题目:每天的日活数及新用户占比
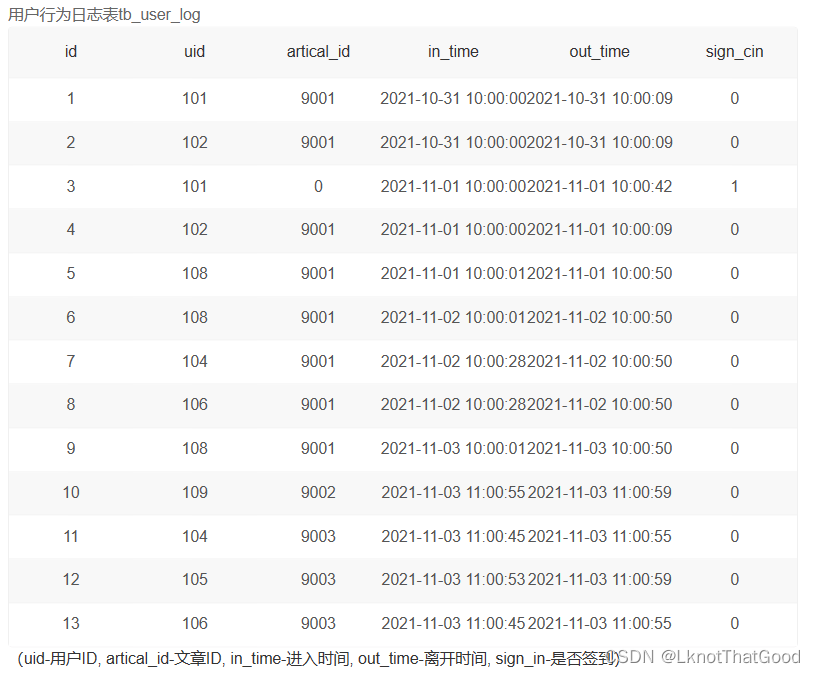
- 新用户占比=当天的新用户数÷当天活跃用户数(日活数)。
- 如果in_time-进入时间和out_time-离开时间跨天了,在两天里都记为该用户活跃过。
- 新用户占比保留2位小数,结果按日期升序排序。

Solution
题目要求的日活以及新用户占比,一共涉及两个指标,维度为日期。由于题目说如果in_time-进入时间和out_time-离开时间跨天了,在两天里都记为该用户活跃过。所以这里首先需要将进入时间和离开时间进行去重合并。代码如下:
select
uid,
date(in_time) as dt
from
tb_user_Log
union
select
uid,
date(out_time) as dt
from
tb_user_log
接下来是就是求新用户,我们只需要选取用户登录的最早日期并根据uid分组,就可以计算出用户的作为新用户的时间了。代码如下:
select
min(date(in_time)) as dt,
uid
from
tb_user_log
group by
uid
将上述的两段代码各封装成子表t1和t2并根据维度dt进行连接,就可以用于求解题目的两个指标。这里需要特别注意的是join的选取。在根据dt进行连接后,由于用户是在特定的某一天里成为新用户的,也就是说在其它的日期里用户只是作为活跃用户存在,所以在进行连接时不能保证一定能连接上新用户对应的子表。所以如果把新用户的子表封装t1,登录表封装成t2,那么连接时应该用的是t1 right join t2 on t1.dt = t2.dt。
此时代码可变为如下:
select
t2.dt,
--dau
--uv_new_ratio
from
(
select
min(date(in_time)) as dt,
uid
from
tb_user_log
group by
uid
)t1
right join
(
select
date(in_time) as dt,
uid
from
tb_user_log
union
select
date(out_time) as dt,
uid
from
tb_user_log
)t2
on
t1.dt = t2.dt
group by
t2.dt
order by
dt;
最后就是两个指标的求解了,新用户用count(distinct t2.uid)进行表示即可。而新用户占比则用
count(distinct t1.uid) / count(distinct t2.uid)进行表示。这里要注意为什么要用分子也要用distinct, 明明t1表里已经根据uid分组了,这是因为在right join的时候可能存在多行匹配的情况(即作为新用户的那天里一个用户多次登录),导致数据被放大的情况,所以需要用distinct进行二次去重。所以最终代码如下:
select
t2.dt,
count(distinct t2.uid) as dau,
round(count(distinct t1.uid)/count(distinct t2.uid), 2) as uv_new_ratio
from
(
select
min(date(in_time)) as dt,
uid
from
tb_user_log
group by
uid
)t1
right join
(
select
date(in_time) as dt,
uid
from
tb_user_log
union
select
date(out_time) as dt,
uid
from
tb_user_log
)t2
on
t1.dt = t2.dt
group by
t2.dt
order by
dt;
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)