编者按:
若言琴上有琴声,放在匣中何不鸣?
若言声在指头上,何不于君指上听?
苏轼的《琴诗》暗示了全局认知对于场景理解的重要性。而在图像理解领域,相较于基于精细标注数据的全监督学习,弱监督学习本质上是一种试图从全局出发来理解场景的方式,也更接近于人类对世界的认知机制。本文中,来自南开大学的程明明副教授,将从局部认知拓展至全局认知,为大家介绍面向弱监督的图像理解。大讲堂特别在文末提供文章以及代码的下载链接。
我报告的主题是“面向弱监督的图像理解”,并对我们组的相关工作进行总结和介绍。
本次报告中介绍的所有工作代码都是开源的,大家可以扫描图中二维码获取我们主页进行下载。
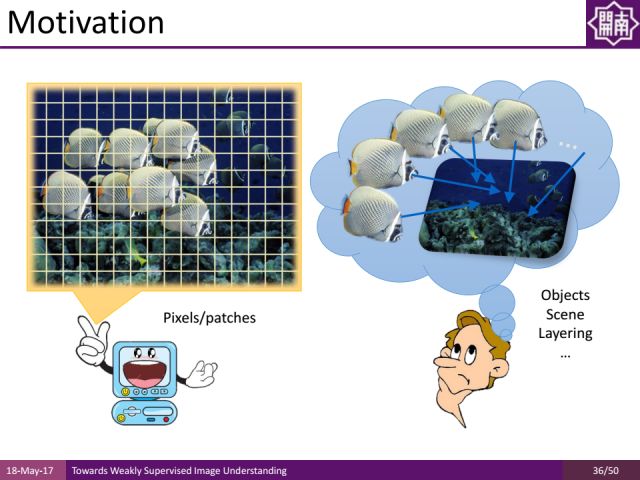
理解图像信息是计算机视觉的重要部分,我们希望计算机能够像人的眼睛一样看见并理解图像中的内容。
现在计算机视觉领域的大多数问题还是依赖于特定的数据集进行训练和测试评估的。
而Data annotation(数据标注)的成本是极其高昂的。比如,对于PASCAL VOC数据集,需要十余工人来标注27374个bounding box(标注框),而对于ImageNet甚至需要25000名人员对上千万张数据进行标注。MIT的Antonio Torralba曾经在CVML会议上讲过一个非常有意思的故事,他的退休的母亲帮他做了20余万分割目标的精细标注,他开玩笑说希望有更多的父母参与到这份工作中来。
如图,是ADE20K数据集的一张图片,针对分割任务标注起来是非常困难的。一方面高质量的图像标注为我们进行图像理解提供了方便,另一方面,获取这样的标注是非常困难和耗时的。而回顾我们从小识物的过程,父母都是指着不同物体告诉我们每一个物体是什么,而不用精确地描绘物体的轮廓。这种从物体层面的认识区别于现有多数算法对像素精度标注的依赖。
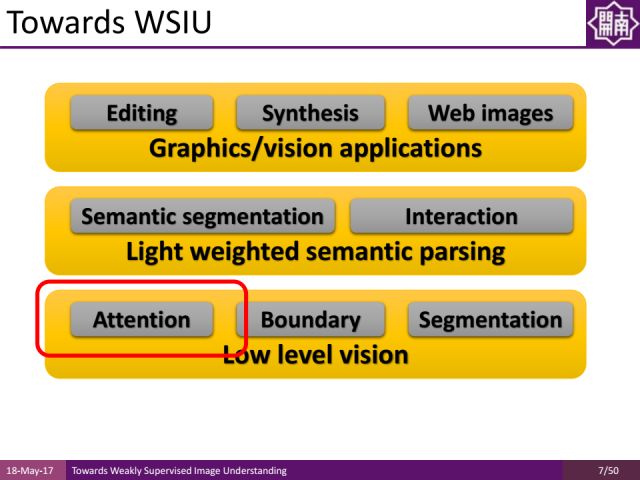
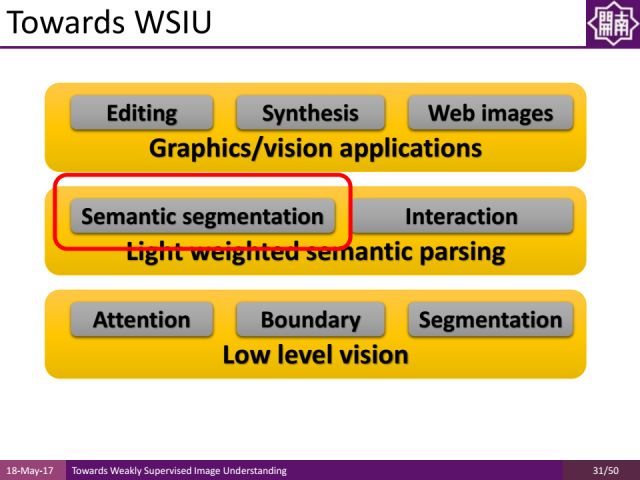
这里我们对近期的工作做了一些梳理。在low level vision层面,我们做了一些基于attention mechanism(注意力机制)的工作,以及边缘检测和区域分割工作来对图像进行预处理和category-independent的图像分析,注意力机制可以帮助我们准确快速地定位图像的区域,而不需要进行人工分割。
在light weighted semantic parsing方面,我们一方面将介绍语义分割,另一方面介绍它和interaction的结合。
最后,为大家介绍它们在图像及视觉领域的应用,比如进行editing(编辑)、Synthesis(合成)、web images(网络图片)方面的工作。
视觉注意力机制在图像认知中起到了非常重要的作用。对于机器而言,传统方法采用滑动窗口机制来检测图像中的每一个位置可能是什么样的物体,而人类观察图像并不是基于滑动窗口的机制对上百万个图像窗口进行搜索和检测,往往是借助很强的注意力来定位可能的物体区域,只是判断少量潜在物体区域的具体类别信息,这能够帮助我们进行快速有效地识别,并摆脱对大数据的依赖。
注意力机制有几个重要的分支:其一为fixation prediction,旨在预测出图像中的注视点,这个注视点有可能是bottom-up与任务无关的,还有可能是top-down与当前任务相关的;其二为salient object detection(显著性物体检测);其三为objectness proposals,它是基于窗口的度量方法,通过预测图像中的每个窗口有多大可能性含有物体,有助于后期做物体检测。
首先介绍我们基于全局对比的显著性区域检测工作。我们通过对图像预分割,根据图像区域和其他所有区域的对比度来计算显著性物体的区域。我们将在后面介绍如何用它来进行弱监督的学习。
在公开数据集上的测试结果显示我们的方法相对于传统方法有较大的提升。
刚才的工作无论是选择特征还是特征组合都是基于人手工的方法来做的。我们提出了基于学习的方式进行显著性物体检测,对每个区域提取特征,基于机器学习的方式自动选择特征的组合,这样能得到更好的分割结果。这个工作也取得了非深度学习方法中最好的结果。
如果大家对我们的这方面工作感兴趣,可以看这篇Benchmark综述文章,我们基于40多个主流的数据集进行了实验比较。
除了对特征的组合进行学习,我们去年CVPR上有一个工作通过深度方法对特征本身也进行学习,来得到显著性物体的区域。通过把不同层次的深度特征结合起来,通过一些short connections(短连接)的形式,能得到非常好的显著性物体检测结果,
我们采用多层次的信息融合方式,如上图中间所示,它是一种深度神经网络架构。对于我们的方法,越高层的卷积运算,可以得到更加大尺度的信息。我们把不同尺度信息通过short-connection层连接起来,同时通过side output做指导,能够得到更好的显著性物体检测的结果。
近几年,显著性物体检测取得了很大的进步。在很多公开数据集上,显著性物体检测的结果已接近实用,比如在MSRA-B和ECSSD数据集上precision和recall都已达到了90%以上的结果,同时missing error都已下降到零点零几的水平。由此启发我们是否能将它用于弱监督学习中去,从显著性物体检测的结果来学习知识。
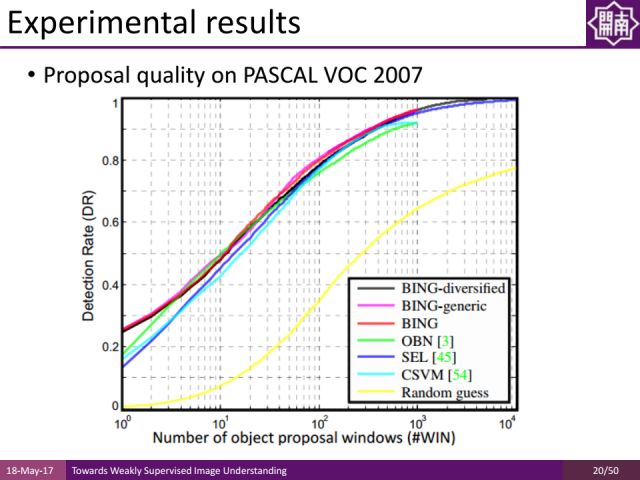
物体是由闭合轮廓围成的区域并有其重心,我们在2014年的一个工作中据此设计了一种根据图像梯度估计图像中区域可能含有物体的可能性的方法。
在PASCAL VOC2007数据集上进行测试,我们的方法和传统的方法效果基本接近,但是我们的方法速度要快出1000倍。
除了注意力机制,边缘检测也是对弱监督学习非常有帮助的。
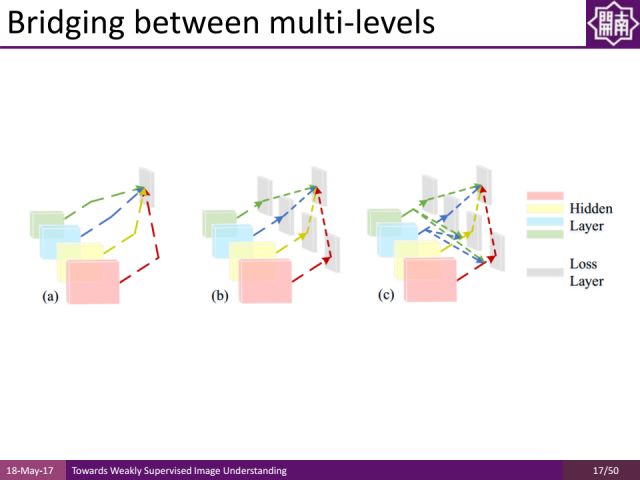
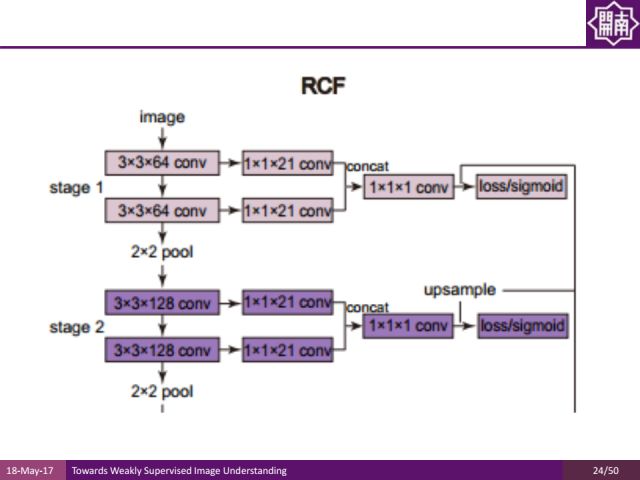
这是我们近期发表在CVPR2017的边缘检测方面的工作。我们发现在不同的卷积层都有不同的有用信息,与其从池化层的前一层中拿出来做整合,不如提出所有卷积层的信息充分利用。
传统上我们在几次卷积运算之后再做池化,中间层的特征只利用池化前的最后一层。我们新的工作把不同层的信息叠加起来,通过concat的方式来得到更加丰富的特征表达,通过这样的特征表达来训练边缘检测的结果。
这样的方法也达到了非常好的效果。比如在pascal voc数据集上,我们的方法是国际上首个能够实时运算,并且结果的F measure值已经超过当时在伯克利segmentation dataset上的人类平均的标注质量的方法。
此外,在low level vision里面,还有分割问题。通过对图像分组得到很多区域,期望每一个region里面只含有一个物体类别,作为比较强的约束信息可以帮助我们更好地理解图像内容。
这里边一个例子就是,我们曾经用显著性物体检测的结果帮助我们initialize图像的区域,然后通过iteratively run GrabCut的方法分割出图像中的重要物体区域。这些分割信息加上keyword 信息本身可以帮助我们生成一些高质量的pixel-accurcy label(像素层面的图像标签),来更好地做语义分割。
除了做语义分割之外,我们直接用图像处理的方式(比如显著性物体检测、分割等)进行处理,我们对Internet image做object segmentation和显著性物体检测,借助一些关键字在分割里面做retrievel,得到这些retreival信息后,top ranking里面的retrieval results信息很多都是我们需要的物体类别,通过物体类别自动获取的example 包括它的分割信息去学习一些apperance model学习一些更加重要的知识,通过这些知识来更新我们对显著性物体的理解。
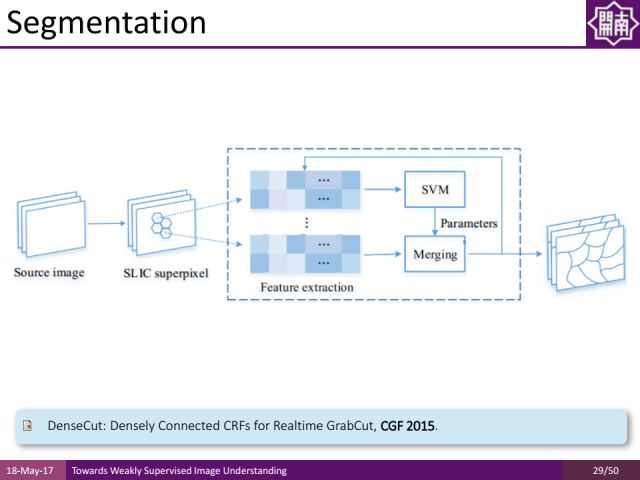
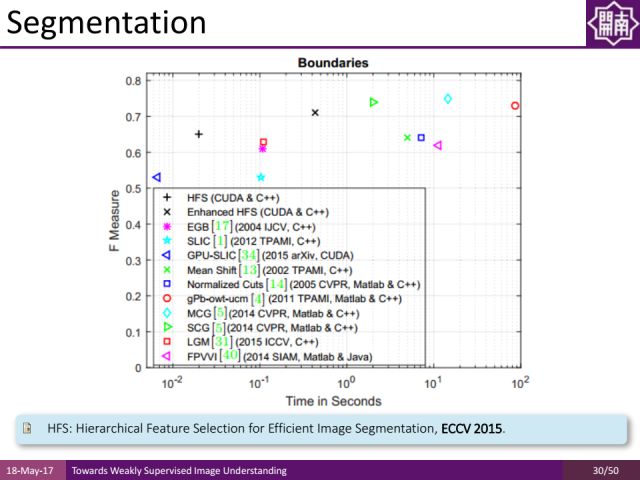
还有一个分割的工作是对图像做over segmentation,就是把图像分成很多块,我们希望每个块都不要跨越多个物体,因为同一个块通常只属于其中一个物体,哪怕区域里面有一些噪声,通过平均抑制噪声让分割信息更好,之前常用的over segmentation方法是efficient graph based image segmentation,其缺点是比较慢,因此我们在ECCV2016提出了一种基于GPU的方法对图像预处理而得到superpixel(超像素),然后对超像素提取特征并通过SVM(支持向量机)去学习一些特征组合,再对特征组合进行融合来得到非常好的结果。
在伯克利的数据集上我们的方法取得了非常好的结果,速度上每秒能处理几十上百张图像,F measure值也不错,可以作为low-level领域的一个很好的工具去更好地约束弱监督学习的方式。
Light Weighted Semantic Parsing
之前介绍的low level vision领域的注意力机制、边缘检测、图像分割相关工作结果都和图像的object category(物体类别)无关,因此这些信息就可以直接地运用到图像中去,帮助我们约束一个问题。比如图像里只含有一个物体,训练集里哪怕没有语义分割信息只有关键字信息,也会帮助我们去做语义分割。
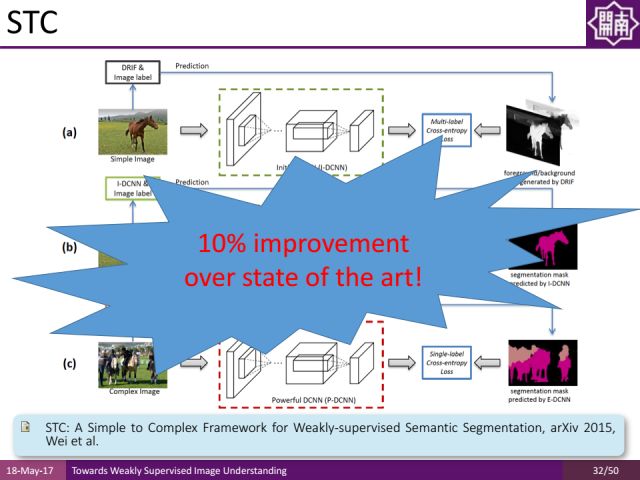
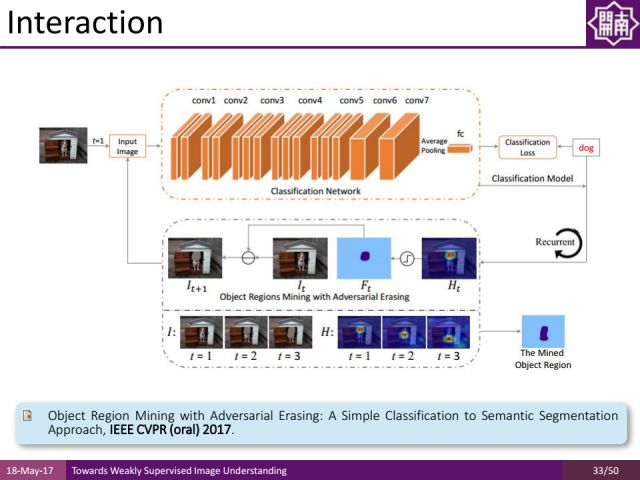
这里介绍我们的一个工作(STC:A Simple to Complex Framework for Weakly-supervised Semantic Segmentation)。通过显著性物体检测的结果,自动地生成语义分割的标签。通过low-level vision得到的约束能够帮助我们在弱监督的语义分割的学习中,减少对人工标注的依赖。
上一个工作是通过bottom-up的方式进行分割,发表在CVPR2017的另外一个工作使用一种top-dowm的方式。比如针对一个分类任务,可以通过attention network找到哪个区域属于哪类别,通过迭代使用top-down的注意力机制,更好地实现语义分割。
从实验结果可以得知,虽然只有keyword的监督信息,语义分割的结果通过top-down attention机制也能得到很好的改进。
除了语义分割之外,通过light weighted semantic parsing,我们还可以支持一些interaction的工作。
在interaction方面特别是在graphics方面, 很多情况下我们关注一些应用问题,比如做image manipulation,图像编辑。对于这样的问题,graphics领域的大公司比如photoshop、迪士尼会更加关注。对于mage level detection(图像层面的物体检测)问题,人与机器之间存在一定的鸿沟,图像在计算机中是以像素为单位存储的,而人是从物体、场景层次等关系来理解的。基于这种机理,我们只能选择一些像素来进行处理,一方面这些像素选择时候可能会出现错误,另一方面这种方式不符合人的直观理解,人脑是从high-level的角度来思考。我们试图借助计算机视觉的一些工具对图像的内容进行理解,使得图像编辑更加符合人的直观感受。
这是在SIGGRAPH2010年的一个工作,对于一张图像,通过简单交互找到图像中的不同物体,同时通过相似对象的分析把物体的遮挡部分补全,并分析图像中物体层次的关系,这里不同于视觉中的图像深度,我们关心的只是物体大小位置等相对关系。即使有这些简单的关系,我们也可以做图像编辑的简单应用。
class="video_iframe" frameborder="0" allowfullscreen="" scrolling="no" data-vidtype="-1" data-ratio="1.3529411764705883" data-w="368" data-src="http://v.qq.com/iframe/player.html?vid=o0527v4x3au&width=670&height=502.5&auto=0" style="display: block; width: 670px !important; height: 502.5px !important;" width="670" height="502.5" data-vh="502.5" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=o0527v4x3au&width=670&height=502.5&auto=0">  
class="video_iframe" frameborder="0" allowfullscreen="" scrolling="no" data-vidtype="-1" data-ratio="1.7647058823529411" data-w="480" data-src="http://v.qq.com/iframe/player.html?vid=m0527ctewgy&width=670&height=376.875&auto=0" style="display: block; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=m0527ctewgy&width=670&height=376.875&auto=0">  
另外一个工作是我们把interaction(交互)扩展到三维空间,通过输入的RGB和depth(深度)图像重构出三维场景,在重构的过程中也可以做一些用户的交互。
Graphics/Vision Applications
下面介绍一下我们light weighted semantic parsing的工作在图形学和视觉领域的应用,首先是在图像编辑中的应用。
其中一个将语义解析的结果用于图形学应用的事例是,通过对图像的理解做一些交互任务。
其中一个是基于语音的交互。通过一些移动设备拍摄照片,这些照片其实只是二维矩阵,须对其进行处理才能更好地利用图像,我们试图采用交互的方式提高这类方法的鲁棒性,但是这些设备没有外接鼠标键盘,传统的交互方式在此并不能被很好地用起来,因此我们试图寻找方法更好地利用这些图像信息。
比如一个非常简单的图像编辑的操作,用户语音指令为“把图像中间靠下方的木桌子变得低一点”。这个任务离不开对图像里面每一个像素语义的理解,把用户指令中的动词自动转化为图像编辑的一些操作,名词和形容词对应物体检测中的属性分析,通过物体检测和属性分析,来实现并服务于图像编辑应用。这个问题是image caption(从图像生成语言)的反问题。
另外给大家介绍把light weighted semantic parsing的结果用于图像合成(synthesis)的工作。
这是我们之前做的一个sketch2photo图像合成工作,用户输入类似于左上角的图像(包含很多keywords),每个keyword就可以对应很多的Internet image,然后可以把物体区域自动分割出来,并通过轮廓比对获取目标区域,然后据此就可以自动生成目标图像。再加之一些图形学里的合成处理,使得生成的图像符合用户输入的轮廓信息。
除了对单个图像的编辑和合成,我们还可以对海量的web images进行分析。
在web images里面,国际上很多研究者用我们的工作开展了object discovery,图像的彩色化(把黑白图像变成彩色),图像分类及语义分割等工作。
今天主要对我们组的工作做了survey性质的介绍,上图是我们在南开的团队。这是我们组的一些低年级的同学们近来发表的学术成果。希望有更多的合作也欢迎硕士生的加入!
文中引用文章的下载链接为:
http://pan.baidu.com/s/1gfALAIR
文中提到的语义分割工作详见:
本文主编袁基睿,诚挚感谢志愿者杨茹茵对本文进行了细致的整理工作
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
程明明,南开大学副教授,博导,国家“万人计划”青年拔尖人才、中科协青年人才托举工程、南开大学百名青年学科带头人计划入选者。2012年博士毕业于清华大学,之后在英国牛津从事计算机视觉研究,并于2014年加入南开大学。其主要研究方向包括:计算机图形学、计算机视觉、图像处理等。已在IEEE PAMI等CCF-A类国际会议及期刊发表论文20余篇。相关研究成果受到国内外同行的广泛认可,论文他引5000余次,最高单篇他引1700余次。其研究工作曾被英国《BBC》,《每日电讯报》,德国《明镜周刊》,美国《赫芬顿邮报》等权威国际媒体撰文报道。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。
揭秘CVPR2017 WebVision图片分类竞赛冠军背后的技术
曹汛:计算摄像学研究 | VALSE2017之十六
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)