官网:https://github.com/tkestack/gpu-manager
先夸赞一下腾讯的开源精神,再吐槽一下,官方README写的真是过于随意了。踩了一堆坑,终于部署并测试成功了。下面尽可能详细的记录一下全流程。
这次用的k8s集群是用kubeadm搭建的,在部署gpu-admission自定义scheduler的时候也有些不同,后面会详细介绍。
0、配置go环境
0.1 go安装
参考:https://www.runoob.com/go/go-environment.html
0.2 go代理配置(中国特色步骤,墙外可忽略)
vim /etc/profile
在文件最后添加如下两行:
export GOPROXY=https://goproxy.cn,direct
export GO111MODULE=on
1、部署gpu-admission
用gpu-manager前,需要先启动并正确配置gpu-admission。
官网:https://github.com/tkestack/gpu-admission
1.1 下载源码
git clone https://github.com/tkestack/gpu-admission.git
1.2 编译
①进入源码目录
cd gpu-adminssion-master
②编译
make build
1.3 运行
bin/gpu-admission --address=127.0.0.1:3456 --v=4 --kubeconfig <your kubeconfig> --logtostderr=true
其中<your kubeconfig>是k8s的config文件,就是每次kubectl命令会读取的那个配置文件。通常目录是/etc/kubernetes/admin.conf。
正确输出如下:
[root@gxnzx1274 gpu-admission-master]# bin/gpu-admission --address=127.0.0.1:3456 --v=4 --kubeconfig /etc/kubernetes/admin.conf --logtostderr=true
I0805 10:42:10.514078 93447 main.go:83] Server starting on 127.0.0.1:3456
I0805 10:42:10.514895 93447 reflector.go:175] Starting reflector *v1.Node (30s) from pkg/mod/k8s.io/client-go@v0.18.12/tools/cache/reflector.go:125
I0805 10:42:10.514989 93447 reflector.go:211] Listing and watching *v1.Node from pkg/mod/k8s.io/client-go@v0.18.12/tools/cache/reflector.go:125
I0805 10:42:10.515134 93447 reflector.go:175] Starting reflector *v1.Pod (30s) from pkg/mod/k8s.io/client-go@v0.18.12/tools/cache/reflector.go:125
I0805 10:42:10.515259 93447 reflector.go:211] Listing and watching *v1.Pod from pkg/mod/k8s.io/client-go@v0.18.12/tools/cache/reflector.go:125
1.4 自定义调度器
①准备自定义调度器文件
创建一个scheduler-policy-config.json的调度器文件:
vim /<Your Path>/scheduler-policy-config.json
其中<Your Path>是一个任意的目录,只要后面步骤里的<Your Path>和这里保持一致就行。
在这个json文件里写入如下信息(内容来自官方github步骤2.2):
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [
{
"name": "PodFitsHostPorts"
},
{
"name": "PodFitsResources"
},
{
"name": "NoDiskConflict"
},
{
"name": "MatchNodeSelector"
},
{
"name": "HostName"
}
],
"extenders": [
{
"urlPrefix": "http://127.0.0.1:10252/scheduler",
"apiVersion": "v1beta1",
"filterVerb": "predicates",
"enableHttps": false,
"nodeCacheCapable": false
}
],
"hardPodAffinitySymmetricWeight": 10,
"alwaysCheckAllPredicates": false
}
其中"urlPrefix": "http://127.0.0.1:10252/scheduler"中的IP地址和端口号,如果有特殊需求则按照需求更换,没有特殊需求这样写就可以了。
后面的步骤,如果是kubeadm安装的k8s就看1.4.1分支,如果是其他方式安装的k8s就看1.4.2分支。
1.4.1 kubeadm部署的k8s
kubeadm部署的k8s集群,调度器是以pod形式运行的,kubelet会一直监听manifest文件的修改,发现文件被修改后会自动重启pod以加载新的配置。因此,这里我们只需要修改调度器的manifest文件即可。
②先复制一份调度器的manifest文件备份。
cp /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/manifests/kube-scheduler.yaml.bak
③修改文件内容
vim /etc/kubernetes/manifests/kube-scheduler.yaml
在command关键字下面加两行内容:
- --policy-config-file=/<Your Path>/scheduler-policy-config.json
- --use-legacy-policy-config=true
修改前是这样的:
……
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.0
imagePullPolicy: IfNotPresent
……
修改后是这样的:
……
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
- --policy-config-file=/<Your Path>/scheduler-policy-config.json
- --use-legacy-policy-config=true
image: registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.0
imagePullPolicy: IfNotPresent
……
保存退出后就自动生效了。
可以用如下命令确定一下:
kubectl get po -A
输出中找到一个名字为 kube-scheduler-XXX 的pod,看后面对应的AGE项,是不是刚刚启动。如果刚启动过,代表调度器配置已经更新。
1.4.2 其他方式部署的k8s(gpu-admission官方步骤2.2)
非kubeadm部署的k8s是带有kube-scheduler工具的,使用kube-scheduler工具直接部署配置文件即可。具体操作如下。
② 执行命令
kube-scheduler --policy-config-file=/<Your Path>/scheduler-policy-config.json --use-legacy-policy-config=true
2、部署gpu-manager
2.1 下载源码
git clone https://github.com/tkestack/gpu-manager.git
2.2 编译源码
cd gpu-manager-master
make
2.3 构建gpu-manager镜像
① 修改源码(中国特色步骤,墙外跳过该步)
vim build/Dockerfile
找到如图所示第18行处

添加内容:
ENV GO111MODULE on
ENV GOPROXY https://goproxy.cn,direct
保存退出。
② 构建镜像
make img
构建完成后用如下命令查看是否生成了一个名为thomassong/gpu-manager的容器:
docker images
我这里构建完的镜像tag是1.1.4,这个tag要记一下,后面会用到,用的的时候用*tag表示。(主要是官方gpu-manager.yaml里的tag和make img中的tag没匹配,需要自己改一下,也许后面官方会修正)
③ 创建资源
kubectl create sa gpu-manager -n kube-system
kubectl create clusterrolebinding gpu-manager-role --clusterrole=cluster-admin --serviceaccount=kube-system:gpu-manager
④ 打标签
所谓的打标签,就是找一个节点来运行gpu-manager。我这里遇见了一个问题是给master打标签没用,只能找一个非master的节点来打标签。也就是gpu-manager不能运行在master上。
kubectl label node <node> nvidia-device-enable=enable
其中<node>是想要运行gpu-manager的k8s节点名称。
这里注意一下,之前步骤②中构建的镜像要保证在你所选择即将运行gpu-manager的节点上有才行。如果之前在其他节点构建的镜像,要迁移到<node>中来。
⑤查看镜像tag是否匹配
还记得步骤②中的*tag吧。这里要看一下gpu-manager.yaml文件中,关键字image后面的镜像tag是不是和*tag一致,如下图。如果不一致则修改成*tag。我这里是修改成了1.1.4的。
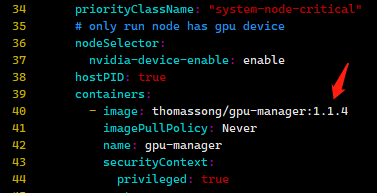
⑥ 启动gpu-manager
kubectl create -f gpu-manager.yaml
此时查看集群pod,kube-system命名空间下,有一个名为gpu-manager-daemonset-XXX的pod启动。
查看<node>节点信息发现,有tencent.com/vcuda-core, tencent.com/vcuda-memory 资源存在,如下图。
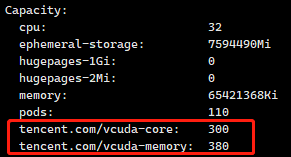
至此gpu-manager部署完成!
3、测试
这里我自己准备了一个paddle的镜像,并配套写了一个提交任务的yaml文件提供测试。镜像使用cifar数据集,可自动下载,非常方便。
测试思路:测试过程各位可自行修改yaml文件中tencent.com/vcuda-core, tencent.com/vcuda-memory资源的数值,先调节的大一些,看容器是否正常Running,容器log是否正确。都正确无误后,给tencent.com/vcuda-memory改的非常小,容器运行时GPU显存溢出,程序报错,容器退出,表明vcuda生效。
① 下载镜像
docker pull haidee/paddle:cifar-resnet-cuda10.0-cudnn7
② 提交任务
vim test.yaml
apiVersion: v1
kind: Pod
metadata:
name: vcuda
spec:
restartPolicy: Never
containers:
- name: nvidia
image: paddle:zyy-cifar-resnet
command: ["python3","/opt/train.py"]
resources:
requests:
tencent.com/vcuda-core: 50
tencent.com/vcuda-memory: 30
limits:
tencent.com/vcuda-core: 50
tencent.com/vcuda-memory: 30
kubectl create -f test.yaml
③ 观察
集群中名为vcuda的pod是否正常运行,并查看其log是否符合预期。
查看pod运行状态命令:
kubectl get po
查看log命令:
kubectl logs vcuda
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)