2.1 机器学习的流程简介
- 进行机器学习的整体流程:
- 数据收集。
- 数据清洗(清洗重复或缺失的数据,以提高数据的精读)。
- 运用机器学习算法对数据进行学习(获取基准)。
- 使用测试数据进行性能评测。
- 将机器学习模型安装到网页等应用环境中。
- 我们将计算机依靠自己寻找答案,并从数据的模式中建立出的基准称为“模型”。在监督学习中,计算机通过使用包含正确答案标签的数据来实现学习。
2.2 学习数据的使用方法
-
在机器学习的监督学习中,我们将需要处理的数据分为“训练数据”和“测试数据”两种。
- 训练数据:学习过程中使用到的数据。
- 测试数据:在学习完成之后,对模型精读进行评估时所使用的数据。
-
机器学习是一门以构建模型对未知数据进行预测的学术体系;而统计学是分析数据对产生这一数据的背景进行描述的学术体系。
-
大多数情况下,相比训练数据,测试数据所占的分量较少,一般为20%左右。
-
划分数据的方法:
- 留出法:将所给的数据集划分为训练数据和测试数据这两种数据的一种简单方法。
# 导入执行代码时需要使用的模块
from sklearn import datasets
from sklearn.model_selection import train_test_split
# 读取名为iris的数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据保存到X和y中
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# test_size指定的是从整体数据中选择作为测试数据的比例,范围是0-1的数值
# random_state 固定数据。
# 确认训练数据和测试数据的大小
print("X_train :",X_train.shape)
print("y_train :",y_train.shape)
print("X_test :",X_test.shape)
print("y_test :",y_test.shape)
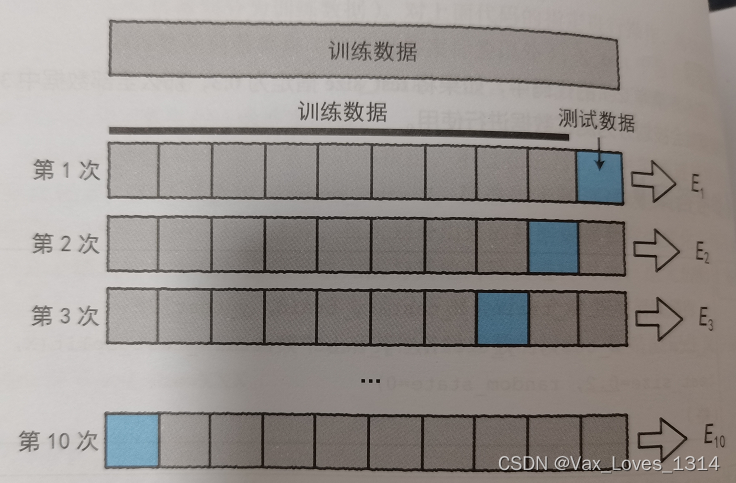
- k折交叉验证:使用无放回抽样,将训练数据集分割为k个子集,将其中的k-1个子集数据作为学习数据集使用,将剩下的1个子集数据用于模型测试的一种方法。因此需要进行重复k次的学习和评估,对得到的k个性能评估数据取平均值,从而计算出模型的平均性能。特殊的包括留一交叉验证,意指使用除某一行以外的所有数据进行学习,主要是处理非常小的数据。(交叉验证的优点是允许我们充分地利用手头的数据最大限度地对模型的性能进行评估。)
# 导入执行代码时所需要的模块
from sklearn import svm, datasets, model_selection
# 载入名为iris的数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 使用机器学习算法SVM
svc = svm.SVC(C=1,kernel="rbf",gamma = 0.001)
# 通过交叉验证计算得分
# 在程序内部,X,y会被分割为类似x、y、train和test的样式进行处理
scores = model_selection.cross_val_score(svc, X, y, cv=5)
print(scores)
print("平均分数:", scores.mean())
- 自助法:在留出法与交叉验证法中,会因训练样本规模的不同而导致估计偏差,留一法计算复杂度又太高,而自助法可以减少训练样本规模不同造成的影响,同时还能比较高效的进行实验估计。自助法在数据集较小、难以有效划分训练/测试集时很有用。此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法又很大的好处。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)