近年来图像识别突破、Waymo无人车上路、Alphago战胜人类冠军等AI的一些标志性事件让人工智能又走上了炒作的高峰。于是各种有关AI的预测铺天盖地,有说未来一片光明的,有说AI会给人类造成生存威胁的。但这些说法究竟有多靠谱呢?如何才能理性辨别这些说法的真伪呢?著名机器人制造专家、包容体系结构的发明者,MIT AI Lab、CSAIL负责人Rodney Brooks专门写了一篇详尽的文章,剖析了有关AI预测的这个主题与7大陷阱,希望能让大家擦亮眼睛,看清楚观点的虚实。这几乎是最近有关AI预测方面最冷静最理性最靠谱的一篇文章了。就像之前对新兴技术炒作周期曲线的复盘总结一样,人类其实真的非常不擅于预测。
我们都被有关人工智能和机器人的未来的歇斯底里包围了。这种歇斯底里体现在它们会多快变得有多强大上,以及它们会对工作造成什么影响上。
比方说Market Watch近日出了一篇文章,其结论危言耸听,说在10到20年内机器人将夺走目前一半的工作。它甚至还有有一张图来证明这些数字。

这种主张是滑稽的。比方说,它假设说美国的地面维护工人在10到20年的时间里将会从100万人缩减到只用5万人。这些领域目前有多少机器人在用呢?零。机器人在这些领域应用的实际展示案例有多少呢?零。类似的故事适用于上图的所有其他的工作类别(其结论认为目前需要人力的工作当中90%甚至97%都会被大规模颠覆)。
错误的预测会导致大家对不会发生的事情感到恐惧。为什么在人工智能和机器人的预测上总有人不断犯错呢?
以下我概括出了7种导致错误预测机器人于人工智能未来的思维方式。我们在很多有关AI未来的预测中都发现了这些思维方式的影子。我首先会列出注意到的4个一般的主题领域,然后就其现状给出我的简要判断。
A、一般人工智能(AGI)。对AGI的研究是将思维实体从机器学习等当前AI技术中分离出来的一次尝试。其想法是我们可以开发出运作非常类似这个世界上的生命的自动代理。不过AI近期取得的成功根本就不是这样的。
一些人认为所有的AI都是AGI的一个实例,但是“一般”这个词意味着AGI的通用性必须要比目前的AI通用得多。把目前的AI解释成AGI的实例会给人一种现在的AI都这么先进的感觉。
但其实目前的AGI研究无论从通用性或者成为持续存在的独立实体来说根本就做得不好。目前AGI基本上还陷入在50年前遭遇的同样的推理和常识问题上。像人工生命、模拟适应性行为等替代领域在上世纪80、90年代的确取得了一些进展,但现在已经止步不前了。
对此我的观点是从原则上来说这当然是可能的。但是可能我们人类还没有聪明到找出怎么做到的办法。哪怕可能性存在我个人也认为目前距离弄清楚如何做出AGI还非常非常远。
B、奇点。奇点是指最终会有那么一刻,一个基于AI有自己目的和目标的智能实体在进行AI研究方面要比我们人类表现还要出色。然后,在摩尔定律的不断作用下,计算机会跑得越来越快,使得人工智能可以自行发展下去,就像物理学中穿越黑洞的奇点一样,我们也完全不知道另一头会发生什么事情。
“相信”奇点的人乐于赋予后奇点的AI不可思议的能力,反正此后会发生什么是相当难以预测的。我之所以给这种相信加上加重引号,是因为对奇点的信念往往会被当成一种宗教信仰。对于一些人来说这种信念还有额外的福利,那就是可以将自己的思想上传到一台智能计算机上,这样既可以获得永生又没有必须相信存在超自然的上帝的不便。永远强大的技术性的AI对他们而言就是新的上帝。技术宗教!
一些人对于拯救日何时到来有着特别的信念——某位特别的奇点先知(注:应该是指库兹韦尔)的信徒认为这一天会在2029年到来。
这种错误的预测很大程度上是受到了指数论的推动。这个后面我会继续讨论,这属于AI预测方面的七宗罪之一。
即便计算机能力已经很强但这并不意味着我们接近于拥有可以进行人工智能研究,并且还不断改编自身代码从而变得越来越好的程序。
能够理解计算机代码的程序现状如何呢?目前我们还没有能够像刚上了一个月的课的计算机科学专业新生那样理解一页程序的程序。AI系统要想写出比人写的更好的AI系统还有很长一段路要走。
在神经层面模仿大脑是奇点崇拜者经常提到的另一种方法论。我们大概用了30年的时间完全弄清楚了秀丽线虫302个神经元的“接线图”以及其间的7000个连接。这对于理解行为与神经元之间的关联方式极其有用。但这是数百人长达30年的研究成果。而据试图模仿秀丽线虫的OpenWorm项目介绍,他们目前的工作还没有做到一半。要想模仿拥有1000亿神经元以及海量连接的人脑要走的鲁还很远很远。所以如果你指望靠奇点上传你自己到仿真大脑的话,我宁肯再拖几百年再死。
C、价值观背离。第三种情况是基于人工智能的机器非常擅长执行任务,这使得AI在这个复杂的世界里表现得像个超人一样。但它们跟人类没有共同的价值观会导致各种各样的问题。
如果我最近购买过去某城市的机票,突然之间我浏览的所有要广告获得收入的网页上都会出现去往同一城市的机票广告。但我不会视之为超级智能,相反,这说明广告安排算法设计得很糟糕。
不过以下是这种观点的一位支持者的话:
知名的回形针案例是个合适的例子:如果机器唯一的目标是让回形针数量最大化的话,它可能会发明出不可思议的技术,因为它会为此将可达宇宙的一切物质都转化为回形针;但它的决定仍然是哑的(plain dumb,或者说愚蠢)的。
(注:牛津大学人类未来研究院院长、《超级智能:道路、危险和策略》作者Bostrom层提出过一个思想实验:“回形针最大机”。假如有一台生产回形针的机器具备了超级智能,其所有智力就会投入到更好更快更多地制造回形针当中,而最终将是整个地球都变成回形针。它的道德体系就是围绕制造回形针而存在的,它并不爱你也不恨你,它只是把你看做是一坨可供制造回形针的原子而已。Bostrom用这个例子说明机器能够脱离人类控制而自己独立运行。)
好吧,但在现实世界里我们永远也不会出现这样的程序。一个足够聪明的程序,会发明出推翻人类社会给它制定的目标的手段,但是它并不需要理解这些手段会不会给人类造成问题。考虑到技术可能会按照这种方式演进也一样是plain dumb,而且要靠后面讨论的七宗罪中的多个错误才会出现这种情况。
同一位作者反复提出我们需要研究出在数学上验证人工智能系统的目标跟人类目标一致的手段。
我认为研究人员提出的这个C问题看到了一个有趣的知性研究问题,然后发出了他们有力的声音来引起大家的紧迫感。AI的奉承者接受了这个问题,并将之变成了一个人类的存在问题。
顺便说一下,我认为寻求(价值观一致的)数学可证性是徒劳无功的。大型团队几年的努力都没有办法证明1000行的程序不会被外部黑客攻破,那么规模大得多的AI系统的价值观一致性自然就更加无法证实了。好消息是数千年来我们人类能够成功地与本身也是自动化代理、有着自己的渴望以及超人力量的马共存,甚至按照我们的目的去利用后者。但我们对于马还没有发现一条定理。至今都没有!
D、真正邪恶、恐怖、肮脏、灭绝人性的人工智能实体。最后这一类跟C很像,但这种AI驱动的机器会反感人类,并且决定消灭后者。
至少从1960年代末开始,好莱坞就热衷于做起了白日梦:比如说电影《2001:太空漫游(2001: A Space Odyssey )》(1968年,设定场景为2001年),说的是造成了大肆;破坏的机器被紧闭在一艘太空船上;电影《巨人:福宾计划(Colossus: The Forbin Project)》(1970年,背景是当时)的破坏程度更是达到了行星级规模。这些年来该主题经久不衰,最近的电影《我,机器人》(2004年,场景设定为2035年)中邪恶机器人计算机VIKI通过新的人形机器人NS-5接管了世界。
可是这种想法甚至比C错得还要厉害。我认为这必然会引起大家在联想到这些恐怖的危险时产生刺痛的感觉……
现在来谈谈大家经常犯的7个错误。这7个错误都会影响到有关场景A、B、CD的出现可能性和时间尺度的判断。但其中一些的错估我认为会比另外一些更加严重。为此我会在7个错误的小节标题标注出来。而第一个错误会对所有地方都产生不同程度的破坏!
1. [A、B、C、D]高估或者低估
Roy Amara是一位未来学家以及未来研究所(Institute For The Future)的联合创始人兼总裁,风投家,也是硅谷的智慧大脑。他最著名的是他的格言——Amara定律:
我们往往会高估技术的短期影响而又低估了它的长期影响
这寥寥的几个字可以短到用一条推特发布出去,同时也可以从不同的角度进行诠释。乐观主义者可以这样解读,悲观主义者也可以那样解读。这应该会让一些乐观主义者稍微悲观一点,让悲观主义者稍微乐观一点,至少是一阵子,然后再恢复常态。
Amara定理的两面性有一个很好的例子,那就是过去30年对美国的GPS看法。自从1978年以来一个有24(含备件的话是30颗)颗卫星组成的星群被放置到了轨道上面。地面站同时可以看到其中的4颗,然后计算其经纬度以及海拔高度。在科罗拉多州施里弗空军基地(Schriever Air Force Base)的运营中心会不断监控卫星的精确轨道位置以及原子钟的准确性,然后上传细微且连续的调整参数给对方。如果那些更新停止的话,1、2周之后GPS就无法准确地引导你在道路上行驶,然后过来几个月后甚至会误导你跑到另一个城镇去。
GPS的目标是为了给美军的炸弹提供精确制导。这方面的第一次运用是在1991年沙漠风暴行动期间,GPS果然不辱使命。但在1990年代对GPS还是有着很大的不信任,因为GPS并没有兑现其早期承诺,直到2000年初时GPS的实用性才得到了美国军方的认可。在实现早期对其的期望方面GPS经历过一段艰难的日子,整个计划一次又一次地几乎面临夭折。
今天的GPS已经算是处在长期之后,而它在今天的应用是当年不敢想象的。我的Apple Watch Series 2在我外出跑步时会利用GPS记录我的位置,而且可以精确到看清楚我在路的哪一边。接收器尺寸之小、价格之低对于早期GPS的工程师来说是不可思议的。GPS现在已经被那么多的东西使用,很多是设计师从来都未曾想过的。它同步着全球的物理实验,现在是同步美国电网保持其运转的关键部件,甚至还能使得真正控制股市的高频交易商基本不会陷入灾难性的计时错误中。所有的飞机无论大小都要用GPS来导航,它被用于跟踪保释出狱的烦人,决定着应该在全球的哪一块地种植哪一个种子变种。它跟踪我们的卡车队并汇报司机的表现,而地面的反射信号被用于确定地面的水分情况如何,然后确定灌溉的计划。
GPS从一个目标开始但让它达到原先期望的效果却需要一个漫长而艰辛的过程。现在它已经渗透到我们日常生活的方方面面,如果没有它的话我们不仅会走丢,还会挨冷挨饿甚至可能都活不了。
过去30年里我们在其他技术身上也目睹了类似的模式。一开始是很大的预期,然后慢慢地加大信心,超出了我们原先的预计。区块链(比特币是第一个应用)、人类基因组测序、太阳能、风能甚至日用百货的送货上门等都是这样。
也许最引人注目的例子就是计算本身。1950年代当第一台商用计算机部署起来时,对它会夺走所有工作的恐惧在不断扩散(可见1957年的电影《Desk Set》)。但在接下来的30年时间里,计算机几乎没有对大家的生活产生直接影响,甚至到1987年的时候消费者设备也几乎没有任何的微处理器。不过在随后30年的第二波浪潮里一切都变了,现在我们随身都携带这计算机、我们的车子、屋子里都满是它们。
要想看清楚计算机的长期影响力是如何被不断低估的,你只需要回到过去看看它们在旧的科幻电影或者电视节目中有关未来计算机的形象就知道了。1966年《星际迷航》(TOS)里面那台300年后的太空飞船计算机在30年后就变得很可笑,更不要说3个世纪后了。而这《银河飞龙(Star Trek The Next Generation)》以及《银河前哨(Star Trek Deep Space Nine)》这两部时间跨度从1986到1999的系列科幻电影里面,由于无法通过网络(类似彼时的AOL)传送,大型文件仍然需要手工从遥远未来的宇宙飞船或者太空站携带过去。而可供大家搜索的数据库的Web之前的设计完全是缺乏生气的。
大多数技术在短期内都被高估了。它们是耀眼的新生事物。人工智能不断经历着成为耀眼新食物和被高估的过程,1960年代如此,1980年代如此,我们认为现在有再次重演。(大型公司有关其AI产品的一些营销语言其实都是妄想,可能会在不就得将来对他们形成反作用)
就长期而言,并非所有的技术都会被低估,但AI很可能是这样。问题是多久才算长期。接下来要讨论的6个错误有助于解释未来AI的长期性被严重低估了。
2. [B、C、D]想象有魔法出现
我还小的时候,Arthur C. Clarke是科幻小说家的“三巨头”之一(另两位是Robert Heinlein和阿西莫夫)。但Clarke不仅是一位科幻小说家,他还是发明家、科学作家以及未来学家。
1945年,他写了一封信给《Wireless World》,里面谈了有关英语研究的地球同步卫星的想法,当年10月,他发表了一篇论文概括了如何用于提供全球无线电覆盖的办法。1948年,他写了一篇短篇小说《The Sentinel 》,这成为了Stanley Kubrick的AI电影巨作《2001:太空漫游》的核心想法,电影制作的同时Clarke还写了一篇同名的书,解释了许多观众感到迷惑的问题。
1962到1973年间,Clarke提出了三条格言,也就是后来所谓的Clarke三定律(他说牛顿也只有3条定律,所以3条对于他来说也足够了):
定律一:如果一个年高德劭的杰出科学家说,某件事情是可能的,那他可能是正确的。但如果他说,某件事情是不可能的,那他也许是非常错误的;
定律二:要发现某件事情是否可能的界限,唯一的途径是跨越这个界限,从不可能跑到可能中去;
定律三:任何非常先进的技术,初看都与魔法无异。
个人而言我会对他的第一条定律的第二句话比较提防,因为对于AI的发展速度我要比其他人保守得多。不过目前我先来讲讲第三定律。
想象我们有一台时光机(这本身就是强悍的魔术……),可以把牛顿从17世纪末带到剑桥大学的三一学院礼拜堂。他在那里的时候那个礼拜堂已经有100年的历史了,所以在没有意识到当前的日期的情况下他大概不会对自己出现在里面感到非常震惊。
现在给牛顿看样东西。从你兜里掏出一部iPhone,开机,屏幕亮了起来,然后把布满图标的手机交给他。这个通过棱镜揭示了白光是如何由不同色光的成分构成的科学家无疑会对如此小的一个东西能在礼拜堂产生如此丰富的颜色感到惊奇。现在再播放一部英国乡村的风景电影,可能再加上一些他熟悉的动物——内容里面不会出现任何揭示未来的东西。然后再播放一些他熟悉的教堂音乐。再给他看500多页他的巨著《自然哲学的数学原理》的个人注释副本,教他如何利用手势操作来放大文字。
牛顿能不能开始解释这小小的设备究竟是怎么做到这些的呢?虽然他发明了微积分并且对光学和重力做出了解释,但牛顿永远也无法分辨化学与炼金术。所以我认为他会感到困惑,对这台设备究竟是什么东西哪怕连一点思路都没有头绪。对于他来说这设备跟神秘学(牛顿晚年痴迷)的化身无异。对于他来说这跟魔法没有区别。记住,牛顿可是非常聪明的家伙。
如果某个东西是魔法的话就很难知道它的局限是什么了。假设我们进一步给牛顿看到它是如何照亮黑暗、如何拍照和拍电影并且记录声音的,如何被用作放大镜以及镜子的。然后再给他炫一下其算术运算速度有多快,可以精确到小数点后多少位的。我们甚至还可以给他看看他的走路步数是多少。
牛顿还会把猜测面前的这个东西会做哪些事情呢?他会不会猜可以用这个东西把人马上带到世界任何一个地方?棱镜可以永远工作下去。他会不会猜测iPhone也能一直工作下去,而不会理解这个玩意儿需要充电(记住,我们逮住他的时候距离法拉第诞生还有100年,电的概念还没有出现)?如果没有火它也能成为光源,那是不是也能变出金来?
在想象未来技术的时候我们都会出现这样的问题。如果它距离我们今天能够理解的技术太遥远的话,那么我们是无法知道该技术的局限性的。这时候它开始变得与魔法无异。
当一项技术超越了这条魔法线之后,一个人说的任何东西都不再可以证伪,因为它是魔法。
在试图跟人争论我们是否应该对纯粹的AGI(且不说上述C、D情况)感到恐惧时,我经常会遇到这样的问题。我被告知我并不理解它有多强大。这不是一个论据。我们甚至都不知道这样的东西是否存在。我看到的一切迹象均表明我们对怎么造这样的东西毫无头绪。所以它的属性是完全未知的,在修辞上它就迅速变成了魔法和超级强大。没有限制。
要小心哪些有关具有魔力的未来科技的论据。因为这些论据你永远也无法反驳。因为它以信念为基础,而不是科学依据。
3. [A、B、C]表现与能力
估测与我们互动的个人的能力是我们大家都会的社会技能之一。诚然,有时候“脱离群体”的问题往往会超出我们的预计,而这些就是种族主义、性别歧视、阶层歧视的根源。不过就一般而言,我们会利用一个人执行特定任务的表现作为线索来估计他们执行不同任务的表现。我们能够通过观察执行一项任务的表现来进行归纳,猜测其是否胜任其他范围大得多的任务。我们凭直觉来理解如何从一个人的表现水平去归纳出他们在相关领域的能力。
当我身处外国城市时我们在街道上找陌生人问路时,我自信地用我们使用的语言回答并且给出似乎有道理的方向指示,我们认为把我们的幸运往前推进一步是值得的,然后再询问当地的支付系统在哪里因为我们想搭公交到处走走。
如果我们的小孩能配置自己的游戏机连上家庭wifi我们就会猜测如果激励手段足够的话他们还会帮我们把新的平板电脑也连上相同的网络。如果我们注意到某人会开手动挡的车,我们就会相当肯定他们一样也能开自动挡的。
如果我们走进一家大型硬件商店询问一位员工特定物品放在什么地方,比方说家庭电气安装用具放在哪里,而那个人却带我们去到园林工具通道,我们下次大概不会再问同一个人去哪找某个浴室设施。我们会估计他们不仅不知道电气安装用具放在哪里,而且连整个商品布局都不清楚,所以我们会另外找一个人去问位置。
现在我们再来看看更接近今日AI系统表现的另一个例子。
假设有个人告诉我们一张照片是有人在玩飞盘,然后我们自然会假设他们能够回答类似“飞盘是什么样的?”,“一个人大概能扔多远?”,“人可以吃飞盘吗?”,“一次大概有几个人在玩飞盘?”,“今天的天气适合玩飞盘吗?”这样的问题。我们不会预期会说自己不知道图片中发生了什么的、来自不同文化的人能够回答所有那些问题。今天的图片标记系统通常可以给网上的照片出正确的标签,比如“人在公园玩飞盘”,但是不可能回答出那些问题。它们能做的只是可以给更多图像打标签,根本不能回答问题。此外,它们对人是什么,公园往往是在户外,人有年纪,天气不仅仅是决定照片的样子等东西都一无所知。
不过这并不意味着那些系统就一无是处。它们对搜索引擎公司具有极大价值。光是把图像标记好了就能让搜索引擎填补从搜索文字到搜索图片的鸿沟。还要注意搜索引擎对任何查询往往都会提供多个回答然后让人对前面几个回答进行审核确定哪些是实际相关的。搜索引擎公司努力想要提高自身系统的表现,拿到最好的回答放到排名前5左右。但这需要人类用户的认知能力,所以他们不需要每次都先得到最好的回答。如果他们只得到一个回答,无论是搜索“巴黎的好酒店”,还是只提供“有趣的领带”一张可选图片的电子商务网站,其用处就没那么大了。
问题出在哪里呢?大家听说某个机器人或者AI系统已经能执行某种任务了。然后他们就从那种表现归纳出一种认知性相同任务预计具备的一般能力。然后他们再把这种泛化到机器人或AI系统。
今天的机器人和AI系统相对于我们能做的事情在能力上是极其狭隘的。人类的那种概括根本就不具备。而做出这种概括的人就错得太离谱了。
4. [A、B]手提箱单词(Suitcase words)
我在我的一片解释机器学习机制的文章中简单提到过手提箱单词(suitcase words,Marvin Minsky杜撰的词,意思是说一个单词包含有很多含义,就像手提箱打开后里面有很多东西一样)。在那篇文章中我讨论了“学习”这个词应用到人的身上可以有很多种类型的学习。正如我所说那样,人类用于学习不同类型的学习当然会有不同的机制。学习使用筷子跟学习新歌的调子当然是非常不同的体验。学习编写代码跟学习在特定城市穿行也会有很大的不同。
当大家听说机器学习取得了突飞猛进时,他们会考虑在一些新领域的机器学习,他们往往将人学习该新领域的心智模式套用过去。然而,机器学习是非常脆弱的,每一个新的问题领域需要研究人员或者工程师的大量准备,要有特定目的的编码来处理输入数据,需要特殊用途的训练数据,以及定制的学习结构。今天计算机的机器学习根本就不是像人类的那种海绵式的吸收,可以无需进行手术般篡改或者有目的开发的基础上就能在新的领域取得快速进展。
类似的,当大家听说计算机现在可以击败世界国际象棋冠军(1997年)或者围棋世界冠军(2016年)时,他们往往认为机器就像人一样在“下”棋。当然在现实中这些程序对游戏是什么样以及自己的下法其实是一无所知的。就像那篇大西洋月刊的文章指出那样,李世石只需要12盎司的咖啡就能思路敏捷,而AI程序Alphago作为分布式应用却需要大量的机器部署,并且要有超过100位科学家的背后支撑。
人在比赛的时候规则的一点小改动并不会让他们迷惑——好的玩家懂得适应。但Alphago或者1997年击败卡斯帕罗夫的深蓝就不行。
手提箱单词导致大家在理解机器执行人类能做的事情有多好时会误入歧途。而另一方面,AI研究人员,更糟的是其所在机构的新闻处则渴望宣称自己所取得的进展就是手提箱单词之于人类的一个例子。这里重要的是“一个例子”。无论研究人员再怎么小心(不幸的是并不是所有人都那么小心),只要研究结果传到了新闻办公室再传到外部媒体那里,细节很快就被弄丢了。新闻头条开始吹嘘那个手提箱单词,并且误导对AI的一般理解,以及距离实现更多还有多近。
还有,我们甚至还没怎么谈到Minsky列举的许多有关AI系统的手提箱单词;比如意识、经历或者思考等。对我们人类来说在没有意识、或者没有下棋经验,或者思考走法的情况下,下棋是很难想象的。迄今为止,在实现手提箱单词所代表的灵活性方面,我们的AI系统还没有一个提升到入门级的水平。而当我们的确开始可以在特定AI系统运用其中一些单词时,媒体和大多数人可能又会再度把这种能力过度一般化了。
我担心的是这些单词的部分含义哪怕只是在非常狭隘的一方面得到了证明大家也会过度一般化,以为机器在具备智能的这些方面已经接近类似人类能力的大门。
用语很重要,但只要我们用一个词语描述有关AI系统的某个东西时,如果这个词也适用于人的话,我们发现大家就会高估其含义。迄今为止大多数适用人类的单词在用到机器身上时,都不过是用在人身上含义的万千之一而已。
以下是一些应用到机器身上,但在能力方面完全不像人类的的动词:
预期(anticipate)、击败(beat)、 分类(classify)、 描述(describe)、 估计(estimate)、 解释(explain)、 产生幻觉(hallucinate)、 听(hear)、想象(imagine)、 企图(intend)、 学习(learn)、 建模(model)、计划(plan)、 玩(play)、 认识(recognize)、读(read)、 推理(reason)、 反映(reflect)、 看(see)、 理解(understand)、走(walk)、写(write)
这导致大家会误解然后高估了今天的人工智能的能力。
5. [A、B、B、B……]指数性
很多人都遭受过所谓的“指数论”之苦。
每个人对摩尔定律都有自己的想法,至少知道计算机会像发条般精确地变得越来越快。
其实摩尔的说法是芯片可容纳的元件数量每年都会翻番。我曾经写过一篇文章说明这个规律在见效了50年之后终于要走到头了。1965年摩尔做出预测的时候所用的下面这张图只有4个数据点:
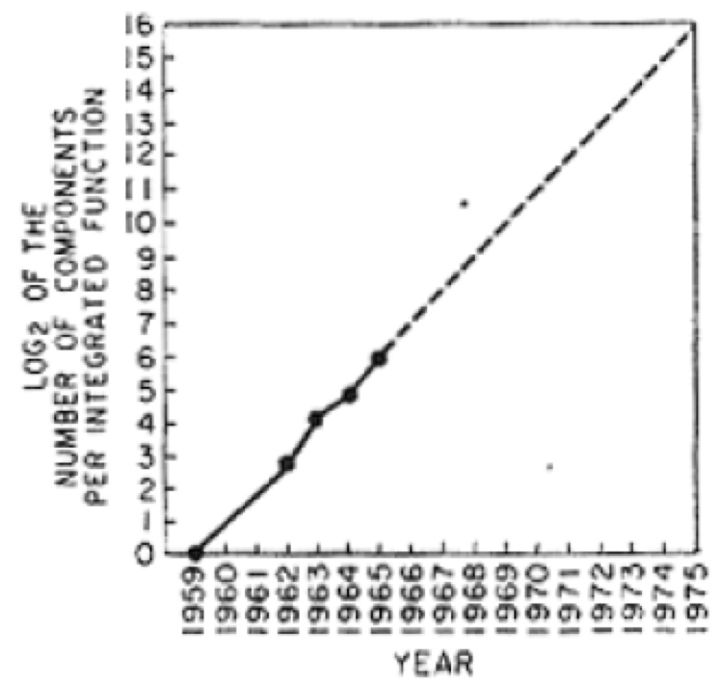
他的推断只有10年时间,但是规律延续了50年,尽管时间常数逐步从1年延长到2年,而现在它终于走到了尽头。
把芯片的元件数翻番使得计算机速度也加倍。而且还使得内存芯片每2年容量变成之前的4倍。这还导致了数字照相机分辨率越来越高,LCD屏幕像素呈指数增长。
摩尔定律见效的原因在于它适用于真/假的数字化抽象。存在电荷或者电压吗?当电子数减半再减半时答案还是一样的。但当减半到只剩下几个电荷时量子效应就开始发挥主导作用,而我们的硅晶芯片技术现在就走到这个关节点上。
摩尔定律,以及像摩尔定律这样的指数定律会因为三个不同的原因失效:
达到物理极限,使得减半/加倍的过程不再见效。
市场需求达到饱和,使得定律继续的经济驱动力消失
一开始可能就不是指数性过程。
当一个人受到指数论影响时,他们可能就会无视上述任何一个原因,并且认为他们用来证明自己论点的指数性还会继续。
在第一个原因的作用下摩尔定律现在已经步履蹒跚,但正是因为摩尔定律50年的作用才导致了技术业的不断创新和硅谷、风投的崛起,让一批极客成为全世界最富有的人,这也导致太多的人认为包括AI在内的技术的一切都是呈指数性发展的。
很多指数性过程其实只是“S曲线”的一部分,这一点很多人都应该知道,也就是说到了一定时候超级高速的增长就会放缓。诸如Facebook、Twitter等社交平台用户数的指数性增长最终必将变成S曲线,因为可变成新用户的人数是有限的,所以指数性增长不可能一直持续下去。这就是上面第二个原因的例子。
但还不止这些。有时候仅是来自个人用户的需求有一阵子看起来也像是指数性的,但随后就变得饱和了。
回到本世纪初时我正在管理着MIT一家很大的实验室(CSAIL),需要给超过90家研究小组筹集研究经费,我试图向赞助商表明iPod的内存增长有多快。跟摩尔不一样的是我有5个数据点!数据是关于400美元可以给iPod提供多大存储。数据如下:
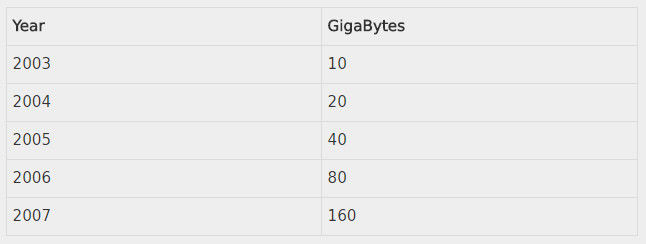
数据呈现出完美的指数性。然后,我再向外推几年询问兜里这些内存都可以用来做什么。
如果外推到现在预计400美元的iPod应该有160000GB(或者160TB)的内存。但是今天最高配的iPhone(售价超过400美元)也只有256GB的内存,还不到2007年的iPod的2倍,而最高配的iPod也只有128GB,相对于10年前的型号内存反而还下降了。
当内存容量大到可以容纳任何理性之人的完整音乐库时,这个特别的指数性就会突然之间崩塌。当客户需求不再时指数性也会停止。
继续,由于深度学习的成功我们已经目睹了AI系统突然有了很好的表现。很多人似乎认为这意味着AI相当于乘数效应的性能提升会继续常态化进行下去。但其实深度学习的成功是30年不懈努力的结果,没人能够预测到这一点。这只是个孤立事件。
这并不意味着不会有更多的孤立事件,也就是一潭死水似的AI研究突然会给许多AI应用插上翅膀。但是这种情况的发生频率如何并没有“定律”可循。这里面并没有物理过程,就像摩尔定律里面的大量材料那样为AI的创新提供动力。这就是上面的第三个原因的例子。
所以当你看到有人把指数性增长作为AI发展的判断依据时,记住并不是所有所谓的指数性一开始都是真的具备指数性特征的,而有的在达到物理极限或者缺少更多的经济影响时时就会崩塌。
6.[C、D]好莱坞场景
很多好莱坞科幻电影的情节都是这样的:世界跟今天的还是一样,除了一个转折。当然对于电影来说外星人入侵地球是讲得通的。一切都像往常一样,但随后有一天外星人突然就出现了。
这类世界的单个变化对外星人来说是具有逻辑意义的,但对于新技术来说如何呢?在现实生活当中很多新技术多多少少是同时发生的。
有时候在好莱坞的现实里面对于为什么在人类的技术世界里面会出现单个的颠覆(其他都没有变化)有着一定的合理性解释。比方说《未来终结者》里面就有通过时间旅行穿越的来自未来的超级技术,所以施瓦辛格扮演的超级机器人的出现不需要一个积累的过程。
但在其他一些电影里面情况似乎有点愚蠢。
在《机器管家》里面,有一幕是Sam Neill扮演的Richard Martin坐下来由Robin Williams扮演的人性机器人服侍吃早餐。他一边吃早餐一边拿起一份报纸来看。报纸!印刷的报纸。而不是平板电脑,或者类似Amazon Echo这样的设备播放播客,这种设定跟互联网并没有直接的神经连接。
在《银翼杀手》中,哈里森·福特扮演的Rick Deckard想要接触Sean Young扮演的机器人Rachael。故事中Rachael跟人是难以分辨的。Deckard是怎么跟她接头的呢?通过投币式公用电话。你得往里面塞进硬币。这种玩意相信本文的许多读者从来都没见过。
这就是好莱坞电影的两个例子,在这些例子当中作家、导演、制片想象会有一个人形机器人,它能够看、听、说,并且像人一样行动——几乎就是AGI了。其中涉及的神乎其神的材料和机制姑且就不管了。但那些创意人才却缺乏想象,或者意愿去考虑世界的其他方面可能也会随着该技术的形成而改变。
结果证明,很多AI研究人员和AI权威,尤其是那些沉溺于预测C、D的悲观主义者,其想象力也类似地受到挑战。
除了许多C、D的时间尺度预测错了以外,他们还忽视了一个事实,那就是入股我们最终能够开发出那么聪明的设备的话,那时候的世界跟我们现在的那个一定会有显著的不同。我们不会突然被此类超级智能的出现给吓到。它们会在技术上逐渐演进,我们的世界会变得不一样,会充斥着许多其他的智能,而且我早已经有了很多体验。
比方说,在D(想要干掉我们的邪恶超级智能)的出现很久之前,我们会看到不那么聪明和好战的机器出现。在此之前会是脾气真的很暴躁的机器。再往前则是相当乏味的机器。而在它们之前则是自大讨厌的机器。
这一路上我们会改变我们的世界,既要为了新技术调整环境,也要对新技术本身进行调整。我不是说可能不会有挑战。而是说未必回想很多人以为那样是突然的、意料之外的。关于令人震惊场合的天马行空的想象是没有帮助的——这些永远都是错的,或者甚至连接近都算不上。
“好莱坞场景”是很好的论证手段,但通常跟未来现实并没有任何关联。
7. [B、C、D]部署速度
随着这个世界变成了软件,新版本的部署频率在一些行业已经变得非常高。像Facebook这样的平台的新功能几乎是按小时为周期部署的。对于许多新功能来说,只要通过了集成测试,如果现场出现问题需要回退到旧版本的话经济的负面影响是非常小的——我经常发现在此类平台上使用的功能突然失效1小时左右,我认为算是部署失败。对于产生收入的组件,比如广告投放组件来说,需要更加小心一点,而发生的频率是以周计算的。
这属于硅谷和Web软件开发者早已习以为常的节奏。这种节奏有效是因为新部署代码的边际成本非常非常接近于0。
但硬件的边际成本就很高。我们在日常生活就能感受到。我们今天购买的很多汽车都不是自动驾驶的,大多数也都不是软件使能的,到2040年的时候可能还会在道路上出现。这就给我们的车多快变成自动驾驶增加了天然的限制。如果我们今天要建个新家,我们的预计是它应该能顶100年左右。我现在住的建筑是在1904年建造的,在我的邻居里面还远算不上最古老的建筑。
资本成本让物理硬件存活很长一段时间,即便有了高科技的出现,即便它还有存在主义使命要履行。
美国空军的B-52轰炸机仍然在服役。该版飞机是在1961年引进的,至今已经56年。最后一架是在1963年建造的,大概也已经有54年了。现在这批飞机预计要服役到2040年,可能还要更久——有讨论要把它们的寿命延长到100年。
美国的路基洲际弹道导弹(ICBM)是民兵-III的变种,1970年引进。数量一共有450。其发射系统要靠8英寸的软盘驱动器,发射过程中的一些数字通信是通过模拟电话线进行的。
我在世界各地的工厂里经常看到几十年的老设备。我甚至见过工厂里运行Windows 3.0(1990年推出)的PC。其思维模式是“如果没坏就不要修”。那些PC和软件已经可靠地运行同一个软件执行同样的任务超过20年了。
欧美中日韩的工厂,包括全新的工厂,其主要的控制机制都是基于可编程逻辑控制器(PLC)的。这是在1968年引入来取代继电器的。“线圈”仍然是目前使用的主要抽象单元,PLC的编程方式也像是存在一个24V继电器网络一样。尽管如此,一些直连线已经被以太网电缆取代。它们模拟的是基于RS485 8位串行字符协议的更古老网络,后者携带的是模仿24V DC电流开关。而以太网电缆并不是开放网络的一部分,相反,一根根独立的电缆都是点对点连接的,体现的是这些崭新的古老知道控制器的控制流。当你想要改变信息流或者控制流时,全球大多数工厂都需要找来顾问用数周的时间弄清楚上面有什么,设计新的重新配置,然后一群商人队伍再进行重新布线,对硬件进行重新配置。这种设备的一家主要制造商最近告诉我说他们的节奏是每20年更新3次软件。
原则来说这事儿可以换种做法。但在实践上不可行。我在讨论的可不仅仅是技术停滞的地方。就在这个时候我还在看着职位需求列表,就在今天,Tesla的工厂还试图招聘全职的PLC技术人员。通过继电器仿真来对当今最先进的AI软件驱动的汽车生产进行自动化。
很多的AI研究人员和权威想象这个世界已经是数字化了,只需要把新的AI系统引进来就能马上给现场、供应链、车间、产品设计带来运营方面的改变。
这跟事实完全是南辕北辙。
自动化重新配置的阻抗实在是惊人的、令人错愕的不灵活。
这一领域你很难给出一个好点子。改变实在是太慢了。制造回形针的AI系统决定动用一切资源以其他人类需求为代价生产出越来越多的回形针的例子其实只是个怪异的白日梦。未来几十年内在这个循环里面都会有关心布线问题的人的参与。
几乎所有机器人和AI方面的创新都需要很长很长的时间才能广泛部署,所需时间之长要超出圈子内外的人的想象。无人车就是个例子。突然之间每个人都认识了这个东西,以为很快就会部署。但这所需的时间比想象得要长得多。它需要几十年,而不是几年。如果你认为这种想法有点悲观的话你应该意识到自从第一辆无人车路演至今已经30年过去但还是没有部署。1987年Ernst Dickmanns和他的团队在慕尼黑联邦国防军大学已经能让他们的无人车以90公里的时速在高速路上行驶了20公里。1995年7月,由Chuck Thorpe和Takeo Kanade领衔的CMU团队研发的第一辆不用手握方向盘脚踩踏板的厢式旅行车实现了横穿美国东西海岸的壮举。Google/Waymo做无人车已经有8年了,但是大规模部署仍然遥遥无期。从1987年算起,可能需要40、50或者60年我们才能有无人车的真正部署。
机器人和AI的新想法也需要很长很长的时间才能变成现实、部署起来。
结语
当你看到权威对将来的机器人和人工智能奇迹或者恐怖提出警告时,我建议你仔细对他们的观点进行评估,看看有没有陷入这7个陷阱。根据我的经验,从他们的论点里面你总能找到2、3或者4个这样的漏洞。
预测未来真的很难,尤其是提前预测更是难上加难。
