最近更新的这2篇应该是比较重的了,先做GPU篇,再做DSP篇
先友情提醒,这篇文章很重很费时,对各种软硬算的知识要求多多。
主体知识来源于UZH和ETH的研究者Balazs Nagy组,核心知识来源于近年来各校各司对并行化与工程化深入研究的科学家工程师们,其他部分来自于紫川小组同事同学们的研究与探讨。因为毕竟不是写论文,就不一一感谢了。
做一个完整的能落地能商用的VIO,其实看起来是很简单的,貌似就是调库调参侠的工作。
近期也不断地被港科的师兄弟们咨询如何具体落地(各种奇奇怪怪的创业项目),结果发现大家实在是太小看这个领域了,基于这些出发点,决定写这2个姊妹篇。
一个完美的VIO,其实是一个既要又要还要且要的东西,非常的恶心:
1.既要位姿准确(ORB-SLAM3, VINS-MONO)
2.又要能够半稠密建图(DSO, DM-VIO)
3.还要能够工程化,克服各种极端情况,ZUPT等 (PR-MONO1)
4.且要低开销(只能在高性能高算力平台上跑的东西根本没有足够商业价值-除自动驾驶,违背VINS/VIO等基础设计宗旨)
目前能满足个1的东西挺多的,其他如能满足1+2的又很难初始化(DM-VIO),各种数据集上跑得贼666的东西拿到真实环境里就是个渣,这些事情我在以前的文章里反反复复提过了。同时能满足3项的一个都没遇到过,能满足4项的是神作。
今天写写针对4的Balazs Nagy组一些核心工作的解读:
VIO能被并行化的首先考量前端:
主要针对前端中2部分进行:检测与跟踪
这2者都很适合并行化
其中非极大值抑制和随后的特征点选取对降低整个系统的延迟产生了主要贡献
在这里补一个非极大值抑制算法的简要说明:
NMS算法就是寻找局部最大值的算法,在AI中应用较多,如从一个概率最大特征/矩形框/BOX出发,从匹配中设定一个阈值,对局部进行最大搜索,找到邻域中的最大值,并滤掉其他多余的部分。
GPU上的非极大值抑制问题(NMS算法)是一种选择局部响应最大值的方法,以施加空间特征分布与提取特征的解决方案。
(但是要注意目前只针对Nividia和CUDA平台做的)
3种主流并行化思路与方法
(1)CPU+DSP
(2)CPU+FPGA(开发时间长周期)
(3)CPU+GPU(基于GPU本质为高并行及处理图像而生,本文主路径)
Balazs Nagy等在CPU和GPU之间建立了可行的工作共享,以降低整体的工作处理时间
前端过去的一些工作总结
提取特征点:基本没有变化和进步,如Harris角点FAST等。ORB加了描述子,给SIFT和SURF提供了一个实时合理的替代方案。Etc,这块工作大家都很熟悉不赘述了。
非极大值抑制:各个摩尔邻域间候选目标(VIO中指像素/兴趣点)的本地局部最大值搜索。(这个描述应该较精确),每个像素的摩尔邻域是以它为中心,2n+1边长的区域。这一类的抑制已被广泛研究并应用在机器学习与AI中。此类算法早期的复杂度由每个兴趣点需要比较的数量决定,因为需遵循光栅扫描的顺序,这类算法需要(2n+ 1)²次比较。后续Forstner和Gulch等专家改善并开发了螺旋形比较法,使理论比较点数量未变的情况下实际比较点数量直线下降并降低了开销。大部分候选目标首先抑制在了一个3x3的像素区间中(仅有很少量的点会被遗漏),后续又有Neubeck等大佬们一路推进算法改进(所有点只比较一次),Pham又提出了另外两种算法(扫描线和四分之一块分区),将比较次数降低到2以下,对于较大的邻域(n≥5),对于较小的邻域大小(n ≤5)。所有这些方法首先尝试在较小的邻域中进行局部最大候选对象的缩减,然后只对选定的候选对象进行邻域验证。但是它们不能保证任何(空间)特征分布,并可能输出大量的候选特征集。
特征点跟踪:分3类,特征点匹配/基于滤波器的特征点跟踪/差动跟踪,
特征点匹配:对每一帧应用特征提取,然后进行特征匹配,这需要大量的开销。此外,特征检测器的可重复性可能会对其鲁棒性产生不利影响。
基于滤波器的特征点跟踪:通过基向量得到了特征点的位置,并遵循连续的预测和更新步骤(如卡尔曼滤波)
差动跟踪:通过像素强度和最小光度误差来做,如LK光流法,目前也是VIO中的主流方向了。由于其效率及鲁棒性,基于此类方法与GPU结合是最早出现的。Zach小组在GPU上实现了具有强度增益估计的跨分位移模型,Kim和Hwangbo组更进一步:他们提出了一个仿射光度模型耦合惯性测量单元(imu)初始化方案:位移模型遵循仿射变换,其中参数受imu连续帧之间的测量,而像素强度也可能经历一个仿射变换。
Balazs Nagy等的工作介绍了一种新的基于前人工作的非极大值抑制构建,同时也利用了底层的GPU指令原语,通过一个GPU优化的快速检测器实现来完成。他们的方法结合了特征检测和非极大抑制,保证了整个图像的均匀特征分布,其他方法需要执行一个额外的步骤。此外,结合了前端与最先进的VIO后端(这里指的自然是ICEBA)。所有的贡献都通过使用JETSON TX2嵌入式平台和一个笔记本电脑GPU上的EUROC数据集进行了验证和彻底的评估。演示了超过1000fps的吞吐量能力,用于特征检测和跟踪,200fps用于VIO状态估计。
整体方法论
并行化初探
简要介绍了计算统一设备架构的基本原理,或简称CUDA,这是一个英伟达专有的标准并行计算平台和编程模型。CUDA允许开发人员将任务从CPU中拆出,并将任务传播到GPU,即使是对非图像相关的计算。后者通常被称为通用的GPU(GPGPU)编程。
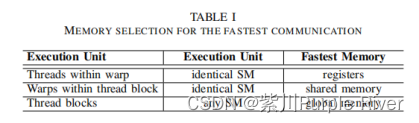
英伟达的GPU架构是围绕一个可扩展的多线程流媒体多处理器(SMS)阵列构建的。每个SM都有许多流媒体处理器(SP),它们最近也被称为CUDA核。GPU通常有1-20个SM(流媒体多处理器),每个SM有128-256个小流媒体处理核。除了处理核心之外,还有各种类型的内存可用(根据与处理核心的接近程度排序):寄存器文件、共享内存、各种缓存、芯片。
Nvidia的GPGPU执行模型引入了一个计算单元的层次结构:线程(thread)、WARP、线程块(block)和线程网格(grid)。最小的执行单位是一个线程。线程被分成翘曲WARP组:每个WARP组由32个线程组成,然后这些翘曲组被进一步分组为线程块。一个线程块保证在同一SM上执行。顶部的执行模型是线程网格,线程网格是一个线程块的数组,线程网格中的线程块是彼此独立地执行的。
在GPU上的指令执行需要empha(强调)大小的:一个WARP组中的每个线程在一个锁步骤的基础上执行相同的指令。Nvidia调用这个执行模型单指令多线程(SIMT)。if/else形成的分叉/发散在WARP中会导致序列化执行。
底层的GPU硬件偶尔会有变更,因此需要跟踪GPU之间的差异。Nividia引入了计算能力的概念,并附了一个代号来表示这些差异。随着英伟达Kepler GPU微体系结构的引入,同一WARP中的线程可以通过特定的指令从彼此的寄存器中读取。工作集中在这些WARP级别的原语,以更具体高效的通信模式,在同一WARP组的线程之间共享数据。在以前的GPU中,线程需要转向一个较慢的公共内存(通常是共享内存)来进行数据共享,这导致了大量的执行延迟。随着Kepler架构的引入,可以首先在WARP区域内执行通信,并且只在更高的执行层面上使用较慢的内存,如在线程块(block)内,以及在线程网格(grid)内。总结了在GPU上的执行块之间交换数据的可用最快内存。(这一块的能力在OpenCL中是不被支持的)
B:特征检测器概述
GPU特别适合于特征检测,这可以被认为是并行通信模式中的一种模板操作。在模板操作中,每个计算单元并行地访问一个输入元素(像素)及其近邻域。因此,图像可以有效地在可用的CUDA核之间分割,这样内存访问就会被合并,从而实现高度高效的并行化。对于特征检测,首先对输入图像进行下采样以获取图像金字塔。然后,对于每个图像分辨率,通常在每个像素上评估两个函数:一个粗角点响应函数(CCRF)和一个角点响应函数(CRF)。CCRF是一种快速评估,可以迅速排除大多数候选目标,这样CCRF是一种快速评估,可以快速排除大多数候选项,因此较慢的CRF函数只接收通过第一次验证的候选项。一旦在ROI内评估了每个像素,非极大抑制只选择局部极大值。总结了算法中特征检测器算法的通用执行方案(算法1)如下

即均匀的特征分布,在图像帧上提高了VIO管道的稳定性。为了满足这一要求,引入了二维网格单元(2D GRID CELL)的概念:将图像划分为固定宽度和高度的矩形。在每个单元格中,只有一个特征被选中——它的CRF分数在单元格中是最高的特征。该方法不仅将特征均匀地分布在图像上,而且对所提取的特征计数施加了一个上限。这如上图所示,包括各种方式的扩展。
C.用CUDA进行非极大值抑制
单元格(CELL)内的特征选择可以理解为一种缩减操作,只选择得分最大的特征。此外,邻域内的非极大值抑制也可以被认为是一种缩减操作,即一个缩减操作降低了对有限邻域内的单像素位置的角点响应(这里比较难理解,应该是最直观的解释了)。
这种方法将角点响应映射划分为一个有规律的单元格网格。在第一金字塔层的网格中,单元格使用32的整数倍的宽度,即32w,因为在Nvidia GPU硬件上,一个WARP由32个线程组成。一个CELL的1行被称为一个CELL行,它可以分裂成有32个elements的CELL行片段。小组将CELL的高度限制为2(l-1次方)h,其中l是在特征检测过程中使用的金字塔的层数。通过选择合适的网格配置l、w和h,可以确定提取的最大特征数量,同时保持空间分布。
在一个CELL行片段中,分配一个线程来处理一个像素响应,即一个WARP来处理一整个CELL行片段(32个线程来处理32个像素响应)。一个WARP可以处理多行,而一个线程块中的多个WARP可以协同处理单元格中的连续行。由于角点响应映射使用单一精度浮点格式存储,水平单元边界与L1缓存(L1-Cache)线边界完全重合,这在获取完整的单元线段时最大限度地提高内存总线利用率。
为了便于说明,在一个32x32的单元格中使用了一个1:1的WARP到单元格的映射。当WARP读出CELL的第一行时,WARP中的每条CELL行都获得了一个像素响应。作为下一个操作,整个WARP开始邻域抑制:WARP根据[14](这里指前文所引用的Forstner等的算法成果)开始螺旋旋转,每个线程验证它的响应是否在其摩尔邻域内达到最大值。当邻域验证完成后,一些线程可能已经抑制了它们的响应。但是,此时不进行写入,每个线程都将其状态(响应得分和x-y位置)存储在寄存器中。WARP继续下一行,重复前面的操作:它们读出相应的响应,开始邻域抑制,如果新响应高于前一行,则更新它们的最大响应。
WARP在CELL的所有行中继续此操作,直到处理完整个CELL。在完成后,每个线程在相应的2d位置上都有其最大分数。但是,由于这32个线程正在处理单独的列,因此最大值只有列级。因此,WARP需要执行WARP级别的缩减,以获得单元格级的最大值:它们使用WARP级下行搬迁(warp-level shuffle)将最大分数和位置降低到第一个线程(thread 0)。所应用的通信模式如下图2所示,thread 0最终将结果写入全局内存。

为了加快缩减的速度,多个(M,无特殊定义,表示多个)WARP处理一个CELL,因此,在WARP级别减少后,共享内存中的最大值减少。一旦线程块中的所有WARP都将其最大结果(分数、x-y位置)写入其指定的共享内存区域,线程块(Block)中的第一个线程将为每个单元格选择最大值,并将其写入全局内存,完成该单元格(CELL)的处理。
在金字塔特征检测过程中,只保持一个GRID。在0级(原始分辨率)上,采用上述指定的算法。在较低的金字塔水平上,实际上可以缩放CELL的大小,这样在金字塔k级上适用的CELL大小变成32*w/k,2(l-1次方)h/k。如果单元格宽度低于32,一个WARP可以处理多行:如果连续的CELL行仍然属于同一个GRID CELL,WARP可以类似地执行WARP级降低。由于较低金字塔层的分辨率是上层分辨率的一半,这样可以有效地重新计算原始网格上较低金字塔层的位置。也就是说,当在较低的金字塔水平上识别一个单元格最大值时,从较低分辨率的2d位置(x,y)可以放大到2(l次方)x ,2(l次方)y。
回顾算法1,方法将规则邻域抑制(NMS)和CELL最大选择(NMS-C)结合到一个单一的步骤中。因为首先在每个线程中并行执行候选目标抑制,然后减少剩余的候选目标抑制在一个CELL中。
D: FAST特征检测
快速特征检测器的基本思想很简单:对于原始图像中的每个像素位置(不包括最小3像素的边界),执行分段测试,其中比较半径为3的布雷森汉姆圆上的像素强度。这个圆给了每个点周围的16个像素位置(见图3)。根据中心和实际点的强度之间的比较,给这些点给出标签Lx。
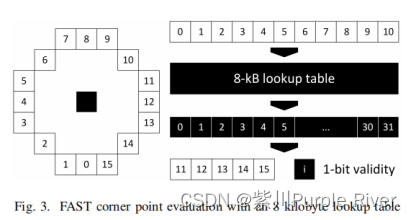
假定有一个至少n个像素的连续弧,它们被标记为更暗或更亮,中心被认为是一个角点。为了给比较增加更多的鲁棒性,需要一个阈值(ε)被应用,比较结果总结为下式。其中连续像素数(n)和阈值(ε)都是调优参数。

如何避免在FAST计算中的分叉/发散(if/else等)!!!
如果每个线程在Nvidia的单指令-多线程(SIMT)执行模型中执行了来自上图(1)的比较,那么if/else-instructions中的比较决策将执行不同的代码块。因此所有线程都在WARP中执行相同的指令,所以一些线程在if分支期间将处于不活动状态,而其他线程在else分支期间将处于不活动状态。这被称为代码分叉/发散,并显著降低了并行语言化中的吞吐量,但它可以用一种完全不同的方法来解决:一个查找表(上图3)
方法将16个比较的结果存储为一个位数组,它用作查找表的索引。所有可能的16位向量都是预先计算的:如果布雷森汉姆圆Ix上的像素强度比中心角点像素I-center强度图标更暗/更亮,则一位bx为“1”,如果像素强度相似,则为“0”。由于结果是所有2的16次方个向量的二进制文件,因此答案可以存储在2的16次方位上,即8000字节。
这些答案可以通过使用4字节整数来存储,每个整数存储32个组合(2的5次方): 11位用于获取整数的地址,5位不使用然后从32位中选择1位。如果结果位被设置,继续计算角点的分数。
此处的引用文献区分了一个角点的三种不同类型的分数:整个布雷森汉姆圆(SAD-B)的绝对差异的总和;连续弧(SAD-B)[论文引文3]的总和;最大阈值(ε),该点仍然被认为是一个角点(MT)[论文引文7]。如果分段测试失败,则拐角分数为0。
方法将每个16位通信的有效性压缩为1位,从而得到一个8000字节的查找表,其缓存利用率更高。这是由于移动到L1(和L2)缓存中的每个缓存行的复用量增加所致,因此改善了访问延迟。
E: LK光流法跟踪
方法中采用多层金字塔同步逆合成LK光流法作为特征跟踪器,LK光流算法通过对新图像的图像坐标应用warping函数进行最小化,确定了模板上的矩形块(rectangular patch)与新图像之间的光度误差。逆合成算法是一种扩展,通过允许预先计算散矩阵并在每次迭代中重用它,改善了每次迭代的计算复杂度。
同时逆合成的光流法增加了仿射光度变换的估计。然而,当Hessian成为外观估计的函数时,它不能再进行预计算。这使得这种方法比基础LK光流法更慢。因此,方法应用近似版本,其中假设外观参数没有显著变化,因此可以用它们的初始估计预先计算。
使用平移位移模型t与仿射强度变化估计λ.完整的参数集是q=[t,λ]转置=[tx,ty,α,β]转置,当tx,ty平移抵消,而α,β仿射照明参数,在warping中的结果如下式:

对于∆q=[∆t,∆λ],试图为每个特征最小化的每个特征的光度误差是:

其中,T (x)和I(x)分别代表模板图像和位置x处的当前图像强度。向量x通过一个特征的矩形邻域(N)进行迭代。可以将增量项的系数组织成向量形式为:

而最小二乘问题可以改写为:

在计算了(5)的导数并将其设为零后,使用Hession(H)找到了∆q的解:

对于这个算法,有两个关键的GPU问题需要解决:内存合并和WARP中分叉/发散的处理。这些问题是从VIO算法的角度来解决的,其中人们通常不跟踪大量的特征(只有50-200个),这些稀疏的特征也分散在整个图像中,这意味着它们分散在内存中。该算法将多个金字塔水平上每个特征点周围的矩形邻域的光度误差最小化。因此,如果WARP处理中的线程不同,内存访问将被取消合并。同时给定的一些特性轨迹不收敛,或者同一级别上的迭代次数不同,WARP中的一些线程将是空闲的。为了解决这两个问题,启动了一个完整的WARP来处理一个特性。还选择了可以通过WARP协同处理的矩形块的大小:高分辨率为16x16,低分辨率为8x8像素。它解决了WARP分叉/发散问题,因为WARP中的线程执行相同数量的迭代,并且它们迭代到相同的金字塔级别。来自WARP的内存请求也被分割为更少的内存事务,因为相邻的线程正在处理连续的像素或连续的行。
在最小化的每一次迭代中,都利用了WARP级原语,因为需要执行一个小块范围的缩减:在(6)中,需要对小块内的每个像素的四个元素向量U(x)转置*r(x,t)求和。一个线程处理小块中的多个像素,因此每个线程在任何通信之前都需要缩减存放到其寄存器中的元素(这句话不熟悉硬件的同学很难理解)。一旦整个WARP完成了一个小块,线程需要与小块的其他部分共享它们的本地结果,以计算∆q。这种缩减是使用下图4中所示的蝴蝶通信模式来执行的。
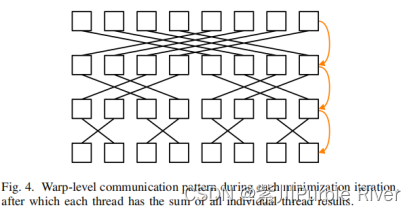
这种方法的新颖之处在于从线程到特征点的分配。这意味着只有大的特征计数才会利用大量的线程。这将对隐藏在具有较小特征计数的GPU上的延迟产生不利影响,但是这通用适配于VIO。这种方法通过协作解决特征小块来加速算法,其中每个线程的工作负载减少,而使用的通信平均速度是最快的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)