为什么需要二次排序?
在MapReduce操作时,我们知道传递的<key,value>会按照key的大小进行排序,最后输出的结果是按照key排过序的。有的时候我们在key排序的基础上,对value也进行排序。这种需求就是二次排序:
解决思路:
我们可以把key和value联合起来作为新的key,记作newkey。这时,newkey含有两个字段,假设分别是k,v。这里的k和v是原来的key和value。原来的value还是不变。这样,value就同时在newkey和value的位置。我们再实现newkey的比较规则,先按照key排序,在key相同的基础上再按照value排序。在分组时,再按照原来的key进行分组,就不会影响原有的分组逻辑了。最后在输出的时候,只把原有的key、value输出,就可以变通的实现了二次排序的需求.
二次排序的步骤
案例源码资料:http://pan.baidu.com/s/1i523w8H
1 自定义key。
mr中的分区和分组都和key相关,所有的key是需要被比较和排序的,需要二次排序时,先根据key中的第一个属性进行比较排序,第一个属性相同时,在第一个属性相同的情况下,再进行下一个的比较和排序;(程序员必知的8大排序:http://blog.csdn.net/qq_39532946/article/details/76228075)
所有自定义的key应该实现接口WritableComparable,因为是可序列的并且可比较的。并重载方法
2自定义分区类(继承Partitionner).
2.1 自定义分区函数类继承Partitioner。(第一次比较)。
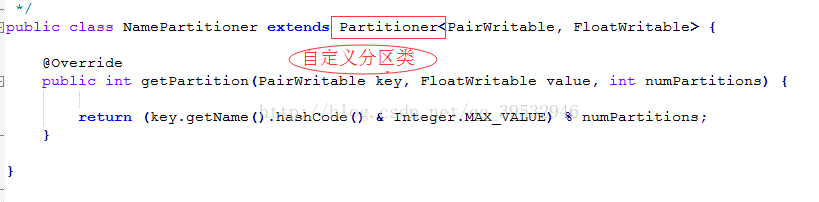
public static class FirstPartitioner extends Partitioner<IntPair,IntWritable>
在job中设置使用setPartitionerClasss
2.2 key比较函数类需要继承WritableComparator(第二次比较)。
public class PairWritable implements WritableComparable<PairWritable>{
private String name;//要比较的第一个字段,姓名
private float money; //要比较的第二个字段,消费金额
// shuffle过程中的排序就是根据此处的比较规则
public int compareTo(PairWritable o){
//先比较二者的name
int comp =this.name.compareTo(o.name);
if(0!= comp){
return comp;
}
//在第一个字段name一样的情况下比较money,基本数据类型是没有compareTo,需要装箱成包装类
//return(Float.valueOf(this.money)).compareTo(Float.valueOf(o.money));
return Float.valueOf(o.money).compareTo(Float.valueOf(this.money));
}
}
public static class KeyComparator extends WritableComparator
必须有一个构造函数,并且重载 public int compare(WritableComparable w1, WritableComparable w2)
另一种方法是 实现接口RawComparator。
在job中设置使用setSortComparatorClass。
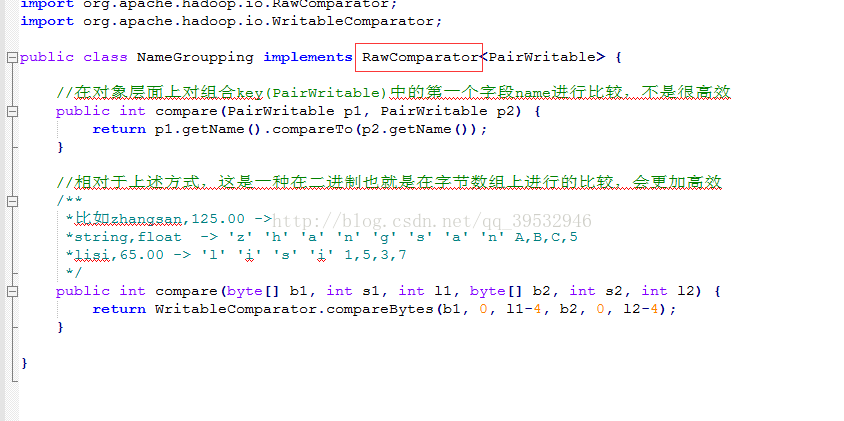
3自定义分组函数类,需要继承WritableComparator。
public static class GroupingComparator extends WritableComparator
必须有一个构造函数,并且重载 public int compare(WritableComparable w1, WritableComparable w2)
分组函数类另一种方法是实现接口RawComparator。
在job中设置使用setGroupingComparatorClass。
另外注意的是,如果reduce的输入与输出不是同一种类型,则不要定义Combiner也使用reduce,因为Combiner的输出是reduce的输入。除非重新定义一个Combiner。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)