2022 - 再探宝可梦、数码宝贝分类器 — 浅谈机器学习原理_哔哩哔哩_bilibili
more parameters, easier to overfit, why?
但是怎么定这个有未知数的function呢、那通常假设你没有什么想法的话、往往你需要先对你的资料做一些观察、想象一下,假设有一个function可以成功的分类宝可梦跟数码宝贝、那这个function它应该长什么样子
所以,开始进行机器学习之前,也许我们先对资料进行一些观察。
好在经过一番观察以后。我发现 他们虽然长得很像,但其实还是有显著差异:画风不同

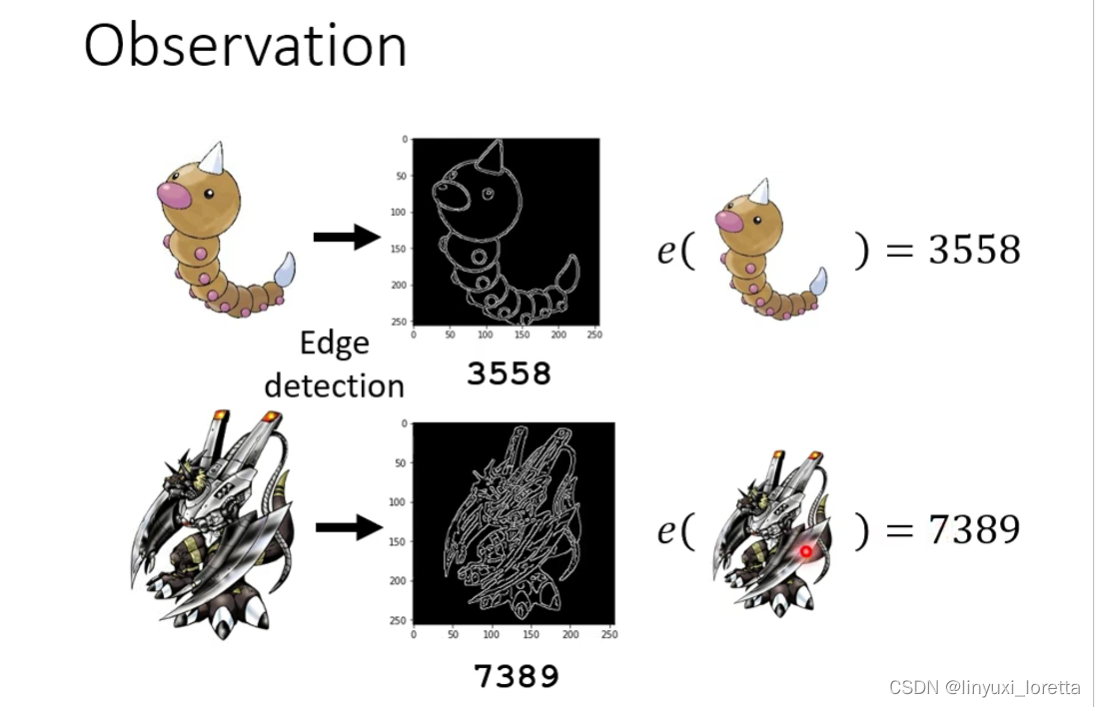
很多package呢可以帮你把一个图片里面的线呢把它画出来。细节不重要,总之扣一个library自动会产生这种边线的图
那怎么知道一张图片的边线比较简单还是复杂呢?算一下图里白色的pixel有多少
e函数代表,线条的复杂程度

func. f只有一个未知参数h
这个func. f完全可以一般化到更复杂的情景,比如 h可以换成之前录音里讲过的θ
未知参数 所有的可能性集合起来叫 H,他的可能性是你自己决定的,这里我们假设说做完边缘探测后白色点的数目不会超过1万,这里不需要考虑小数点
|H| 在H里有多少可能的选择,这个数叫做 模型的复杂程度
模型的复杂程度很高,代表说他现在定出来的这个含有未知数的func.里面,选择性很多

接下来我们来定loss,
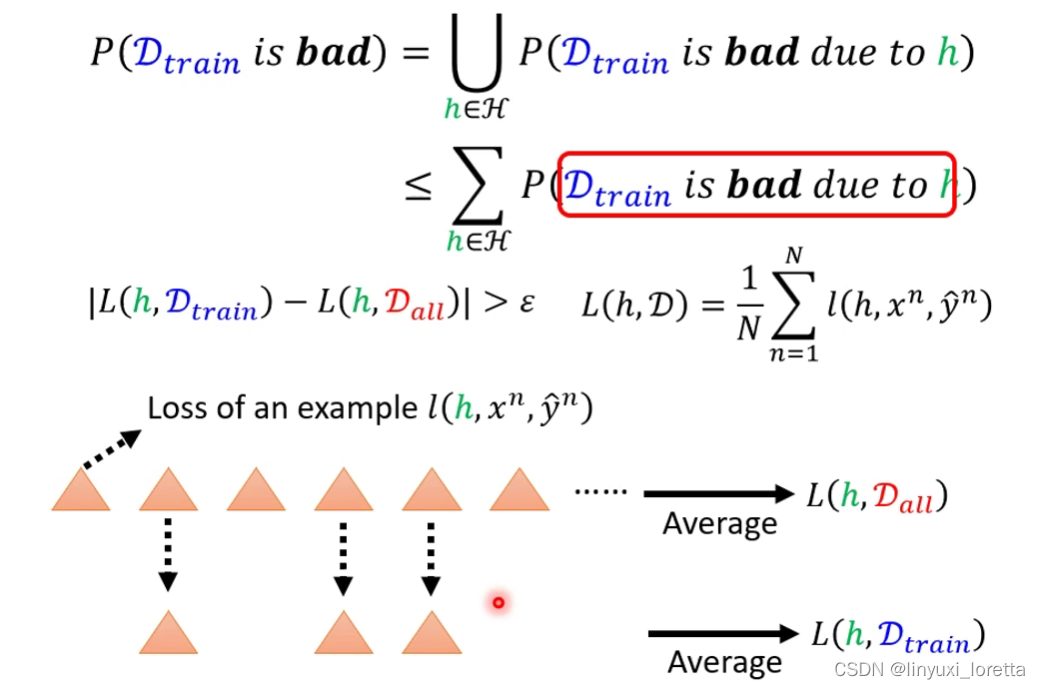
首先要有资料, loss是根据资料计算出来的,
给一个h,根据某一组dataset来计算loss
训练资料集,有个假设,训练资料集里的每一笔资料,是从一个更大的资料里被sample出来的,sample的过程有一个限制叫i.i.d.,独立同分布,即 sample每一笔资料时 每笔之间是independent,每次sample时分布永远是固定的,
有了D(train)之后,就可以找出一个h,让 用Dtrain所计算出的loss值 越小越好

期待理想和现实越接近越好,理想是找到一个h(all),用在D(all)上得到一个loss
h(train)和h(all)显然不同,因为是从不同的资料里找出来的,他们要minimize的loss func.是不一样的,loss func.不只是和h有关,也和define这个loss func.的资料有关
h(all)是D(all)上最好的h,
h(train)和h(all)到底有多大差距?

实际应用里,收集D(all)显然不切实际,所以常见做法是准备一个D(test),是从D(all)sample出来的,你期待这个D(test)对所有data是有代表性的
假设 图鉴里的819只宝可梦和971只digimon已经非常充足了,来看看分布长什么样?
我们把他的线条复杂程度画出来,分布如图,
纵轴代表有这种负责度的动物的个数

问题:even lower than h(all)?
但是,h(all)最低是说他在D(all) 这组data上、他的loss最低。并不代表他在所有可能的资料集上,他的loss 是最低的。
我们真正关心的是如果我们把h(train)用在D(all)上时,错误率是多少。

从D(train2)例子 我们得到结论,结果好坏 取决于你sample到什么样的资料

什么叫好的trainning data 用数学式表示:
δ是一个你自己设的数值,看你希望理想跟现实有多接近。大一点可以是0.1,小一点可以是0.00001
你只要能够sample到一个trainning的资料,满足:
对所有的h而言,计算在D(train)上 跟计算在D(all)上面的loss 差距<=δ/2
这意味着D(train) 跟D(all)很像,所以不管拿什么样的h过来,算出来的loss都是差不多的



classification和regression的差距只是loss func.不同
sample到一组坏的训练资料概率有多大?

怎么计算橙色点占有的几率总共多大?直接一个个点算显然很麻烦。下面的方法来估测:

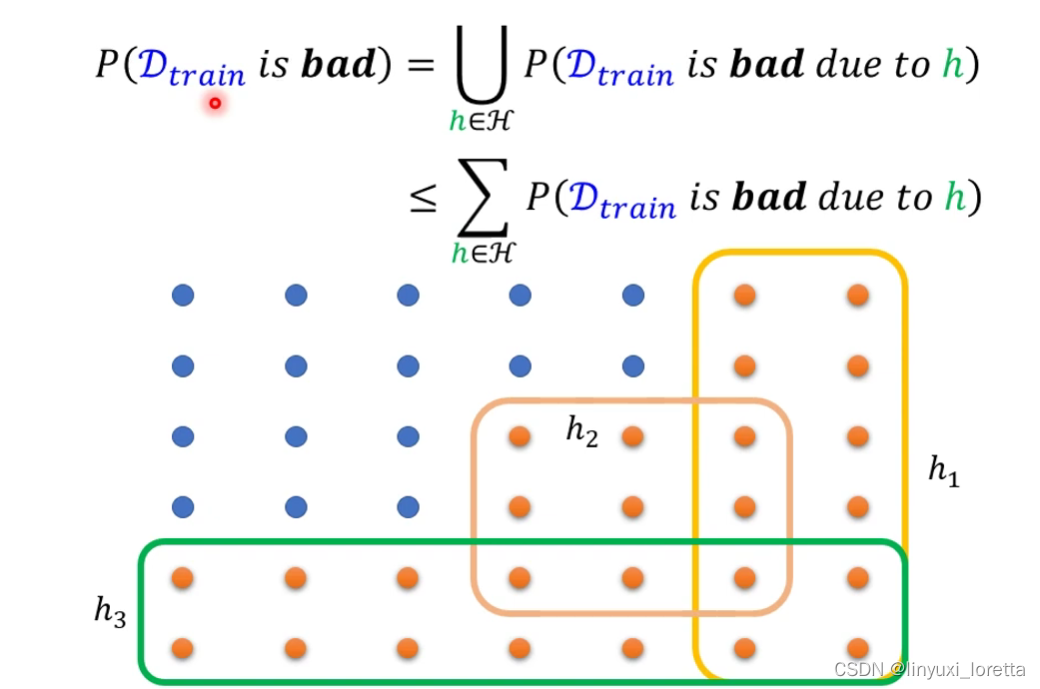
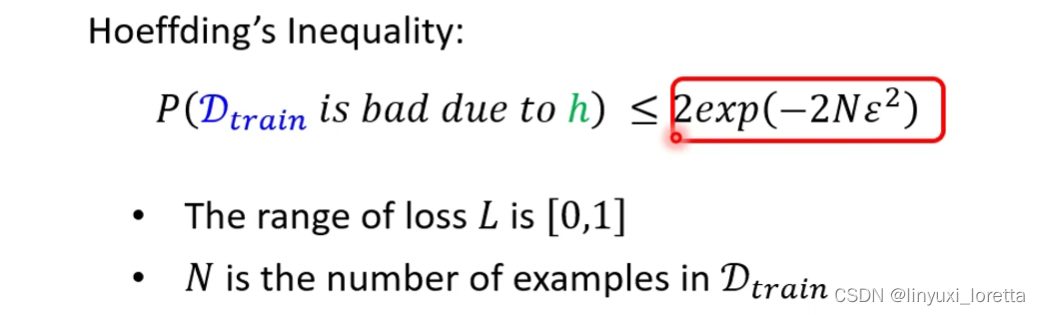
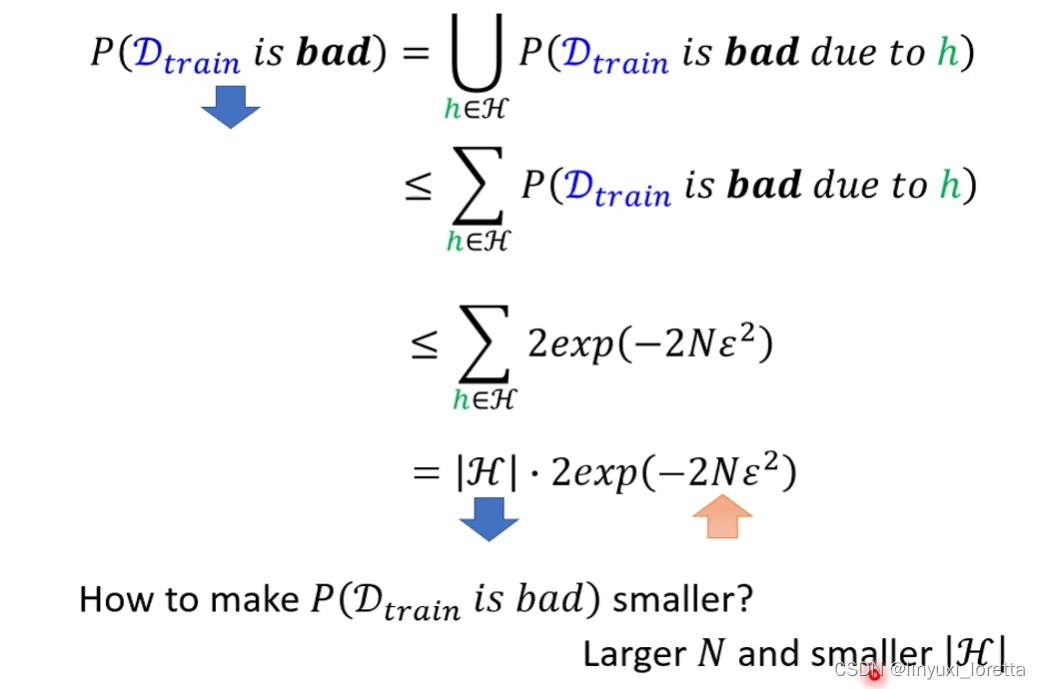
N调大,每一个h可以弄坏的training data set变少了,要把某一个training set弄坏的难度就增加了
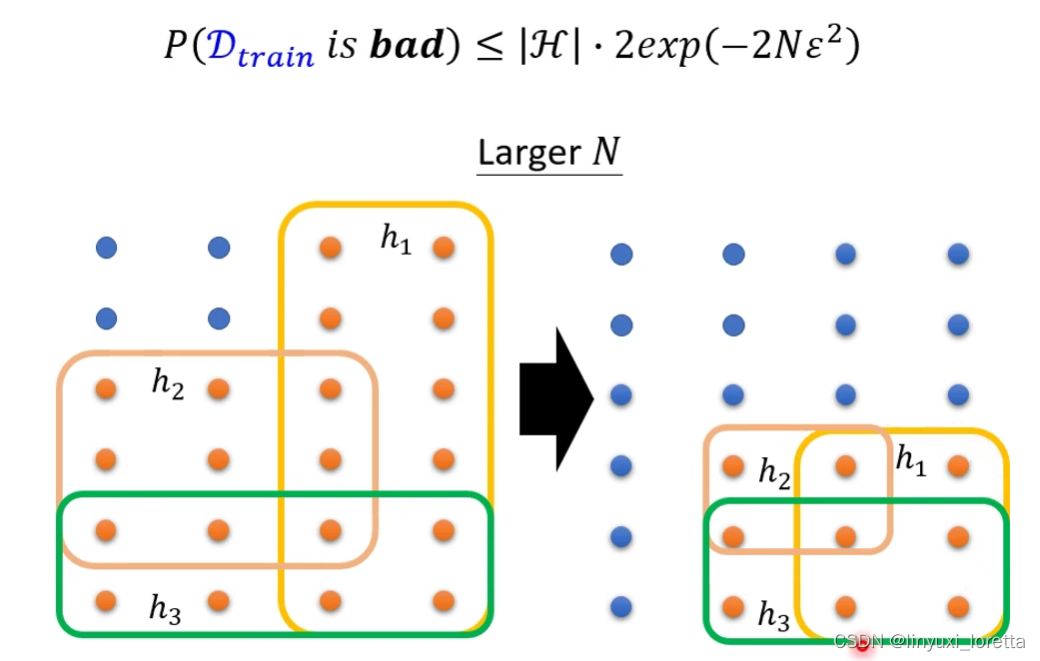
h数目变少,也可以让差的data set被sample到的几率变小

前者是说,训练集中实例数多了,直观看,实例越多,越接近真实分布,自然不容易得到坏模型;后者是说模型变简单了,少了一些参数,自然得到坏模型的概率就小了。

加总有超过1的情况时有发生,所以几乎没有人在实作上会特别把这些理论拿出来在实际资料上进行计算。
这个理论在试图解释原理,告诉你说 model 的complicity和训练资料到底对结果造成什么影响


VC-dimension 是一个方法,来计算一个参数是continues的模型的复杂程度

H很小时,可以选择的h就很有限,L(h(all), D(all))就没办法很小,”大海捞针,针不在海里“

2022 - 鱼与熊掌可以兼得的机器学习_哔哩哔哩_bilibili

why hidden layer?
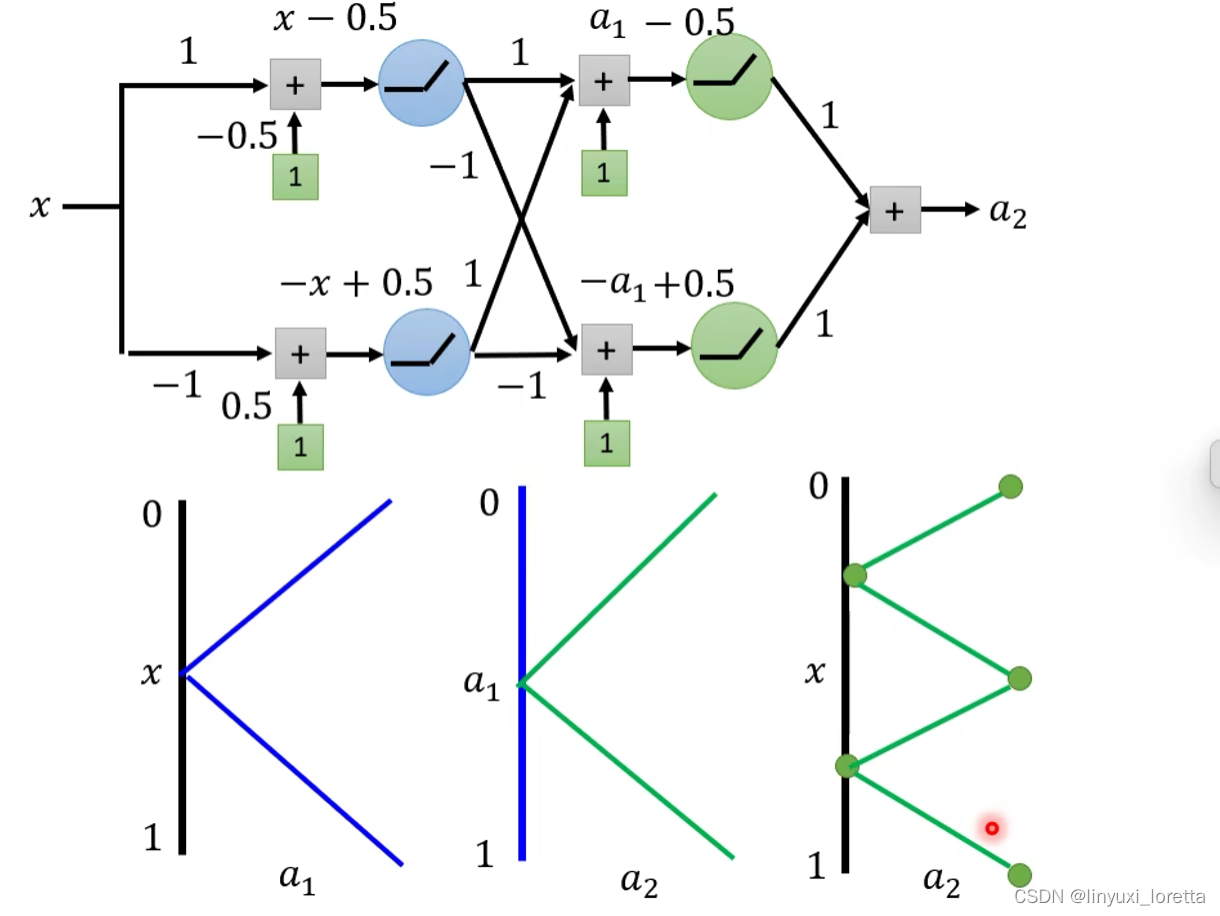
我们可以通过一个hidden layer,制造出所有可能的function
怎么用network逼近这条线
piecewise linear function可以逼近任何function
why deep?
e.g. 语言辨识

早年 :
一小段一小段的声音讯号,预测属于哪个phononing
WFST rule-based,phononing转成文字
现在:你可以弄个Seq2Seq 的model,丢进声音讯号,直接输出文字

deep learning真正的优势,当你要产生某个function时,需要较少的参数,比较不容易overfitting
奇偶校验(Parity Check)
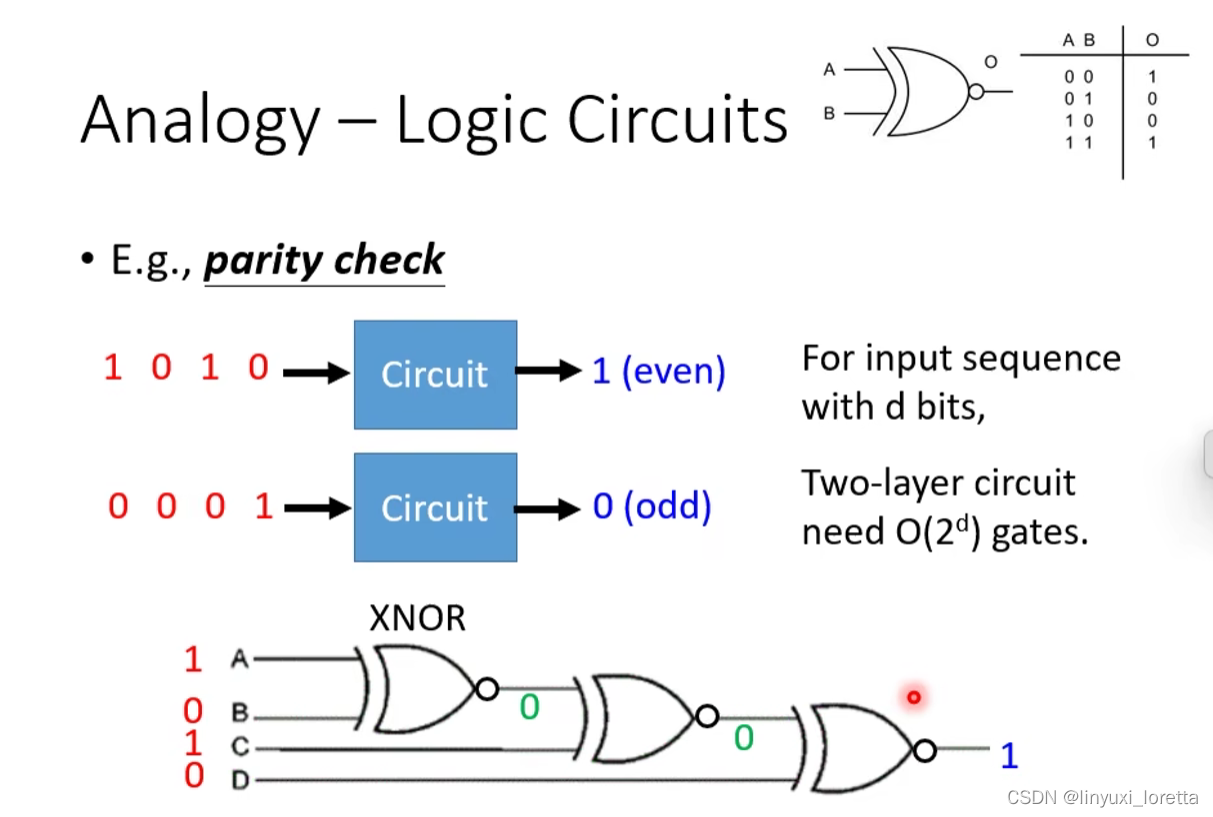
d是输入的sequence的长度,
relu就是y=x(x>0),y=0(x<0)



目标function 复杂且有规律,deep network更优,
需要多复杂: y=x^2 even 可以

复习;为什么需要深度学习?为什么需要hidden layer?
【合集】深度学习理论_李宏毅_Deep Learning Theory_哔哩哔哩_bilibili

每个network都是一个function
给定一个structure,填入不同的参数,得到的是一个function space
network structure:决定了neuron怎么连接,但没确定参数
deep 为什么比较好?

给定一个function,兜不同架构的network ,
同样的参数量下,deep network可以fit的比较好
或者希望network fit 目标函数到某一个精确度,deep network需要的参数量是比较少的


can shallow network fit any function?
(shallow network指只有一个hidden layer)

universality theory:任何continuous的function 都可以用一个只有一个hidden layer的network来fit
证明:
一个由ReLU的activation function所组成的network,他定义出来的function,长相都是piecewise linear的,

L-Lipschitz function,一个比较smooth的function
output 变化会被bound在某个范围内,


L越大 代表function变化越快,越复杂,自然需要越多neuron 去fit
ε代表,fit的accuracy, ε越小,要求的精准度越高,需要的neuron越多
CONTINUOUS...
梯度下降法

在做梯度下降,就好像在玩帝国时代,
地图上多数地方都未知,这个地图上的海拔就是loss func,的值,现在要找海拔的最低点,冲撞车所在的位置就代表了一组参数,现在我们要用梯度下降方法,改变冲撞车位置, 调整参数,找到loss最低的地方,
首先随机初始一个位置,看看周围哪里比较低,就往低的地方走一步,重复,直到环顾四周最低的时候停下来,local minima,但是我们永远不会知道是不是global minima,除非开天眼

为什么用梯度下降法,update参数loss会不降反增,
人物前面比较低、右边比较低、按照梯度下降法,应该往右前方踏出一步,
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)