编者按:语义分割是AI领域的一个重要分支,被广泛应用于自动驾驶领域。近年来,深度学习为该领域带来了飞跃式的进展,然而这一进步依赖于大量全监督的标注数据。在语义分割领域,这意味着像素级别的标注。因此,如何利用弱监督的标注数据来学习语义分割成为了一大挑战。本文中,来自新加坡国立大学的魏云超博士,将为大家介绍弱监督学习在语义分割方面的应用。文末,大讲堂特别提供文中提到所有文章的下载链接。
这次报告的主题是“弱监督学习在语义分割方面的应用”。
我们所关注的弱监督问题是指为实现某个计算机视觉任务,采用了比该任务更弱的一种人工标注作为监督信息。一般来讲,这种弱监督的标注比原始的标注更容易获取。例如,对于目标检测任务,image-level(图像层面)的标签相比物体的bounding box是一种弱监督的标注;对于语义分割任务,image-level的标签和物体的bounding box相比pixel-level(像素层面)的标签则是一种弱监督的标注。
据统计,从2013年至今,“weak”作为关键词在计算机视觉的三大顶会上(ICCV、ECCV、CVPR)发表的论文数量逐渐增加,“弱监督”也受到了越来越多的关注。
为什么需要弱监督学习呢?首先,目前主流的基于深度卷积神经网络的方法都依赖于大量的标注数据才能得到较好的模型。其次,无论从人力还是经济上来讲完成某些视觉任务(如物体检测和语义分割)的标注成本都很高。
本次报告主要介绍如何利用弱监督信息来解决像素级的语义分割问题。上图为现在大家常用的一种全监督的方法,即利用图像和其对应的像素级标注信息训练一个全卷积神经网络。该网络可以对测试图片的每个像素进行分类,从而得到语义分割的结果。
这里所讲的“弱监督学习”是指我们仅利用image-level的标注信息,通过弱监督方式学出一个模型,该模型可以预测出图像的语义分割结果。
这种弱监督学习的关键问题是如何去构建image-level的标签语义和像素点的关联,推断出图像所对应的segmentation mask,从而利用全卷积神经网络去学习分割模型。
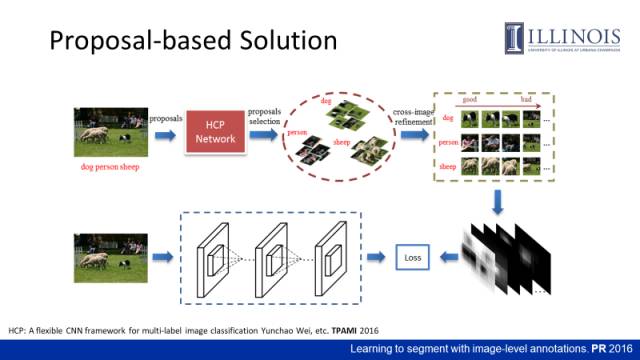
我们在2016年提出了一个proposal-based solution(基于候选区域的方法),该方法利用proposal构建一个object localization map(目标定位图)作为语义分割网络训练的监督信息。
具体方式:先提取proposals,然后通过一个HCP(Hypothesed -CNN-Pooling)网络(后文将详细介绍),判断出proposal的类别信息,筛选出具有高置信度的proposal。进而利用multi-instance learning的思想对这些proposal做re-ranking。我们把图片每一个proposal的特征和其他图片包含这个类别的proposal的特征做距离度量,获取最短距离,然后做累加,统计出哪些proposal与其他标有该类别的图片较近。我们利用排序后的proposal对图片的像素进行投票,从而获取了包含物体位置信息的localization map。最后利用该localization map作为监督信息来训练一个语义分割网络。
上图(左)是刚才提到的HCP(Hypotheses-CNN-Pooling)网络,这是我们2016年发表在PAMI上一个用于多标签图像分类的工作。通过proposal把image-level的标签作为标注信息来训练网络,使网络能够区分proposal的类别,当时获得了最好的分类性能。
上图(右)是利用proposal生成localization map的具体过程。比如大部分proposal的定位结果显示某区域是狗,这个区域就会亮起来。
localization map是一种soft的监督信息,即这里的每个像素可以以某个概率属于某个类别,例如一个像素可以以0.9的概率属于狗,以0.1的概率属于背景,具体采用的multi-label cross-entropy loss(多标签交叉熵损失函数)将在后面介绍。
但是proposal-based方法存在很大的缺点。首先,产生proposal的过程本身就很难,从proposal中提取特征又非常耗时。另外,通过累加的方式做定位可能会引入大量的false positive(如背景像素),因此得到的localization map并不是很准。因此当时的性能并不是很好,在Pascal VOC上的语义分割性能在43%(mIoU)左右。
这是我们另一个工作,通过salience map(显著图)来解决弱监督的语义分割问题。这里的motivation是从网络上获取的图片大致可以分为两种情况,一种是simple images,背景干净,只含有单个类别的目标;另一种是complex images,背景嘈杂并含有多类目标。
对于简单图片,我们可以通过显著图预测出其最显著的区域。在显著图中,像素的值越高区域越亮,就越可能是大家关注的物体,同时在已知其图像标签的情况下,我们可以建立起像素和图像标签的关联。
我们提出了一个STC(simple to complex)的方法,该方法本质上是对同一个结构的网络利用不同的监督信息训练了三次。
利用简单图片的显著图作为监督信息。由于简单图片往往只包含了一类物体,我们基于显著图可以获取每一个像素有多大的概率属于前景物体或者背景。我们利用显著图作为监督信息并采用multi-label cross-entropy loss训练出一个initial DCNN(I-DCNN),使得该网络具备一定语义分割能力。
我们利用I-DCNN对训练样本做预测,同时又根据image-level label剔除一些噪声,由此可得到针对简单图片的segmentation mask,进而基于预测出来的segmentation mask,按照全监督的卷积神经网络通用的损失函数去训练一个Enhanced DCNN(E-DCNN),进一步提升网络的语义分割能力。
引入更多的复杂图片,结合E-DCNN和其image-level label,预测segmentation mask,进而用它们作为监督信息重新训练一个更好的Powerful DCNN(P-DCNN)。
总结起来,这个网络的语义分割能力会通过这三步的训练方式一步步提升。
在该工作中,我们构建了一个Flickr-Clean数据集,我们发现用一个关键词在Flickr上做检索,排在前面的图片背景都较干净,我们选取了这些样本作为简单图片。上图给出了Flickr-Clean中的一些图片及其对应的显著图。
如图左上角表格,我们用Pascal VOC对三个深度卷积神经网络的分割能力做了测评,mIoU值代表了分割性能。只用I-DCNN,mIoU值达到44.1%,通过E-DCNN后,mIoU值达46.8%,当再通过P-DCNN后,我们的性能进一步增强可以达到49.8%。右图是经过各阶段卷积神经网络的预测结果的对比图,可以看出分割的结果也是越来越好。这篇工作在2015年投稿,当时比其他方法性能高出了10个点。
这是在校验数据集上的可视化结果,可以看出我们预测的segmentation mask和groundtruth在某些测试样本上还是非常接近的。这个工作的弊端主要是必须依赖大量的简单图片做训练。那么能不能直接由复杂图片训练出高性能的弱监督的模型呢?
Object Region Mining with AE
这是2016年两个做object localization的工作,都是利用训练好的分类网络,通过top-down方式估计出每个类别在图像上的相应区域,从而可以定位出与类别相关区域,具体方法大家请参考相应文章。
然而我们观察到,分类网络通常仅依赖于物体的某些判别区域。比如,狗的头部通常具有较强的判别力,可以使网络识别出该图片中包含狗,从而忽略狗的其他区域。但对于弱监督学习的语义分割任务而言,我们需要比较稠密和完整的localization map去训练更好的模型。而仅仅依赖于分类网络直接生成的localization map很难训练出有效模型。
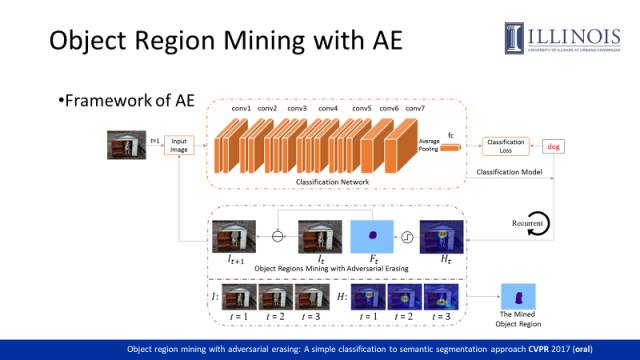
这是我们在CVPR17上的一篇工作,Object Region Mining with AE(Adversarial erasing),通过Adversarial erasing的方式去挖掘出更多的object related region。
我们先将上图包含狗的图片输入分类网络,可以通过训练得到对于狗而言最具判别力的区域,如狗的头部。接下来我们将狗的头部从图片中擦除掉(擦除指把这部分的像素值在网络中设置为0),并将擦除后的图片输入分类网络进行再训练。网络会寻找其它证据来使得图像可以被正确分类,进而找到狗的胸部。重复此操作狗的脚部区域也可以被发现。最后可以通过融合擦除掉的区域获取物体的整个区域。右图给出了不同擦除阶段所获取的物体的不同部位,以及最后通过融合得到的整个物体的区域。
该方法采用了VGG16网络作为backbone。首先训练一个分类网络,并利用CAM方法获取localization map。进而通过一个阈值获取判别区域并将其对应的像素从训练图片中擦除后重新输入网络进行训练(每次训练持续5个epochs)。
这里我们罗列出了更多的样本在不同阶段的localization map,最后一行是我们融合后的擦除区域,这些区域实际就是挖掘出来的object region。
我们利用通过显著性检测技术生成的显著图来获取图像的背景信息,并结合对抗擦除获得物体区域生成用于训练语义分割网络的segmentation mask(其中蓝色区域表示未被指派语义标签的像素,这些像素点不参与训练)。由于生成的segmentation mask包含了一些噪声区域和未被标注的区域,为了更加有效地训练,我们提出了一种PSL(prohibitive segmentation learning)方法训练语义分割网络。PSL引入了一个多标签分类的分支用于在线预测图像包含各个类别的概率值,这些概率被用来调整语义分割分支中每个像素属于各个类别的概率,并在线生成额外的segmentation mask作为监督信息。由于图像级的多标签分类往往具有较高的准确性,PSL方法可以利用分类信息来抑制分割图中的true negative区域。随着训练的进行,网络的语义分割能力也会越来越强,继而在线生成的segmentation mask的质量也会提升,从而提供更加准确的监督信息。
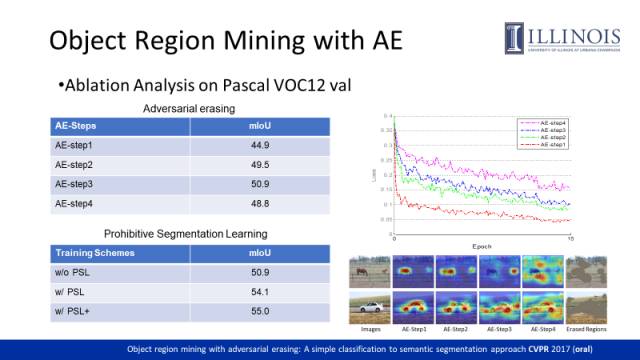
对于AE,何时停止擦除操作是一个关键的问题。这里我们通过观察分类网络上loss值的变化做决策。最下面的红色线是直接用原图做训练得到的loss曲线,可以看出loss可以降到非常低。在不断的擦除过程中,loss值也在逐渐上升,说明网络已经逐渐失去了判别训练样本类别的能力,如最上一条曲线所示,loss值收敛在一个较大的值。此时我们认为图像中的大部分物体区域已经被擦除,进一步擦除会引入更多的背景。
如左图表格(上)所示,第四步擦除降低了mIoU,因此我们只融合了前三次擦除的结果作为物体的区域。左图表格(下)是对PSL的验证试验。没有PSL参与训练的性能为50.9,通过PSL性能可以提升到54.1。PSL+是指做了一步迭代操作的结果。类似STC的做法,PSL+通过训练好的分割网络首先对训练样本做预测,进而通过CRF和图像标签修正了分割结果,最后利用网络预测的segmentation mask作为监督信息训练分割网络。总体来讲,PSL性能提升主要来源于两方面:训练过程中可以online地生成更准确的监督信息;classification分支提供的Image-level的分类结果可以作为一种后处理机制去修正分类结果。
这是我们的方法在Pascal VOC测试集上的测试结果,前面讲到的STC的性能为51.2,之后的ECCV2016的方法将性能提高到了52.7,我们的AE-PSL方法达到了55.7,右图是在校验集上的一些分割结果。
未来会集中于两个方面的研究:1)同时的弱监督物体检测和语义分割,这两个任务可能会相互促进;2) 半监督的物体检测和语义分割。虽然现在的弱监督方法取得了一定的成绩,但是和全监督方法还有一定的差距。我们希望通过结合更多弱监督的标注样本和现有的少量的标注样本通过半监督的方式训练出性能更好的语义分割模型。
http://pan.baidu.com/s/1i5vO1hF
本文主编袁基睿,诚挚感谢志愿者杨茹茵对本文进行了细致的整理工作
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
魏云超,新加坡国立大学电子与计算机工程系博士后研究员。2016年于北京交通大学获博士学位,师从赵耀教授。他的研究领域主要集中在图像理解和深度学习,包括多模态分析,图像理解,目标检测和语义分割。他已在TPAMI,CVPR,ICCV等国际知名期刊和顶级会议发表数篇论文,并获ILSVRC-2014目标检测竞赛winner prize,以及2016年CIE优秀博士论文奖。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。
实录:余凯、颜水成、梅涛、张兆翔、山世光同台讨论 “深度学习的能与不能”
章国锋:黑暗中的前行--复杂环境下的鲁棒SfM与SLAM | VALSE2017之十五
何晖光:“深度学习类脑吗?”--- 基于视觉信息编解码的深度学习类脑机制研究 | VALSE2017之十四
山世光: 我的Face Zero之梦,写在AlphaGo Zero出世之际
孙剑:如何在公司做好计算机视觉的研究|VALSE2017之十三
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)