一、预备知识
1、协方差矩阵
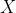 是一个
是一个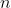 维列向量,
维列向量,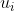 是
是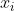 的期望,协方差矩阵为
的期望,协方差矩阵为
![P=E[(X-E[X])(X-E[X])^T]](https://private.codecogs.com/gif.latex?P%3DE%5B%28X-E%5BX%5D%29%28X-E%5BX%5D%29%5ET%5D)
![=\begin{bmatrix} E[(x_1-u_1)(x_1-u_1)]& E[(x_1-u_1)(x_2-u_2)]& ...& E[(x_1-u_1)(x_n-u_n)]&\\ E[(x_2-u_2)(x_1-u_1)]& E[(x_2-u_2)(x_2-u_2)]& ...& E[(x_2-u_2)(x_n-u_n)]\\ ...& ...& ...& ...&\\ E[(x_n-u_n)(x_1-u_1)]& E[(x_n-u_n)(x_2-u_2)]& ...& E[(x_n-u_n)(x_n-u_n)]& \end{bmatrix}](https://private.codecogs.com/gif.latex?%3D%5Cbegin%7Bbmatrix%7D%20E%5B%28x_1-u_1%29%28x_1-u_1%29%5D%26%20E%5B%28x_1-u_1%29%28x_2-u_2%29%5D%26%20...%26%20E%5B%28x_1-u_1%29%28x_n-u_n%29%5D%26%5C%5C%20E%5B%28x_2-u_2%29%28x_1-u_1%29%5D%26%20E%5B%28x_2-u_2%29%28x_2-u_2%29%5D%26%20...%26%20E%5B%28x_2-u_2%29%28x_n-u_n%29%5D%5C%5C%20...%26%20...%26%20...%26%20...%26%5C%5C%20E%5B%28x_n-u_n%29%28x_1-u_1%29%5D%26%20E%5B%28x_n-u_n%29%28x_2-u_2%29%5D%26%20...%26%20E%5B%28x_n-u_n%29%28x_n-u_n%29%5D%26%20%5Cend%7Bbmatrix%7D)
可以看出
协方差矩阵都是对称矩阵且是半正定的
协方差矩阵的迹 是的均方误差
是的均方误差
2、用到的两个矩阵微分公式
公式一:

公式二:若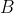 是对称矩阵,则下式成立
是对称矩阵,则下式成立

tr表示矩阵的迹,具体推导过程参考相关矩阵分析教程
二、系统模型与变量说明
1、系统离散型状态方程如下
由k-1时刻到k时刻,系统状态预测方程

系统状态观测方程

2、变量说明如下
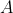 :状态转移矩阵
:状态转移矩阵
 :系统输入向量
:系统输入向量
:输入增益矩阵
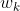 :均值为0,协方差矩阵为
:均值为0,协方差矩阵为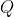 ,且服从正态分布的过程噪声
,且服从正态分布的过程噪声
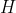 :测量矩阵
:测量矩阵
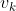 :均值为0,协方差矩阵为
:均值为0,协方差矩阵为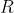 ,且服从正态分布的测量噪声
,且服从正态分布的测量噪声
初始状态以及每一时刻的噪声 都认为是互相独立的,实际上,很多真实世界的动态系统都并不确切的符合这个模型;但是由于卡尔曼滤波器被设计在有噪声的情况下工作,一个近似的符合已经可以使这个滤波器非常有用了。
都认为是互相独立的,实际上,很多真实世界的动态系统都并不确切的符合这个模型;但是由于卡尔曼滤波器被设计在有噪声的情况下工作,一个近似的符合已经可以使这个滤波器非常有用了。
三、卡尔曼滤波器
卡尔曼估计实际由两个过程组成:预测与校正,在预测阶段,滤波器使用上一状态的估计,做出对当前状态的预测。在校正阶段,滤波器利用对当前状态的观测值修正在预测阶段获得的预测值,以获得一个更接进真实值的新估计值。
1、变量说明
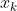 :真实值
:真实值
 :卡尔曼估计值
:卡尔曼估计值
 :卡尔曼估计误差协方差矩阵
:卡尔曼估计误差协方差矩阵
 :预测值
:预测值
 :预测误差协方差矩阵
:预测误差协方差矩阵
 :卡尔曼增益
:卡尔曼增益
 :测量余量
:测量余量
2、卡尔曼滤波器计算过程
预测:


校正:



更新协方差估计:

观察以上六个式子,我们使用过程中关键要明白 ,的算法原理,及的更新算法
,的算法原理,及的更新算法
3、卡尔曼滤波算法详细推导
从协方差矩阵开始说起,真实值与预测值之间的误差为

预测误差协方差矩阵为![{P}'_k=E[{e}'_k{{e}'_k}^T]=E[(x_k-\hat{x}'_k)(x_k-\hat{x}'_k)^T]](https://latex.codecogs.com/gif.latex?%7BP%7D%27_k%3DE%5B%7Be%7D%27_k%7B%7Be%7D%27_k%7D%5ET%5D%3DE%5B%28x_k-%5Chat%7Bx%7D%27_k%29%28x_k-%5Chat%7Bx%7D%27_k%29%5ET%5D)
真实值与估计值之间的误差为


卡尔曼估计误差协方差矩阵为
![P_k=E[e_ke_k^T]](https://private.codecogs.com/gif.latex?P_k%3DE%5Be_ke_k%5ET%5D)
将 代入得到
代入得到
![P_k=E[[(I-K_kH)(x_k-\hat{x}'_k)-K_kv_k][(I-K_kH)(x_k-\hat{x}'_k)-K_kv_k]^T]](https://private.codecogs.com/gif.latex?P_k%3DE%5B%5B%28I-K_kH%29%28x_k-%5Chat%7Bx%7D%27_k%29-K_kv_k%5D%5B%28I-K_kH%29%28x_k-%5Chat%7Bx%7D%27_k%29-K_kv_k%5D%5ET%5D)
^T+K_kE[v_k{v}^T_k]K^T](https://private.codecogs.com/gif.latex?%3D%28I-K_kH%29E%5B%28x_k-%5Chat%7Bx%7D%27_k%29%28x_k-%5Chat%7Bx%7D%27_k%29%5ET%5D%28I-K_kH%29%5ET+K_kE%5Bv_k%7Bv%7D%5ET_k%5DK%5ET)
其中 ![E[v_kv_k^T]=R](https://private.codecogs.com/gif.latex?E%5Bv_kv_k%5ET%5D%3DR) ,并将预测误差协方差矩阵代入,得到
,并将预测误差协方差矩阵代入,得到

卡尔曼滤波本质是最小均方差估计,而均方差是的迹,将上式展开并求迹

最优估计使 最小,所以上式两边对求导
最小,所以上式两边对求导

套用第一节中提到的那两个矩阵微分公式,得到

令上式等于0,得到

到此,我们就知道了卡尔曼增益是怎么算出来的了,但是又有问题, 是怎么算的呢?
是怎么算的呢?
![P'_k=E[(x_k-\hat{x}'_k)(x_k-\hat{x}'_k)^T]](https://private.codecogs.com/gif.latex?P%27_k%3DE%5B%28x_k-%5Chat%7Bx%7D%27_k%29%28x_k-%5Chat%7Bx%7D%27_k%29%5ET%5D)
![=E[(Ax_{k-1}+Bu_k+w_k-A\hat{x}_{k-1}-Bu_k)(Ax_{k-1}+Bu_k+w_k-A\hat{x}_{k-1}-Bu_k)^T]](https://private.codecogs.com/gif.latex?%3DE%5B%28Ax_%7Bk-1%7D+Bu_k+w_k-A%5Chat%7Bx%7D_%7Bk-1%7D-Bu_k%29%28Ax_%7Bk-1%7D+Bu_k+w_k-A%5Chat%7Bx%7D_%7Bk-1%7D-Bu_k%29%5ET%5D)
![=E[(A(x_{k-1}-\hat{x}_{k-1})+w_k)(A(x_{k-1}-\hat{x}_{k-1})+w_k)^T]](https://private.codecogs.com/gif.latex?%3DE%5B%28A%28x_%7Bk-1%7D-%5Chat%7Bx%7D_%7Bk-1%7D%29+w_k%29%28A%28x_%7Bk-1%7D-%5Chat%7Bx%7D_%7Bk-1%7D%29+w_k%29%5ET%5D)
![=E[(Ae_{k-1})(Ae_{k-1})^T]+E[w_kw_k^T]](https://private.codecogs.com/gif.latex?%3DE%5B%28Ae_%7Bk-1%7D%29%28Ae_%7Bk-1%7D%29%5ET%5D+E%5Bw_kw_k%5ET%5D)

(注意其中展开过程用到了![E[w_k]=0](https://private.codecogs.com/gif.latex?E%5Bw_k%5D%3D0) )
)
所以预测误差协方差矩阵可以由上一次算出的估计误差协方差矩阵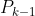 及状态转移矩阵和过程激励噪声的协方差矩阵算得
及状态转移矩阵和过程激励噪声的协方差矩阵算得
四、实例
在惯性器件+GPS融合定位中,卡尔曼滤波是比较常用的。这里简化举例,简化为一维的,假设小车沿一条直线行驶。里面有加速度计来计算位置,每100ms计算一次,并有GPS定位,1S更新一次。套到上述公式中,是这样操作的,在GPS没有更新的时候,只能作预测,用这几个公式:
由于我们简化为一维,公式可以写成这样



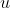 是由加表每个计算周期的积分得到的位置增量,
是由加表每个计算周期的积分得到的位置增量,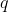 就代表加表误差,
就代表加表误差,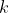 是卡尔曼增益,GPS没有更新时,不会变,初始时设置
是卡尔曼增益,GPS没有更新时,不会变,初始时设置 。可以看出随着计算次数的增加,衡量预测误差的
。可以看出随着计算次数的增加,衡量预测误差的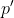 会越来越大。这和实际情况也是一致,积分次数越多,累积误差会越来越大 。越大,发散得越快,传感器精度,影响预测精度 。
会越来越大。这和实际情况也是一致,积分次数越多,累积误差会越来越大 。越大,发散得越快,传感器精度,影响预测精度 。
更新了10次,1秒时间到了,GPS有更新,然后就到了校正过程,套用:
假设位置可以直接观测,即![H=[1]](https://latex.codecogs.com/gif.latex?H%3D%5B1%5D) , 简化后
, 简化后



由这三个公式就得到了卡尔曼估计值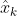 。r是常量,描述GPS的测量误差。由的计算公式,可以看出,预测误差越大,越接近1,再看第三个公式,k越接近1,
。r是常量,描述GPS的测量误差。由的计算公式,可以看出,预测误差越大,越接近1,再看第三个公式,k越接近1,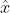 越接近测量值
越接近测量值 , 这个公式和互补滤波的公式很像,但是这个权重k是动态变化的,这也是卡尔曼滤波的高明之处。总结就是,单凭传感器预测位置,计算次数越多,误差
, 这个公式和互补滤波的公式很像,但是这个权重k是动态变化的,这也是卡尔曼滤波的高明之处。总结就是,单凭传感器预测位置,计算次数越多,误差 就会越大,卡尔曼增益就越大,测量值权重就越大,校正时,最终估计值 就会越接近测量值 。校正完了之后 ,GPS 就又要等1秒才能更新,这1秒内,是不是只能更相信加表了?这是肯定的,
就会越大,卡尔曼增益就越大,测量值权重就越大,校正时,最终估计值 就会越接近测量值 。校正完了之后 ,GPS 就又要等1秒才能更新,这1秒内,是不是只能更相信加表了?这是肯定的,
更新卡尔曼估计误差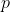
假如接近1,那么接近0,下次预测计算时,
就接近了,说明累积的误差清零了。校正完了之后 ,可以更相信预测值 ,随着预测更新次数增加。预测误差会更大,导致校正时,卡尔曼增益会更大,更加相信观测值 ,周而复始。
五、总结
总结卡尔曼滤波的更新过程为
1步,首先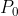 ,
,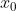 已知,然后由算出
已知,然后由算出 ,再由算出
,再由算出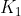 ,有了这些参数后,结合观测值就能估计出
,有了这些参数后,结合观测值就能估计出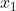 ,再利用更新
,再利用更新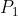
2步,然后下次更新过程为由算出 ,再由算出
,再由算出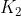 ,有了这些参数后,结合观测值就能估计出
,有了这些参数后,结合观测值就能估计出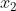 ,再利用更新
,再利用更新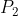
......
n步,由 算出
算出 ,再由算出
,再由算出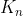 ,有了这些参数后,结合观测值就能估计出
,有了这些参数后,结合观测值就能估计出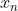 ,再利用更新
,再利用更新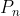
这就是卡尔曼滤波器递推过程。
至于的算法,

将代入上式右边最后一项中 , 保持原样
保持原样



(转载请声明出处 谢谢合作)
reference:
1、https://zh.wikipedia.org/wiki/%E5%8D%A1%E5%B0%94%E6%9B%BC%E6%BB%A4%E6%B3%A2
2、《矩阵分析与应用》 张贤达 著
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)