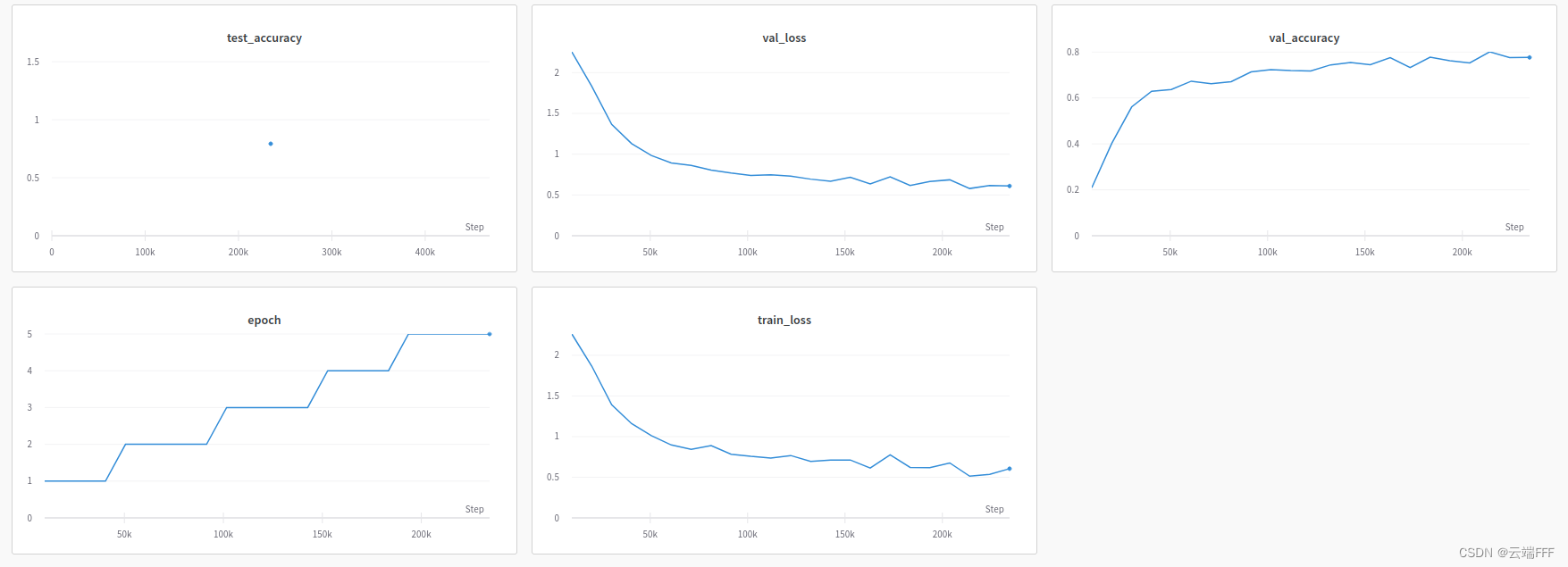
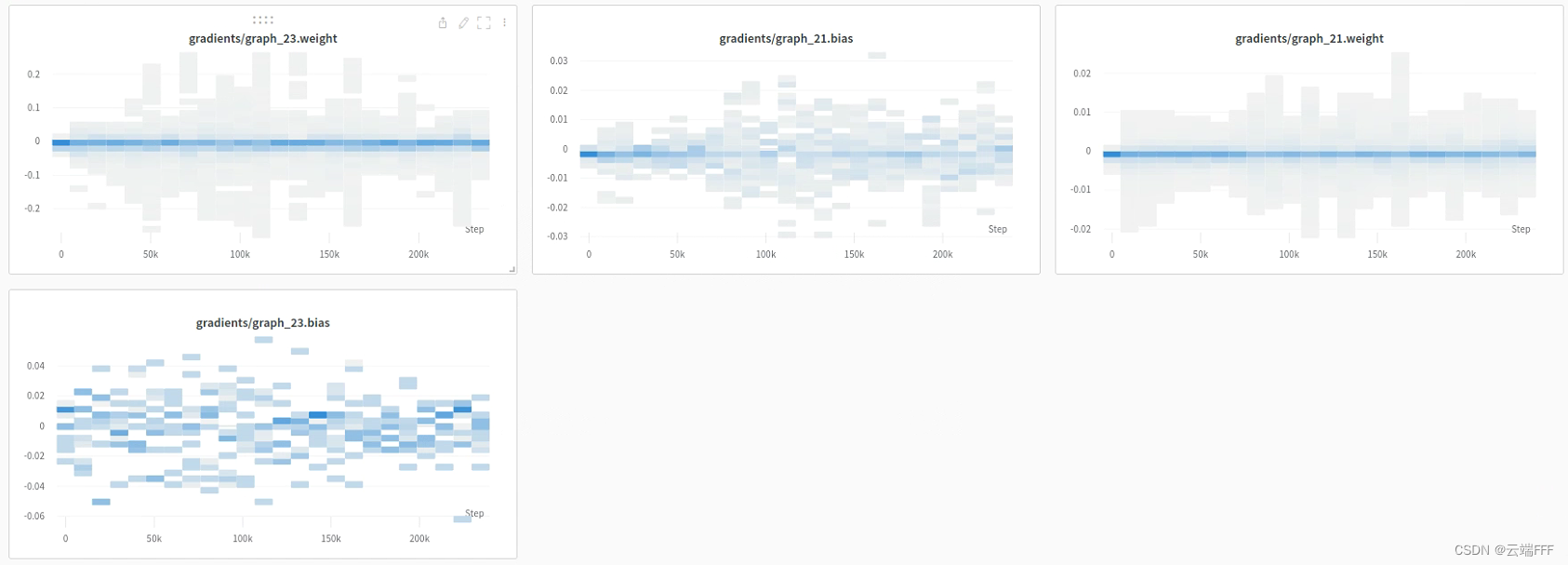
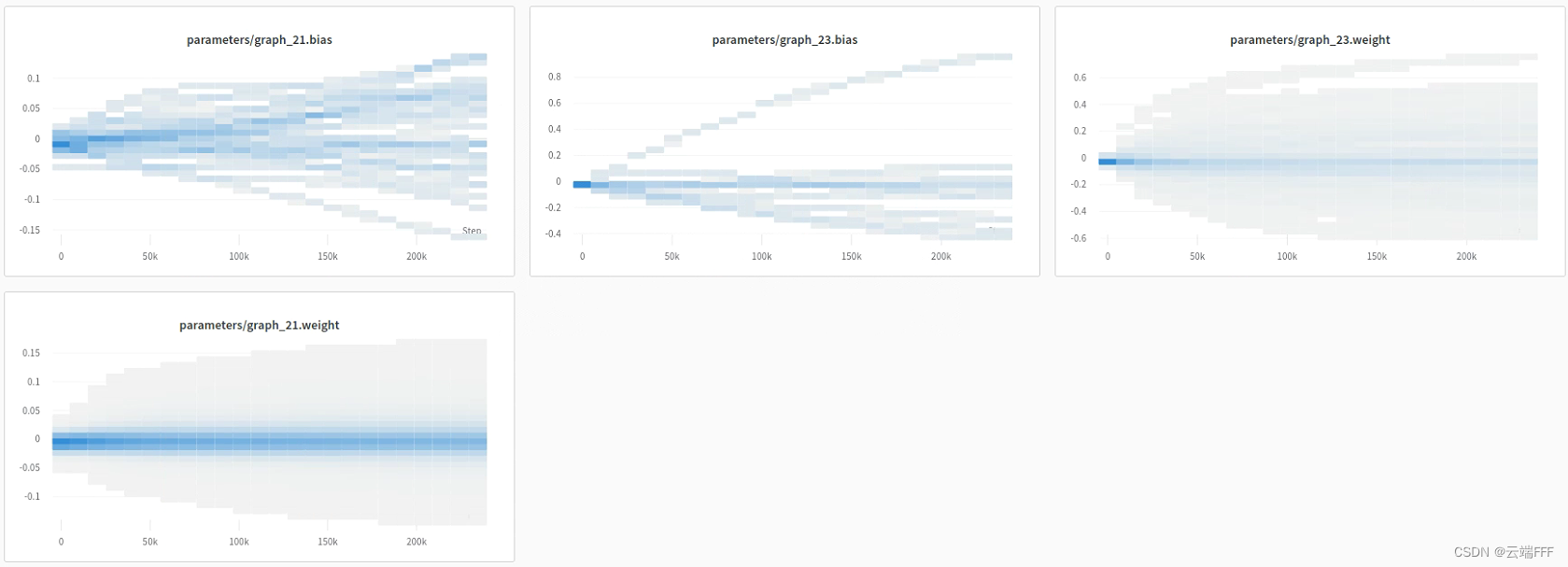
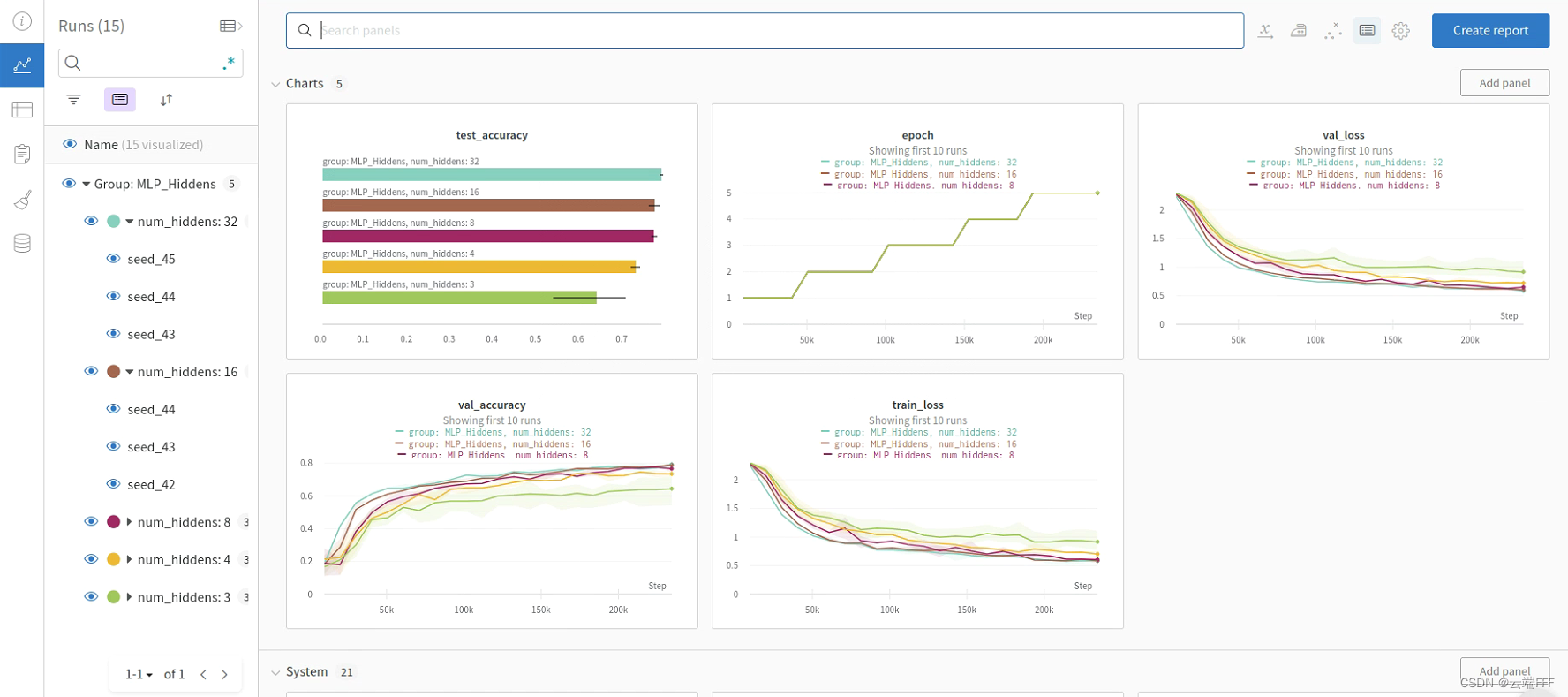
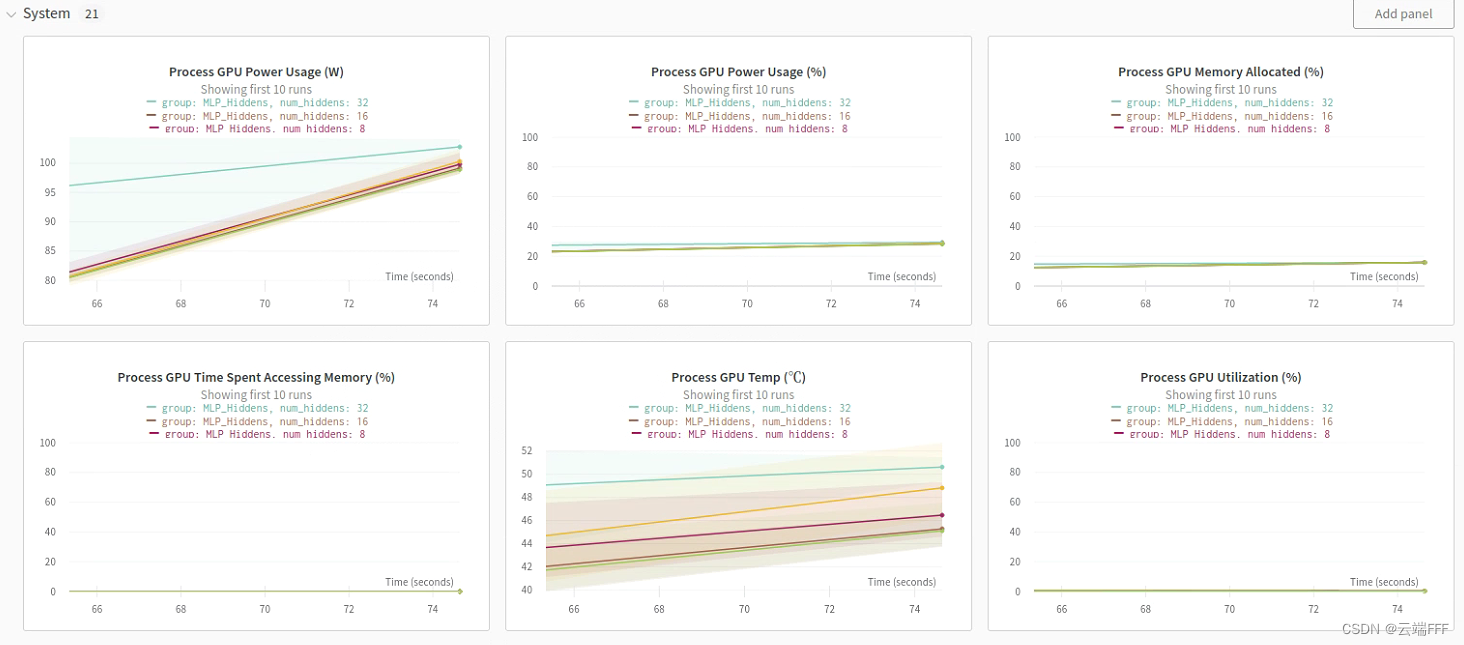
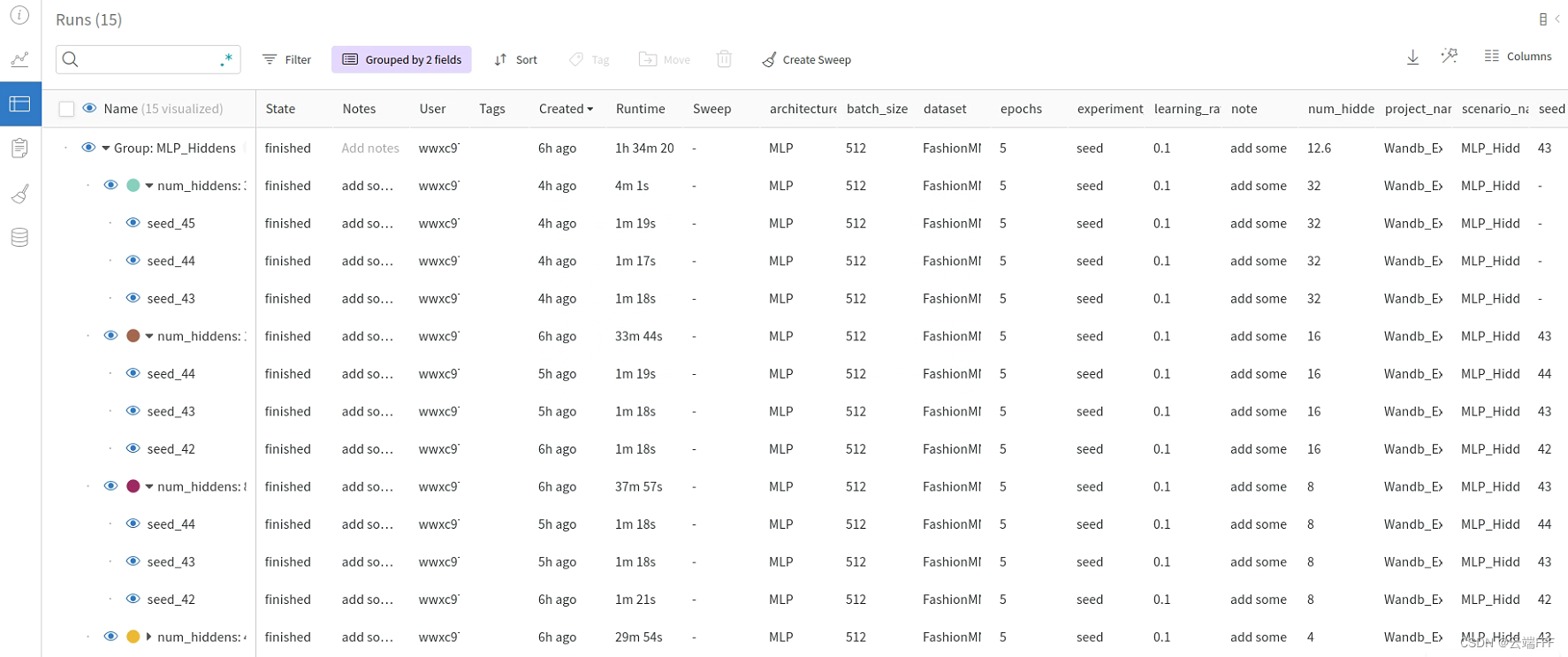
首先把上文中最后的 pytorch 代码整理为符合经典 ML pipeline 的结构,如下import torch
import torchvision
import torchvision.transforms as transforms
from torch import nn
from torch.nn import init
import random
import numpy as np
from tqdm import tqdm
import argparse
from pathlib import Path
import os
def model_pipeline(hyperparameters):
'''
the overall pipeline, which is pretty typical for model-training
'''
config=hyperparameters
for seed in hyperparameters.seeds:
set_random_seed(seed)
model, train_loader, val_loader, test_loader, loss, optimizer = make(config)
print(model)
train(model, train_loader, val_loader, loss, optimizer, config)
test(model, test_loader)
def set_random_seed(random_seed):
torch.backends.cudnn.deterministic = True
random.seed(random_seed)
np.random.seed(random_seed)
torch.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed)
def make(config):
'''
make the data, model, loss and optimizer
'''
train = torchvision.datasets.FashionMNIST(root='./Datasets/FashionMNIST', train=True, transform=transforms.ToTensor(), download=True)
test = torchvision.datasets.FashionMNIST(root='./Datasets/FashionMNIST', train=False, transform=transforms.ToTensor(), download=True)
train_dataset = torch.utils.data.Subset(train, indices=range(0, int(0.8*len(train))))
val_dataset = torch.utils.data.Subset(train, indices=range(int(0.8*len(train)), len(train)))
test_dataset = torch.utils.data.Subset(test, indices=range(0, len(test), 1))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=len(val_dataset), shuffle=True, pin_memory=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4)
model = MLP(784, 10, config.num_hiddens).to(device)
for params in model.parameters():
init.normal_(params, mean=0, std=0.01)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
return model, train_loader, val_loader, test_loader, loss, optimizer
class FlattenLayer(nn.Module):
'''
这个自定义 Module 将二维的图像输入拉平成一维向量
'''
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x):
return x.view(x.shape[0], -1)
def MLP(num_inputs, num_outputs, num_hiddens):
model = nn.Sequential(
FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
return model
def train(model, train_loader, val_loader, loss, optimizer, config):
total_batches = len(train_loader) * config.epochs
example_cnt = 0
batch_cnt = 0
for epoch in range(config.epochs):
with tqdm(total=len(train_loader), desc=f'epoch {epoch+1}') as pbar:
for _, (images, labels) in enumerate(train_loader):
train_loss = train_batch(images, labels, model, optimizer, loss)
example_cnt += len(images)
batch_cnt += 1
if (batch_cnt + 1) % 20 == 0:
val_accuracy, val_loss = validation(model, val_loader, loss)
pbar.set_postfix({
'val_acc':
'%.3f' % val_accuracy,
'val_loss':
'%.3f' % val_loss,
})
pbar.update(1)
def train_batch(images, labels, model, optimizer, loss):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
return train_loss
def test(model, test_loader):
model.eval()
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_accuracy = correct/total
print(f"Accuracy of the model on the {total} test images: {test_accuracy:%}")
model.train()
return test_accuracy
def validation(model, val_loader, loss):
model.eval()
with torch.no_grad():
correct, total = 0, 0
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_accuracy = correct/total
val_loss = loss(outputs, labels)
model.train()
return val_accuracy, val_loss
if __name__ == '__main__':
random_seeds = (43,44,45)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
parser = argparse.ArgumentParser()
parser.add_argument('--seeds', type=int, default=random_seeds)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--batch_size', type=int, default=512)
parser.add_argument('--learning_rate', type=float, default=0.1)
parser.add_argument('--num_hiddens', type=int, default=32)
args = parser.parse_args()
config = args
model = model_pipeline(config)
接下来按 2.1 节说明增加 wandb 方法,完整代码如下,请读者自行对比import torch
import torchvision
import torchvision.transforms as transforms
from torch import nn
from torch.nn import init
import random
import numpy as np
import wandb
from tqdm import tqdm
import argparse
from pathlib import Path
import os
def model_pipeline(hyperparameters):
'''
the overall pipeline, which is pretty typical for model-training
'''
run_dir = Path(f"{os.getcwd()}/wandb_local") / hyperparameters.project_name / hyperparameters.experiment_name
if not run_dir.exists():
os.makedirs(str(run_dir))
for seed in hyperparameters.seeds:
set_random_seed(seed)
with wandb.init(config=vars(hyperparameters),
project=hyperparameters.project_name,
group=hyperparameters.scenario_name,
name=hyperparameters.experiment_name+"_"+str(seed),
notes=hyperparameters.note,
dir=run_dir):
config = wandb.config
model, train_loader, val_loader, test_loader, loss, optimizer = make(config)
print(model)
train(model, train_loader, val_loader, loss, optimizer, config)
test(model, test_loader)
torch.onnx.export(model, torch.randn(config.batch_size, 1, 28, 28).to(device), "model.onnx")
wandb.save("model.onnx")
wandb.finish()
def set_random_seed(random_seed):
torch.backends.cudnn.deterministic = True
random.seed(random_seed)
np.random.seed(random_seed)
torch.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed)
def make(config):
'''
make the data, model, loss and optimizer
'''
train = torchvision.datasets.FashionMNIST(root='./Datasets', train=True, transform=transforms.ToTensor(), download=True)
test = torchvision.datasets.FashionMNIST(root='./Datasets', train=False, transform=transforms.ToTensor(), download=True)
train_dataset = torch.utils.data.Subset(train, indices=range(0, int(0.8*len(train))))
val_dataset = torch.utils.data.Subset(train, indices=range(int(0.8*len(train)), len(train)))
test_dataset = torch.utils.data.Subset(test, indices=range(0, len(test), 1))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=len(val_dataset), shuffle=True, pin_memory=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=config.batch_size, shuffle=True, pin_memory=True, num_workers=4)
model = MLP(784, 10, config.num_hiddens).to(device)
for params in model.parameters():
init.normal_(params, mean=0, std=0.01)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
return model, train_loader, val_loader, test_loader, loss, optimizer
class FlattenLayer(nn.Module):
'''
这个自定义 Module 将二维的图像输入拉平成一维向量
'''
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x):
return x.view(x.shape[0], -1)
def MLP(num_inputs, num_outputs, num_hiddens):
model = nn.Sequential(
FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
return model
def train(model, train_loader, val_loader, loss, optimizer, config):
wandb.watch(model, loss, log="all", log_freq=10)
total_batches = len(train_loader) * config.epochs
example_cnt = 0
batch_cnt = 0
for epoch in range(config.epochs):
with tqdm(total=len(train_loader), desc=f'epoch {epoch+1}') as pbar:
for _, (images, labels) in enumerate(train_loader):
train_loss = train_batch(images, labels, model, optimizer, loss)
example_cnt += len(images)
batch_cnt += 1
if (batch_cnt + 1) % 20 == 0:
val_accuracy, val_loss = validation(model, val_loader, loss)
pbar.set_postfix({
'val_acc':
'%.3f' % val_accuracy,
'val_loss':
'%.3f' % val_loss,
})
wandb.log({"epoch": epoch + 1,
"train_loss": train_loss,
'val_accuracy': val_accuracy,
'val_loss': val_loss},
step=example_cnt)
pbar.update(1)
def train_batch(images, labels, model, optimizer, loss):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
train_loss = loss(outputs, labels)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
return train_loss
def test(model, test_loader):
model.eval()
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_accuracy = correct/total
wandb.log({'test_accuracy': test_accuracy})
print(f"Accuracy of the model on the {total} test images: {test_accuracy:%}")
model.train()
return test_accuracy
def validation(model, val_loader, loss):
model.eval()
with torch.no_grad():
correct, total = 0, 0
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_accuracy = correct/total
val_loss = loss(outputs, labels)
model.train()
return val_accuracy, val_loss
if __name__ == '__main__':
random_seeds = (43,44,45)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
parser = argparse.ArgumentParser()
parser.add_argument('--seeds', type=int, default=random_seeds)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--batch_size', type=int, default=512)
parser.add_argument('--learning_rate', type=float, default=0.1)
parser.add_argument('--num_hiddens', type=int, default=32)
parser.add_argument('--dataset', type=str, default='FashionMNIST')
parser.add_argument('--architecture', type=str, default='MLP')
parser.add_argument('--note', type=str, default='add some note for the run here')
parser.add_argument('--project_name', type=str, default='Wandb_ExpTracking')
parser.add_argument('--scenario_name', type=str, default='MLP_Hiddens')
parser.add_argument('--experiment_name', type=str, default='seed')
args = parser.parse_args()
config = args
model = model_pipeline(config)