点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
SLAM包含了两个主要的任务:定位与构图,在移动机器人或者自动驾驶中,这是一个十分重要的问题:机器人要精确的移动,就必须要有一个环境的地图,那么要构建环境的地图就需要知道机器人的位置。
本系列文章主要分成四个部分:
在第一部分中,将介绍Lidar SLAM,包括Lidar传感器,开源Lidar SLAM系统,Lidar中的深度学习以及挑战和未来。
第二部分重点介绍了Visual SLAM,包括相机传感器,不同稠密SLAM的开源视觉SLAM系统。
第三部分介绍视觉惯性里程法SLAM,视觉SLAM中的深度学习以及未来。
第四部分中,将介绍激光雷达与视觉的融合。
激光雷达和视觉SLAM系统 说到激光雷达和视觉SLAM系统,必不可少的是两者之间的标定工作。
多传感器校准
Camera&IMU:Kalibr[1]是一个工具箱,解决了以下几种传感器的校准:
多摄像机校准。
视觉惯性校准(Camera IMU)。
卷帘快门式摄像机校准。
Vins融合了视觉与IMU,具有在线空间校准和在线时间校准的功能。
MSCKF-VIO具有摄像机和IMU的校准功能。
mc-VINS[2]可以校准所有多个摄像机和IMU之间的外部参数和时间偏移。
IMU-TK[3][4]还可以对IMU的内部参数进行校准。
论文[5]提出了一种用于单目VIO的端到端网络,融合了来自摄像机和IMU的数据。

单目与深度相机
BAD SLAM[6]提出了一个使用同步全局快门RGB和深度相机的校准基准。
•相机和相机:mcptam[7]是一个使用多摄像机的SLAM系统。它还可以校准内、外参数。
MultiCol SLAM[8]是一个multifisheye相机SLAM。此外,最新版本的SVO还可以支持多个摄像头。
•Lidar& IMU: LIO-mapping [9]引入了一种紧密耦合的Lidar-IMU融合方法。激光雷达与IMU的对准是一种在三维空间中激光雷达和六自由度姿态传感器之间寻找外部校准的方法。激光雷达的外部定标见[10][11]。博士论文[12]阐述了激光雷达校准的工作。

•Camera&Lidar:论文[13]介绍了一种概率监测算法和一个连续校准优化器,使摄像机和激光雷达的校准能够在线、自动地进行。
Lidar-Camera [14]提出了一种新的流程和实验装置,用于寻找精确的刚体变换,以利用3D-3D点对应对来Lidar和相机进行外部校准。
RegNet[15]是第一个利用扫描激光雷达和单目相机推断多模态传感器之间6自由度(DOF)外部校准的深卷积神经网络(CNN)。
LIMO[16]提出了一种基于LIDAR测量的深度提取算法,用于摄像机特征轨迹的提取和运动估计。CalibNet[17]是一个自监督的深网络,能够实时自动估计三维激光雷达和二维相机之间的六自由度刚体变换。Autoware也可以用于激光雷达和摄像机的校准工作。
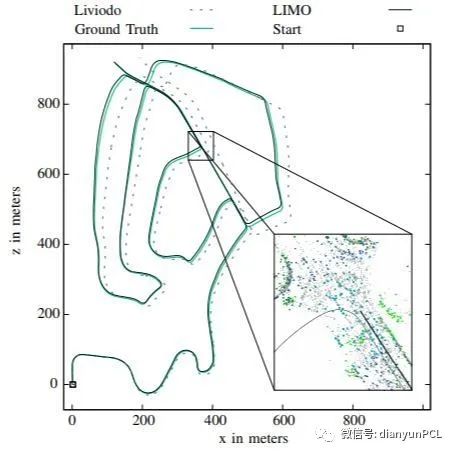
激光雷达与视觉融合
硬件层:比如Pandora是一款集40线激光雷达、相机和识别算法于一体的软硬件解决方案。集成的解决方案可以使开发人员从时间同步中得到舒适的体验。专心于算法的开发。
数据层:激光雷达具有稀疏、高精度的深度数据,相机具有密集但低精度的深度数据,两者的融合可以完成对图像中像素的深度值得修复.论文[18]仅依赖基本图像处理操作完成了稀疏激光雷达深度数据与图像的融合。随着深度学习的深入,[19]提出使用单一的深度回归网络直接从RGB-D原始数据中学习,并探索深度样本数量的影响。[20]考虑CNN在稀疏输入上运行,并应用稀疏激光扫描数据完成深度估计。
DFuseNet[21]提出了一种CNN,该CNN被设计用于基于从高分辨率强度图像中收集到的上下文线索对一系列稀疏距离测量进行上采样。
LICFusion[22]融合了IMU测量值、稀疏视觉特征和提取的LiDAR点云数据。

任务层:论文[23]是一种基于立体相机和激光雷达融合的感知方案。
[24]融合了毫米波雷达、激光雷达和相机,以检测和分类移动物体。
论文[25]通过深度相机提供的深度信息或者与相机相关联的激光雷达深度信息来增强VO。
V-Loam[26]提出了视觉里程计和激光雷达里程计相结合的总体框架。从视觉里程计和基于扫描匹配的激光雷达里程计两个方面入手,同时改进了实时的运动估计和点云配准算法性能。
VI-SLAM该系统将精确的激光里程估计器与使用视觉实现环路检测的位置识别算法相结合。[27]针对SLAM的跟踪部分,采用RGB-D相机和二维低成本激光雷达,通过模式切换和数据融合,构建稳健的室内SLAM系统。
VIL-SLAM[28]将紧密耦合的立体声VIO与激光雷达映射和激光雷达增强的视觉环路闭合结合在一起。[29]将单目摄像机图像与激光距离测量相结合,以允许视觉冲击,而不会因尺度不确定性增加而产生误差。在深度学习中,许多方法可以检测和识别来自摄像机和激光雷达的融合数据,如点融合[30]、RoarNet[31]、AVOD[32]、FuseNet[33]。[34]利用激光雷达和摄像机,以端到端可学习的架构完成了非常精确的定位。

融合SLAM的挑战与未来
数据关联:未来的SLAM必须是集成多个传感器的。但不同的传感器有不同的数据类型、时间戳和坐标系表达式,需要统一处理。此外,还应考虑多传感器之间的物理模型建立、状态估计和优化。
硬件集成:目前还没有合适的芯片和集成硬件使SLAM技术更容易成为产品。另一方面,如果传感器的精度因故障、非标称条件或老化而降低,则传感器测量的质量(例如噪声、偏差)与噪声模型不匹配。应遵循硬件的稳定性和集成性。前端传感器应具备数据处理能力,从硬件层到算法层,再到功能层到SDK,再到应用层进行创新。
众包:分散式视觉SLAM是一个强大的工具,用于在绝对定位系统不可用的环境中的多机器人应用。协同优化视觉多机器人SLAM需要分散的数据和优化,称为众包。分散数据处理过程中的隐私问题应引起重视。
高精地图:高精地图对机器人至关重要。但是哪种类型的地图最适合机器人呢?密集地图或稀疏地图可以导航、定位和路径规划吗?对于长期地图,一个相关的开放性问题是多久更新一次地图中包含的信息,以及如何确定该信息何时过时并可以丢弃。

适应性、健壮性、可延展性:众所周知,现在没有一个SLAM系统可以覆盖所有场景。为了在给定的场景中正常工作,其中大部分都需要大量的参数调整。为了使机器人感知为人类,基于外观而不是基于特征的方法是首选的,这将有助于在昼夜序列之间或不同季节之间形成与语义信息集成的闭环。
抗风险和约束能力:完善的SLAM系统应具有故障安全性和故障意识。这不是关于重定位或循环闭包的问题。SLAM系统必须具有应对风险或故障的能力。同时,一个理想的SLAM解决方案应该能够在不同的平台上运行,而不管平台的计算约束是什么。如何在精确性、稳定性和有限的资源之间取得平衡是一个具有挑战性的问题。
应用:SLAM技术有着广泛的应用,如:大规模定位、导航和三维或语义地图构建、环境识别与理解、地面机器人、无人机、VR/AR/MR、AGV(自动引导车)、自动驾驶、虚拟室内装饰、虚拟试衣间、沉浸式网络游戏等,抗震救灾、视频分割与编辑。

参考文献
【1】Joern Rehder, Janosch Nikolic, Thomas Schneider, Timo Hinzmann, and Roland Siegwart. Extending kalibr: Calibrating the extrinsics of multiple imus and of individual axes. In 2016 IEEE International Conference on Robotics and Automation (ICRA), pages 4304–4311. IEEE, 2016.
[2] Kevin Eckenhoff, Patrick Geneva, Jesse Bloecker, and Guoquan Huang. Multi-camera visual-inertial navigation with online intrinsic and extrinsic calibration. 2019 International Conference on Robotics and Automation (ICRA), pages 3158–3164, 2019.
[3] A. Tedaldi, A. Pretto, and E. Menegatti. A robust and easy to implement method for imu calibration without external equipments. In Proc. of: IEEE International Conference on Robotics and Automation (ICRA), pages 3042–3049, 2014.
[4] A. Pretto and G. Grisetti. Calibration and performance evaluation of low-cost imus. In Proc. of: 20th IMEKO TC4 International Symposium, pages 429–434, 2014.
【5】] Changhao Chen, Stefano Rosa, Yishu Miao, Chris Xiaoxuan Lu, Wei Wu, Andrew Markham, and Niki Trigoni. Selective sensor fusion for neural visual-inertial odometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10542–10551, 2019.
【6】Thomas Schops, Torsten Sattler, and Marc Pollefeys. Bad slam: Bundle adjusted direct rgb-d slam. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
[7] Adam Harmat, Michael Trentini, and Inna Sharf. Multi-camera tracking and mapping for unmanned aerial vehicles in unstructured environments. Journal of Intelligent & Robotic Systems, 78(2):291– 317, 2015.
【8】Steffen Urban and Stefan Hinz. MultiCol-SLAM - a modular real-time multi-camera slam system. arXiv preprint arXiv:1610.07336, 2016
【9】Haoyang Ye, Yuying Chen, and Ming Liu. Tightly coupled 3d lidar inertial odometry and mapping. arXiv preprint arXiv:1904.06993, 2019.
[10] Deyu Yin, Jingbin Liu, Teng Wu, Keke Liu, Juha Hyypp¨a, and Ruizhi Chen. Extrinsic calibration of 2d laser rangefinders using an existing cuboid-shaped corridor as the reference. Sensors, 18(12):4371, 2018.
[1] Shoubin Chen, Jingbin Liu, Teng Wu, Wenchao Huang, Keke Liu, Deyu Yin, Xinlian Liang, Juha Hyypp¨a, and Ruizhi Chen. Extrinsic calibration of 2d laser rangefinders based on a mobile sphere. Remote Sensing, 10(8):1176, 2018.
[12] Jesse Sol Levinson. Automatic laser calibration, mapping, and localization for autonomous vehicles. Stanford University, 2011
【13】Jesse Levinson and Sebastian Thrun. Automatic online calibration of cameras and lasers. In Robotics: Science and Systems, volume 2, 2013.
[14] A. Dhall, K. Chelani, V. Radhakrishnan, and K. M. Krishna. LiDARCamera Calibration using 3D-3D Point correspondences. ArXiv eprints, May 2017.
[15] Nick Schneider, Florian Piewak, Christoph Stiller, and Uwe Franke. Regnet: Multimodal sensor registration using deep neural networks. In 2017 IEEE intelligent vehicles symposium (IV), pages 1803–1810. IEEE, 2017.
[16] Johannes Graeter, Alexander Wilczynski, and Martin Lauer. Limo: Lidar-monocular visual odometry. 2018.
[17] Ganesh Iyer, J Krishna Murthy, K Madhava Krishna, et al. Calibnet: self-supervised extrinsic calibration using 3d spatial transformer networks. arXiv preprint arXiv:1803.08181, 2018.
【18】Jason Ku, Ali Harakeh, and Steven L Waslander. In defense of classical image processing: Fast depth completion on the cpu. In 2018 15th Conference on Computer and Robot Vision (CRV), pages 16–22. IEEE, 2018
【19】Fangchang Mal and Sertac Karaman. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1–8. IEEE, 2018.
[20] Jonas Uhrig, Nick Schneider, Lukas Schneider, Uwe Franke, Thomas Brox, and Andreas Geiger. Sparsity invariant cnns. In 2017 International Conference on 3D Vision (3DV), pages 11–20. IEEE, 2017.
[21] Shreyas S Shivakumar, Ty Nguyen, Steven W Chen, and Camillo J Taylor. Dfusenet: Deep fusion of rgb and sparse depth information for image guided dense depth completion. arXiv preprint arXiv:1902.00761, 2019.
【22】Xingxing Zuo, Patrick Geneva, Woosik Lee, Yong Liu, and Guoquan Huang. Lic-fusion: Lidar-inertial-camera odometry. arXiv preprint arXiv:1909.04102, 2019.
【23】Olivier Aycard, Qadeer Baig, Siviu Bota, Fawzi Nashashibi, Sergiu Nedevschi, Cosmin Pantilie, Michel Parent, Paulo Resende, and TrungDung Vu. Intersection safety using lidar and stereo vision sensors. In 2011 IEEE Intelligent Vehicles Symposium (IV), pages 863–869. IEEE, 2011.
【24】Ricardo Omar Chavez-Garcia and Olivier Aycard. Multiple sensor fusion and classification for moving object detection and tracking IEEE Transactions on Intelligent Transportation Systems, 17(2):525– 534, 2015.
【25】Ji Zhang, Michael Kaess, and Sanjiv Singh. Real-time depth enhanced monocular odometry. In 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4973–4980. IEEE, 2014.
【26】Ji Zhang and Sanjiv Singh. Visual-lidar odometry and mapping: Lowdrift, robust, and fast. In 2015 IEEE International Conference on Robotics and Automation (ICRA), pages 2174–2181. IEEE, 2015.
【27】Yoshua Nava. Visual-LiDAR SLAM with loop closure. PhD thesis, Masters thesis, KTH Royal Institute of Technology, 2018.
【28】Weizhao Shao, Srinivasan Vijayarangan, Cong Li, and George Kantor. Stereo visual inertial lidar simultaneous localization and mapping. arXiv preprint arXiv:1902.10741, 2019.
[29] Franz Andert, Nikolaus Ammann, and Bolko Maass. Lidar-aided camera feature tracking and visual slam for spacecraft low-orbit navigation and planetary landing. In Advances in Aerospace Guidance, Navigation and Control, pages 605–623. Springer, 2015.
[30] Danfei Xu, Dragomir Anguelov, and Ashesh Jain. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 244–253, 2018
【31】Kiwoo Shin, Youngwook Paul Kwon, and Masayoshi Tomizuka. Roarnet: A robust 3d object detection based on region approximation refinement. arXiv preprint arXiv:1811.03818, 2018.
[32] Jason Ku, Melissa Mozifian, Jungwook Lee, Ali Harakeh, and Steven Waslander. Joint 3d proposal generation and object detection from view aggregation. IROS, 2018.
[33] Caner Hazirbas, Lingni Ma, Csaba Domokos, and Daniel Cremers. Fusenet: Incorporating depth into semantic segmentation via fusionbased cnn architecture. In Asian conference on computer vision, pages 213–228. Springer, 2016
【34】 Ming Liang, Bin Yang, Shenlong Wang, and Raquel Urtasun. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), pages 641– 656, 2018.
本文仅做学术分享,如有侵权,请联系删文。
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~