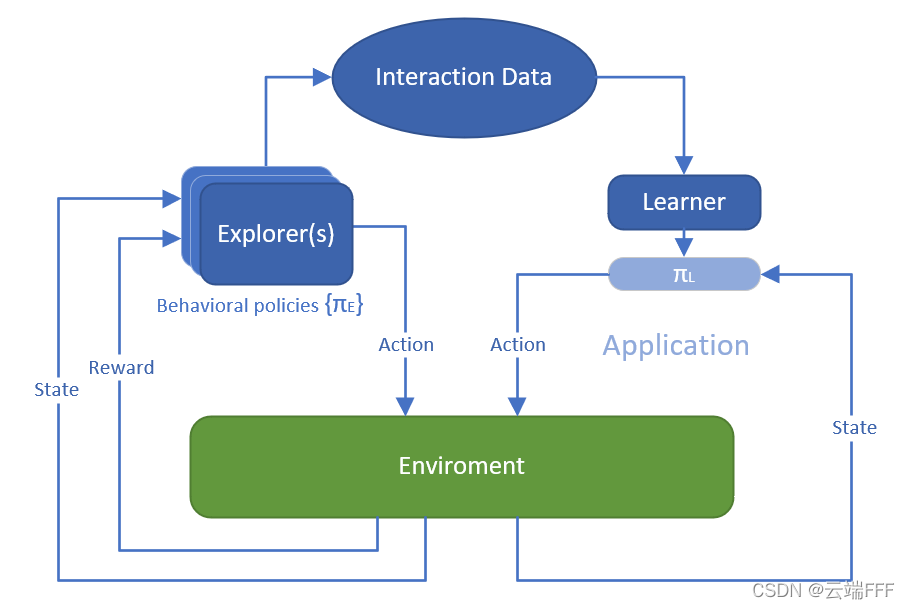
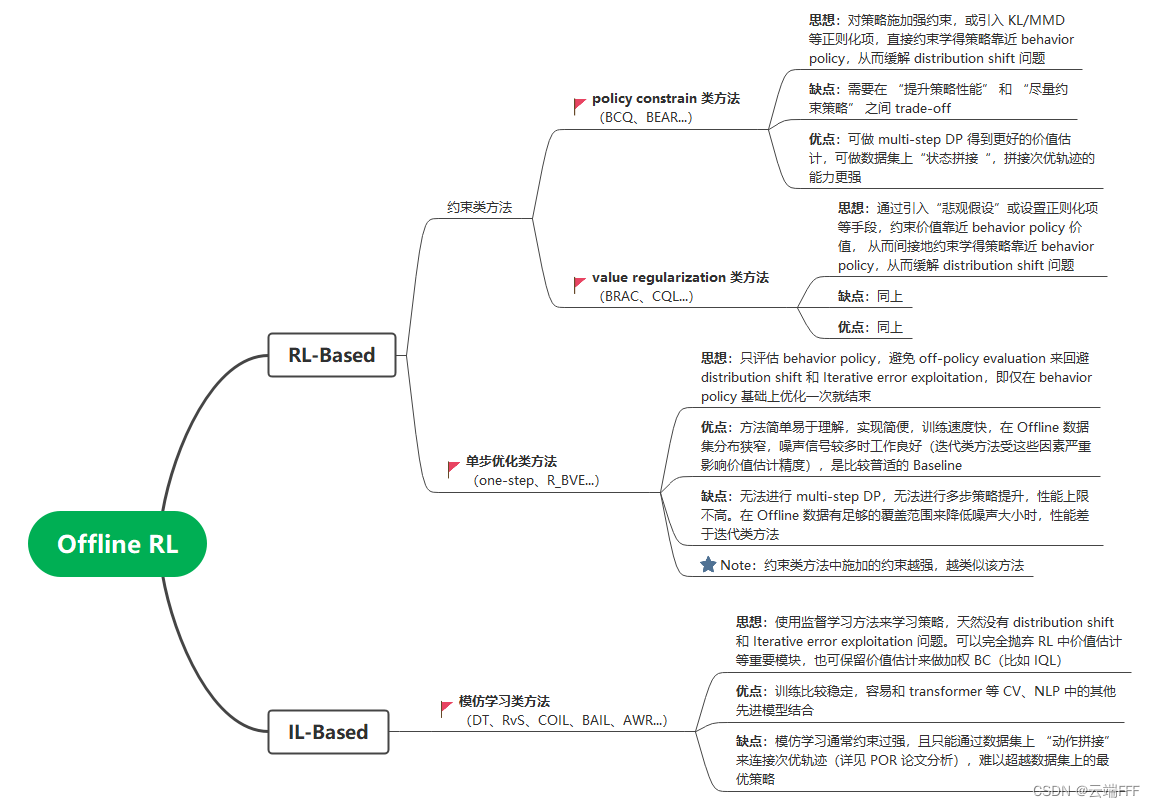
在 Offline 数据集上进行 policy evaluation 时,Bellman 迭代中涉及的 OOD 的
a
′
a'
a′ 会导致 distribution shift,过去 policy constrain 和 value constraint 类方法都无法完全回避此问题,one-step 类方法虽然可以回避,但失去了 multi-step DP 能力。本文通过 expectile regression 进行隐式的策略评估,在完全避免 OOD
a
′
a'
a′ 访问以避免 distribution shift 的同时,仍能执行 multi-step DP,从而学到更好的
Q
∗
Q^{*}
Q∗ 估计,最后用 AWR 方法(一种优势加权模仿学习)从
Q
∗
Q^*
Q∗ 估计中提取策略
本文提出的 IQL 本质上属于 IL-Bsaed 类方法,它学习价值估计只是为了进行优势加权 BC
2.2 方法细节
目标是只在数据集上所含的
(
s
,
a
)
(s,a)
(s,a) 上进行应用 Bellman optimal operator,从而回避 OOD 的
a
′
a'
a′ (文章所谓的 “SARSA-like”)
L
(
θ
)
=
E
(
s
,
a
,
s
′
)
∼
D
[
(
r
(
s
,
a
)
+
γ
max
a
′
∈
A
s.t.
π
β
(
a
′
∣
s
′
)
>
0
Q
θ
^
(
s
′
,
a
′
)
−
Q
θ
(
s
,
a
)
)
2
]
(1)
L(\theta)=\mathbb{E}_{\left(s, a, s^{\prime}\right) \sim \mathcal{D}}\left[\left(r(s, a)+\gamma \max _{\substack{a^{\prime} \in \mathcal{A} \\ \text { s.t. } \pi_{\beta}\left(a^{\prime} \mid s^{\prime}\right)>0}} Q_{\hat{\theta}}\left(s^{\prime}, a^{\prime}\right)-Q_{\theta}(s, a)\right)^{2}\right] \tag{1}
L(θ)=E(s,a,s′)∼Dr(s,a)+γa′∈A s.t. πβ(a′∣s′)>0maxQθ^(s′,a′)−Qθ(s,a)2(1) 其中
Q
θ
^
Q_{\hat{\theta}}
Qθ^ 是 target 网络,
β
\beta
β 是 behavior policy
作者如下使用 expectile regression(期望回归) 方式实现这个操作
L
(
θ
)
=
E
(
s
,
a
,
s
′
,
a
′
)
∼
D
[
L
2
τ
(
r
(
s
,
a
)
+
γ
Q
θ
^
(
s
′
,
a
′
)
−
Q
θ
(
s
,
a
)
)
]
(2)
L(\theta)=\mathbb{E}_{\left(s, a, s^{\prime}, a^{\prime}\right) \sim \mathcal{D}}\left[L_{2}^{\tau}\left(r(s, a)+\gamma Q_{\hat{\theta}}\left(s^{\prime}, a^{\prime}\right)-Q_{\theta}(s, a)\right)\right] \tag{2}
L(θ)=E(s,a,s′,a′)∼D[L2τ(r(s,a)+γQθ^(s′,a′)−Qθ(s,a))](2) 其中
L
2
τ
(
u
)
=
∣
τ
−
1
(
u
<
0
)
∣
u
2
L_{2}^{\tau}(u)=|\tau-\mathbb{1}(u<0)| u^{2}
L2τ(u)=∣τ−1(u<0)∣u2 是一个非对称 L2 损失,如下所示 当
τ
=
0.5
\tau=0.5
τ=0.5 时
L
2
0.5
L_{2}^{0.5}
L20.5 退化为 MSE;
τ
\tau
τ 越接近 1,模型就越倾向拟合那些 TD error 更大的 transition,从而使
Q
Q
Q 估计靠近数据集上的上界;当
τ
→
1
\tau\to 1
τ→1 时可认为得到了
Q
∗
Q^*
Q∗
直接使用 (2) 的问题在于引入了环境随机性
s
′
∼
p
(
⋅
∣
s
,
a
)
s'\sim p(·|s,a)
s′∼p(⋅∣s,a),一个大的 TD target 可能只是来自碰巧转入的 “好状态”,即使这个概率很小,也会被 expectile regression 找出来,导致
Q
Q
Q 价值高估。为此作者又学习了一个独立的
V
V
V 价值
L
V
(
ψ
)
=
E
(
s
,
a
)
∼
D
[
L
2
τ
(
Q
θ
^
(
s
,
a
)
−
V
ψ
(
s
)
)
]
(3)
L_{V}(\psi)=\mathbb{E}_{(s, a) \sim \mathcal{D}}\left[L_{2}^{\tau}\left(Q_{\hat{\theta}}(s, a)-V_{\psi}(s)\right)\right] \tag{3}
LV(ψ)=E(s,a)∼D[L2τ(Qθ^(s,a)−Vψ(s))](3) 这里
V
ψ
(
s
)
V_\psi(s)
Vψ(s) 会近似
max
Q
θ
^
(
s
,
a
)
\max Q_{\hat{\theta}}(s,a)
maxQθ^(s,a),然后使用如下 MSE loss 来消除
s
′
s'
s′ 的随机性
L
Q
(
θ
)
=
E
(
s
,
a
,
s
′
)
∼
D
[
(
r
(
s
,
a
)
+
γ
V
ψ
(
s
′
)
−
Q
θ
(
s
,
a
)
)
2
]
(4)
L_{Q}(\theta)=\mathbb{E}_{\left(s, a, s^{\prime}\right) \sim \mathcal{D}}\left[\left(r(s, a)+\gamma V_{\psi}\left(s^{\prime}\right)-Q_{\theta}(s, a)\right)^{2}\right] \tag{4}
LQ(θ)=E(s,a,s′)∼D[(r(s,a)+γVψ(s′)−Qθ(s,a))2](4) 总的来看,就是使用 (3) (4) 实现 (2),达成 (1) 的思想,这里 (3) (4) 可以多步迭代计算实现 multi-step DP,且整个过程不需要访问
a
’
a’
a’
价值收敛得到
Q
∗
Q^*
Q∗ 后,直接用 AWR 方法,通过最大化下式来提取策略
L
π
(
ϕ
)
=
E
(
s
,
a
)
∼
D
[
exp
(
β
(
Q
θ
^
(
s
,
a
)
−
V
ψ
(
s
)
)
)
log
π
ϕ
(
a
∣
s
)
]
L_{\pi}(\phi)=\mathbb{E}_{(s, a) \sim \mathcal{D}}\left[\exp \left(\beta\left(Q_{\hat{\theta}}(s, a)-V_{\psi}(s)\right)\right) \log \pi_{\phi}(a \mid s)\right]
Lπ(ϕ)=E(s,a)∼D[exp(β(Qθ^(s,a)−Vψ(s)))logπϕ(a∣s)] 其中
β
∈
[
0
,
∞
)
\beta\in[0,\infin)
β∈[0,∞) 是一个逆温度系数,取值较小时类似 BC;取值较大时会试图做加权 BC 来恢复
max
Q
θ
^
(
s
,
a
)
\max Q_{\hat{\theta}}(s,a)
maxQθ^(s,a),注意这个过程也无需访问
a
′
a'
a′