问题,遗留在这里希望大佬指导:
5. DQN改进
- Double DQN(DDQN):为解决DQN过估计的问题,修改了Q现实计算中直接取最大的方法,利用Q估计来确定a,再以该a来确定Q现实。
- Prioritized Experience Replay:为了解决始终用无效数据训练的问题,优先计算td error较大的数据,算法实现用了SumTree的数据结构。
- Dueling DQN:加速收敛。将Q拆分成了V(s) + Adv(a)这样的形式,一个和s有关,一个和a有关。训练过程中也加入了求均值等trick,方式训练退化成了直接学Q。
- 其他详见Rainbow的解析:Rainbow: 融合DQN六种改进的深度强化学习方法! - 知乎
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)