1. 准备
Host:Ubuntu 16.04或18.04系统,配备鼠标、键盘、显示器,联网
Xavier:配备鼠标、键盘、显示器、HDMI转VGA接口(连接显示器和Xavier),开机后安装Ubuntu界面,命令如下:
cd ~/NVIDIA-INSTALL
sudo ./install.sh
sudo reboot now
2:连接
将Host与Xavier之间通过网线接到同一台交换机上,然后再通过USB进行连接。注意:主机和从机网段设置相同。之后利用lsusb命令查看是否已经将Xavier与主机连到一起了,如果命令行出现NVIDIA Corp,证明已经连接,可以开始刷机了
3:刷机
在Host上下载JetPack安装包,地址https://developer.nvidia.com/embedded/jetpack,4.2版本为.deb文件
在下载的终端
sudo apt install ./sdkmanager_0.9.11-3405_amd64.deb
安装完成后在终端输入sdkmanager进行启动,输入NVIDIA账号和密码,接下来步骤如下
(1)硬件
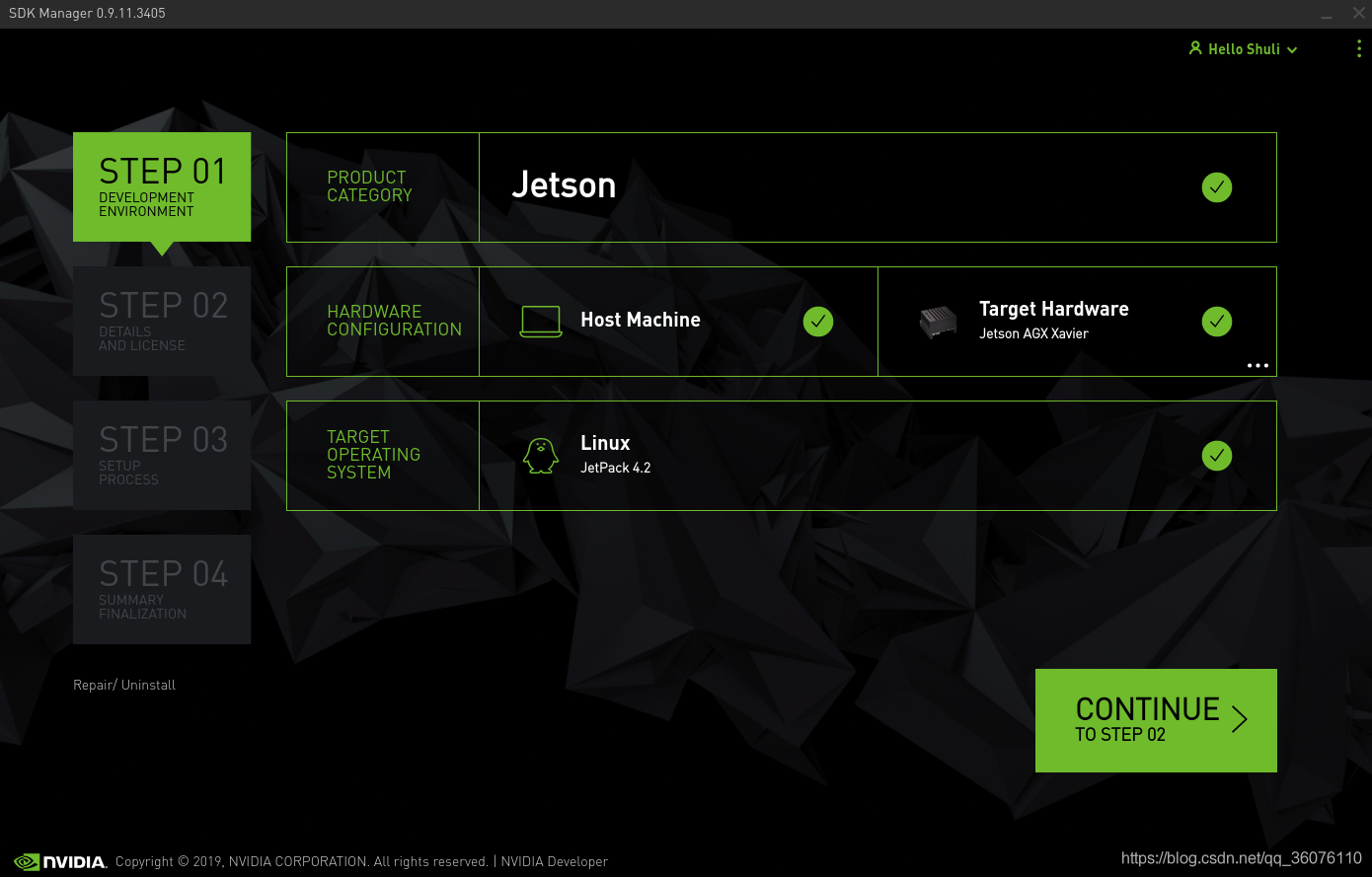
(2)软件
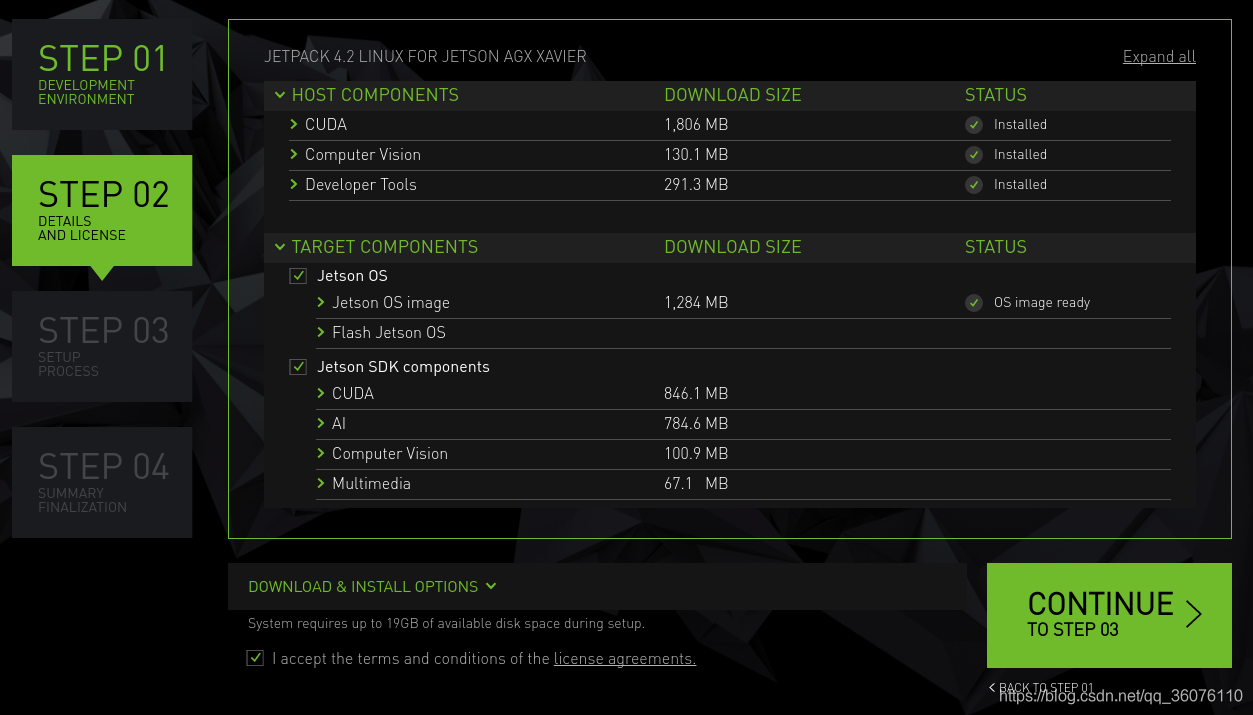
opencv可能会出现下载错误,需要安装或者移除一些东西之类,例如sudo apt-get remove libopencv-calib3d-dev
下载完成后,会出现自动还是手动界面,如果Xavier开机正常,选择自动,否则选择手动,按提示进行操作(网上也有很多教程)
(3)点击flash,会重启Xavier,按照向导进行设置,然后在Host里输入Xavier用户名和密码进行Jetson SDK components的安装
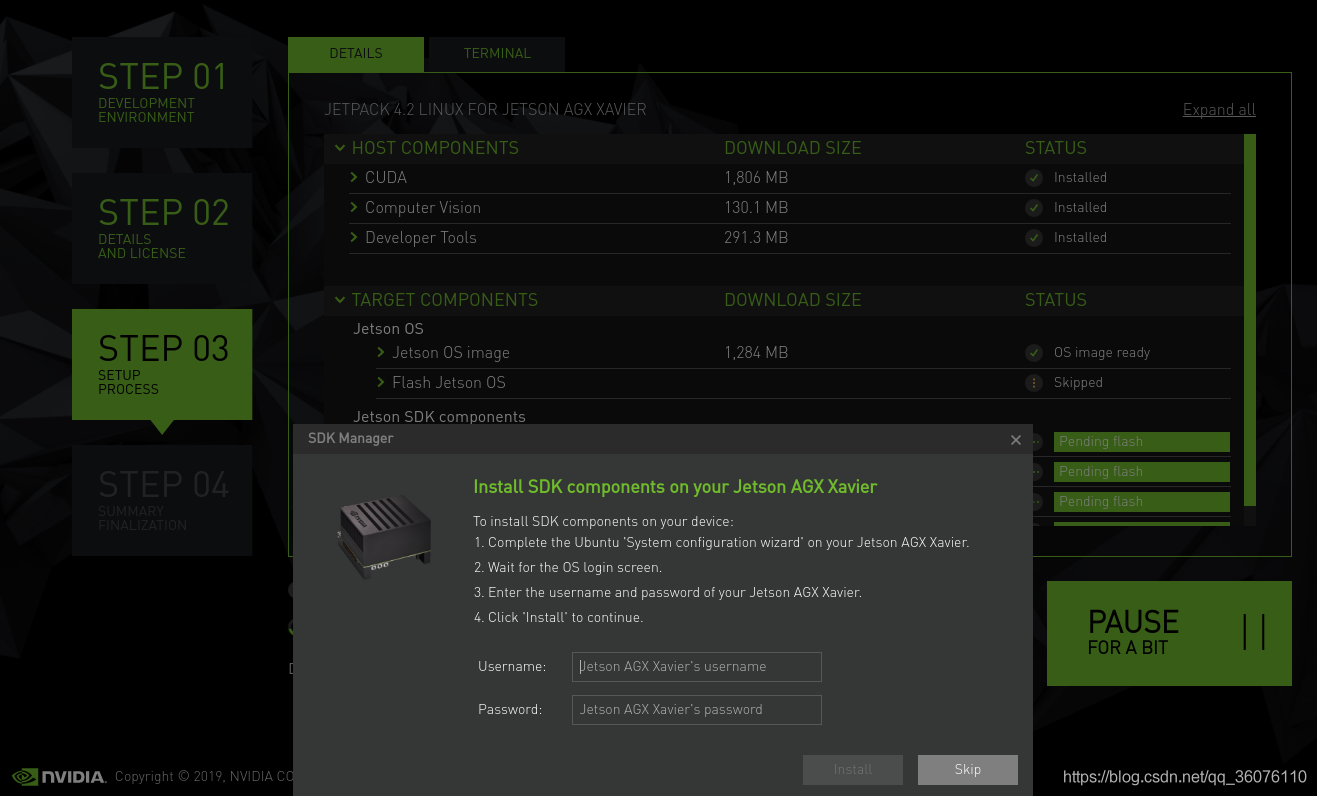
期间如果出现...cannot connect to the device via ssh ...的错误,在主机终端输入ssh nvidia@192.168.2.***,确保Host与Xavier网络始终连接,可通过ping 192.168.2.***查看是否连接正常
(4)安装完成
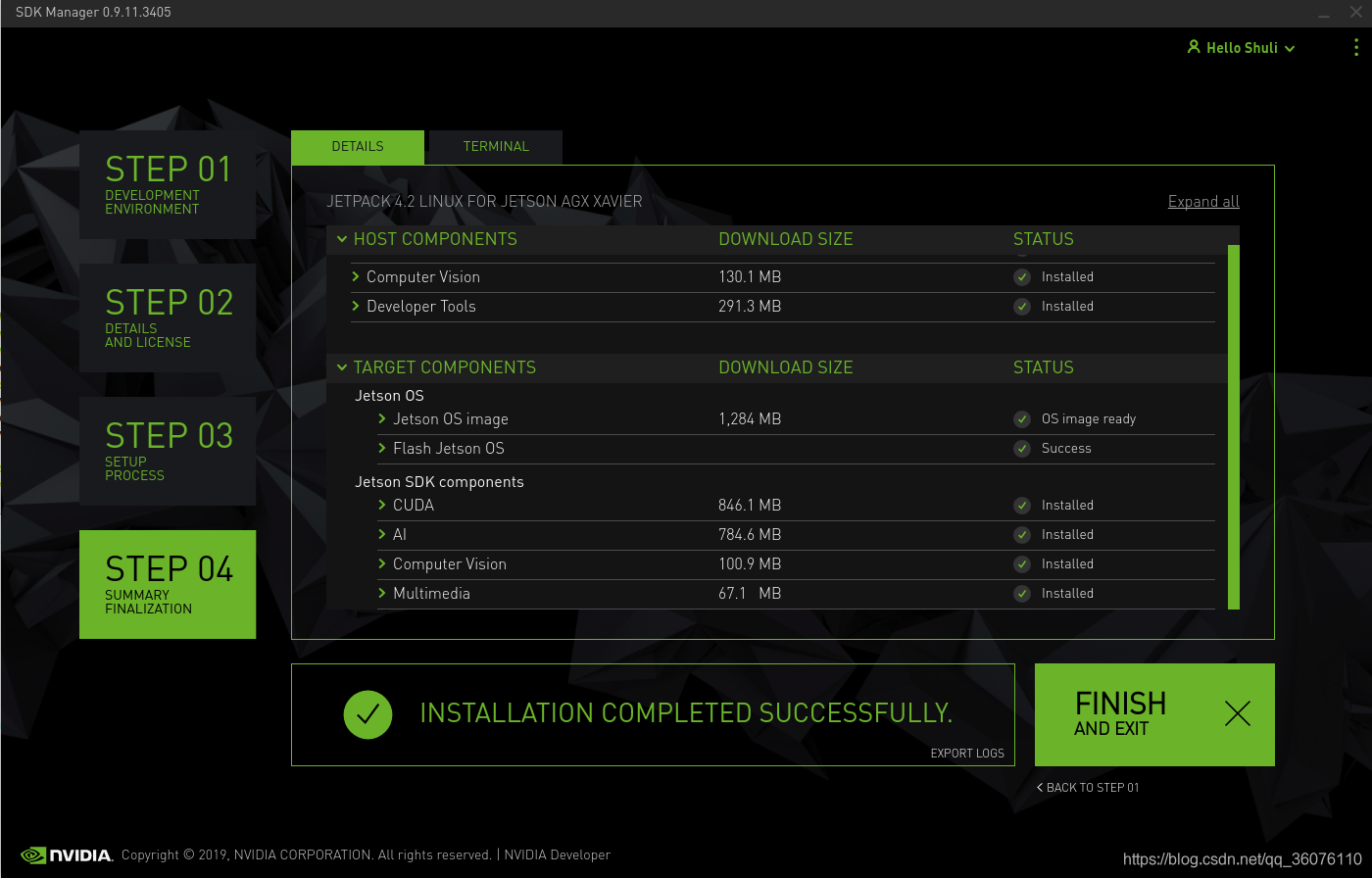
参考:使用jetpack 4.2为Xavier nano TX2刷机
玩转NVIDIA Jetson AGX Xavier(3)--- 使用JetPack 4.1为Xavier刷机
NVIDIA Jetson Xavier通过JetPack 4.1刷机教程(虚拟机版)
NVIDIA Jetson TX2:JetPack3.2.1刷机
第二次刷机小记:
1:主机先通过SDK下载安装包,注意只要下载从机上需要的就可以,不然特别耗费时间。
2:flash时,主机和从机通过Xavier自带的USB连接,自动模式即可(从机桌面系统已安装并且正常),从机会关闭,再自动重启,之后我们给从机设置用户名以及密码等,开机后重新连接网络,保证inatall时两者网段相同。
PS:新的刷机,新的体验!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)