视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据技术Spark教程-笔记01【Spark(概述、快速上手、运行环境、运行架构)】
- 尚硅谷大数据技术Spark教程-笔记02【SparkCore(核心编程,map、mapPartitions、mapPartitionsWithIndex、flatMap、glom、groupBy、filter、sample、distinct、coalesce、repartition、sortBy、intersection、union、subtract、zip)】
- 尚硅谷大数据技术Spark教程-笔记03【SparkCore(核心编程,partitionBy、reduceByKey、groupByKey、aggregateByKey、foldByKey、combineByKey、sortByKey、join、leftOuterJoin、cogroup)】
目录
01_尚硅谷大数据技术之SparkCore
第05章-Spark核心编程
P063【063.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - partitionBy(前面有吸气,中间有等待)】10:18
P064【064.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - partitionBy - 思考的问题】05:56
P065【065.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - reduceByKey】06:06
P066【066.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - groupByKey】04:14
P067【067.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - groupByKey & reduceByKey的区别】18:57
P068【068.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey】11:09
P069【069.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey - 图解】13:29
P070【070.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - foldByKey】03:54
P071【071.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey - 小练习】08:51
P072【072.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey - 小练习 - 图解】06:04
P073【073.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - combineByKey】08:04
P074【074.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - 聚合算子的区别】09:12
P075【075.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - join】07:00
P076【076.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - leftOuterJoin & rightOuterJoin】03:25
P077【077.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - cogroup】04:28
P078【078.尚硅谷_SparkCore - 核心编程 - RDD - 案例实操 - 需求介绍 & 分析】18:50
P079【079.尚硅谷_SparkCore - 核心编程 - RDD - 案例实操 - 需求设计】06:41
P080【080.尚硅谷_SparkCore - 核心编程 - RDD - 案例实操 - 功能实现】08:18
01_尚硅谷大数据技术之SparkCore
第05章-Spark核心编程
P063【063.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - partitionBy(前面有吸气,中间有等待)】10:18
17) partitionBy
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object Spark14_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - (Key - Value类型)
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val mapRDD: RDD[(Int, Int)] = rdd.map((_, 1))
// RDD => PairRDDFunctions
// 隐式转换(二次编译)
// partitionBy根据指定的分区规则对数据进行重分区
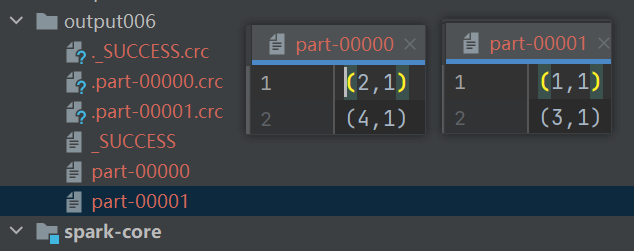
val newRDD = mapRDD.partitionBy(new HashPartitioner(2))
newRDD.partitionBy(new HashPartitioner(2))
newRDD.saveAsTextFile("output006")
sc.stop()
}
}
P064【064.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - partitionBy - 思考的问题】05:56
17) partitionBy
- 思考一个问题:如果重分区的分区器和当前RDD的分区器一样怎么办?
如果重分区的分区器和当前RDD的分区器一样,那么实际上不需要进行重分区操作,因为分区器相同意味着数据已经按照相同的方式分配到了各个分区中。这种情况下,重分区操作不会改变数据的分布,只是会产生额外的开销。
如果确实需要进行重分区操作,可以考虑使用repartition方法,它会根据指定的分区数重新分配数据到各个分区中,即使新的分区数与原来的分区数相同,也会重新洗牌数据。如果新的分区数比原来的分区数多,那么新分区中可能会有一些空分区。
- 思考一个问题:Spark还有其他分区器吗?有!
- 思考一个问题:如果想按照自己的方法进行数据分区怎么办?自己写分区器。
- 思考一个问题:哪那么多问题?略略略~
P065【065.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - reduceByKey】06:06
18) reduceByKey

package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object Spark15_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - reduceByKey
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// reduceByKey:相同的key的数据进行value数据的聚合操作
// scala语言中一般的聚合操作都是两两聚合,spark基于scala开发的,所以它的聚合也是两两聚合
// 【1,2,3】
// 【3,3】
// 【6】
// reduceByKey中如果key的数据只有一个,是不会参与运算的。
val reduceRDD: RDD[(String, Int)] = rdd.reduceByKey((x: Int, y: Int) => {
println(s"x = ${x}, y = ${y}")
x + y
})
reduceRDD.collect().foreach(println)
sc.stop()
}
}
P066【066.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - groupByKey】04:14
19) groupByKey
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark16_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - groupByKey
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
// groupByKey:将数据源中的数据,相同key的数据分在一个组中,形成一个对偶元组
// 元组中的第一个元素就是key
// 元组中的第二个元素就是相同key的value的集合
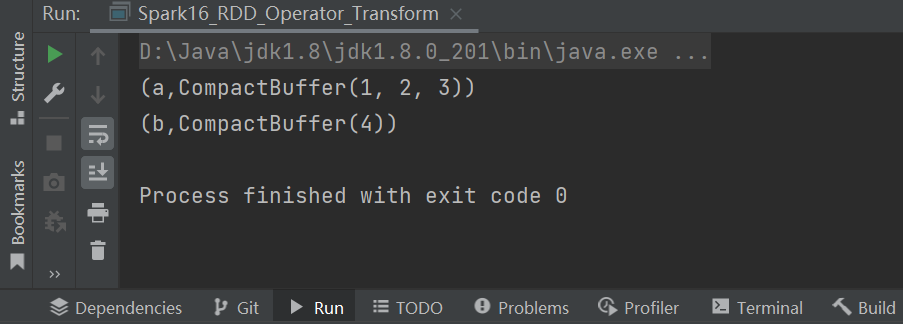
val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()
groupRDD.collect().foreach(println)
val groupRDD1: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)
sc.stop()
}
}
P067【067.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - groupByKey & reduceByKey的区别】18:57
19) groupByKey
思考一个问题:reduceByKey 和 groupByKey 的区别?
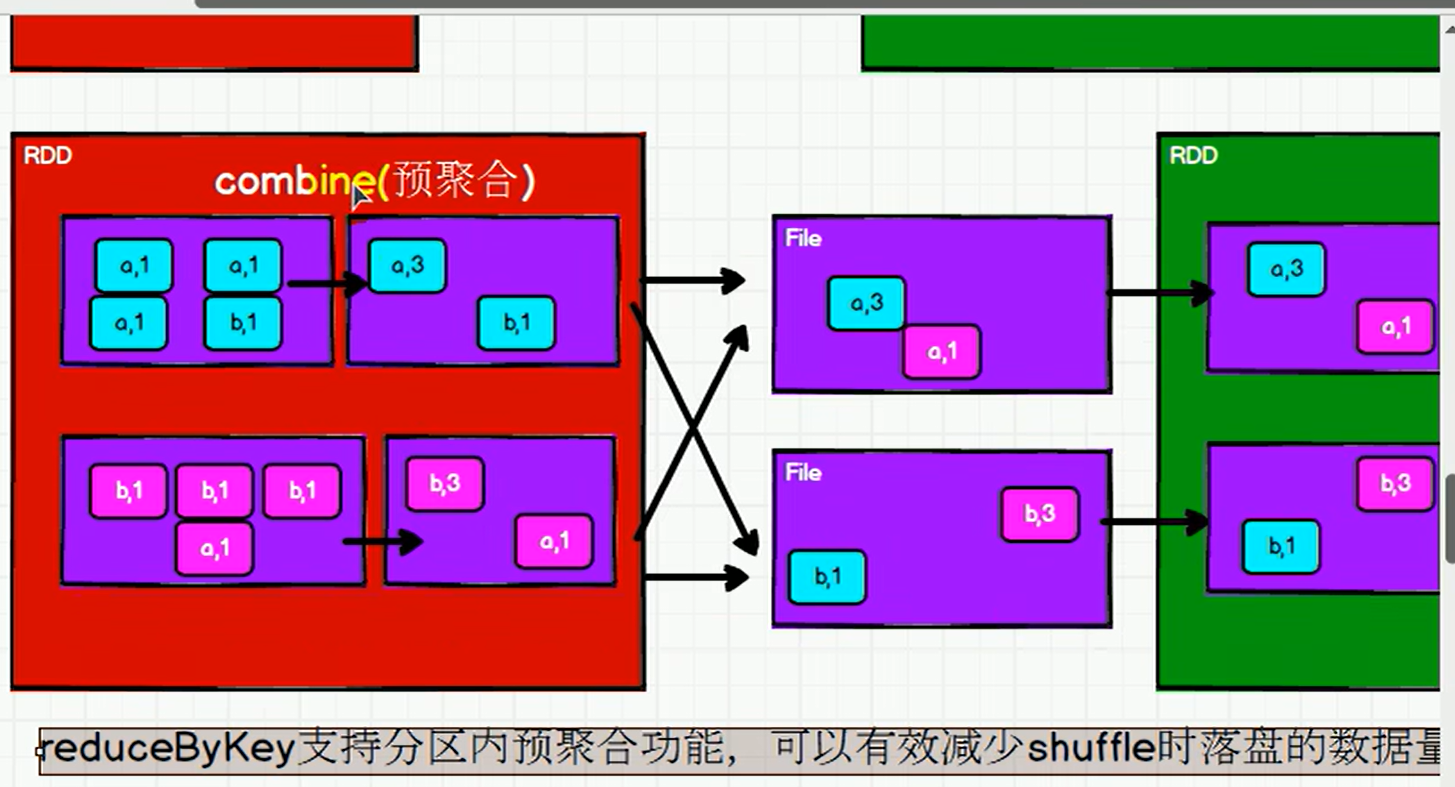
- 从shuffle的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
- 从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用groupByKey。
P068【068.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey】11:09
20) aggregateByKey

package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark17_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - aggregateByKey
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("a", 4)
), 2)
// (a,【1,2】), (a, 【3,4】)
// (a, 2), (a, 4)
// (a, 6)
// aggregateByKey存在函数柯里化,有两个参数列表
// 第一个参数列表,需要传递一个参数,表示为初始值
// 主要用于当碰见第一个key的时候和value进行分区内计算
// 第二个参数列表,需要传递2个参数
// 第一个参数表示分区内计算规则
// 第二个参数表示分区间计算规则
// math.min(x, y)
// math.max(x, y)
rdd.aggregateByKey(0)(
(x, y) => math.max(x, y),
(x, y) => x + y
).collect.foreach(println)
sc.stop()
}
}
P069【069.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey - 图解】13:29
20) aggregateByKey
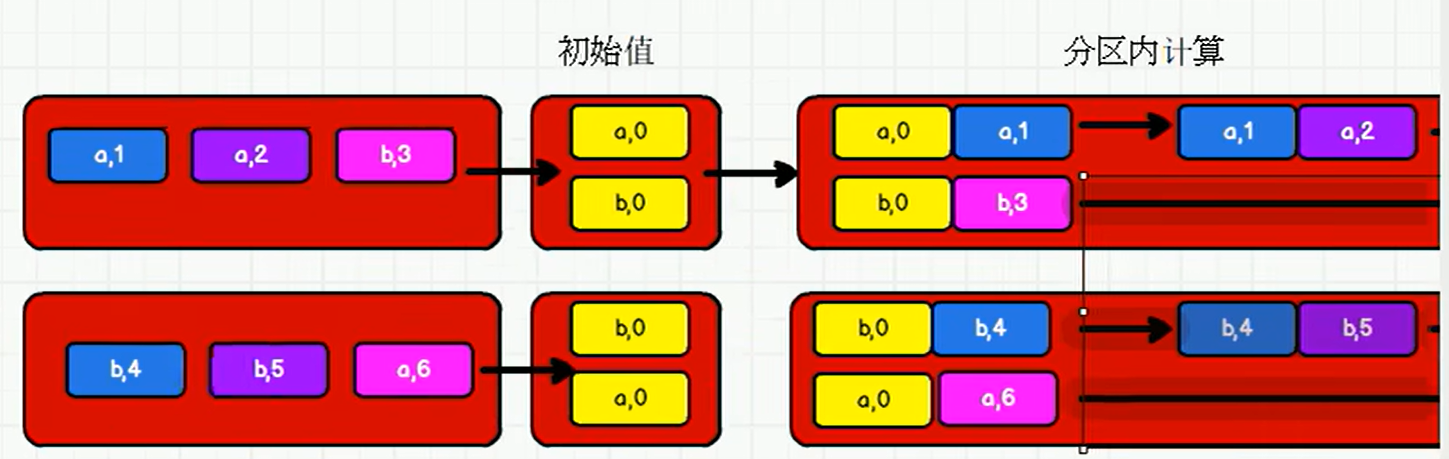
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
object Spark17_RDD_Operator_Transform1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - aggregateByKey
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// (a,【1,2】), (a, 【3,4】)
// (a, 2), (a, 4)
// (a, 6)
// aggregateByKey存在函数柯里化,有两个参数列表
// 第一个参数列表,需要传递一个参数,表示为初始值
// 主要用于当碰见第一个key的时候,和value进行分区内计算
// 第二个参数列表,需要传递2个参数
// 第一个参数表示分区内计算规则
// 第二个参数表示分区间计算规则
// math.min(x, y)
// math.max(x, y)
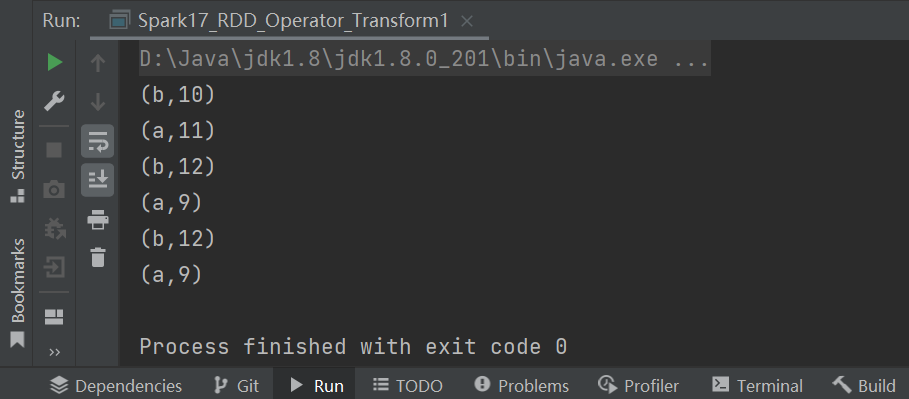
rdd.aggregateByKey(5)(
(x, y) => math.max(x, y),
(x, y) => x + y
).collect.foreach(println)
sc.stop()
}
}
P070【070.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - foldByKey】03:54
20) aggregateByKey
rdd.aggregateByKey(0)(
(x, y) => x + y,
(x, y) => x + y
).collect.foreach(println)
rdd.aggregateByKey(0)(_ + _, _ + _).collect.foreach(println) //简化
21) foldByKey
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.{SparkConf, SparkContext}
object Spark17_RDD_Operator_Transform2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - foldByKey
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// rdd.aggregateByKey(0)(_+_, _+_).collect.foreach(println)
// 如果聚合计算时,分区内和分区间计算规则相同,spark提供了简化的方法
rdd.foldByKey(0)(_ + _).collect.foreach(println)
sc.stop()
}
}
P071【071.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey - 小练习】08:51
20) aggregateByKey
- 函数签名:def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
- 函数说明:将数据根据不同的规则进行分区内计算和分区间计算。
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark18_RDD_Operator_Transform3 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - aggregateByKey
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// aggregateByKey最终的返回数据结果应该和初始值的类型保持一致
// val aggRDD: RDD[(String, String)] = rdd.aggregateByKey("")(_ + _, _ + _)
// aggRDD.collect.foreach(println)
// 获取相同key的数据的平均值 => (a, 3),(b, 4)
val newRDD: RDD[(String, (Int, Int))] = rdd.aggregateByKey((0, 0))(
(t, v) => {
(t._1 + v, t._2 + 1)
},
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val resultRDD: RDD[(String, Int)] = newRDD.mapValues {
case (num, cnt) => {
num / cnt
}
}
resultRDD.collect().foreach(println)
sc.stop()
}
}
P072【072.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - aggregateByKey - 小练习 - 图解】06:04

P073【073.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - combineByKey】08:04
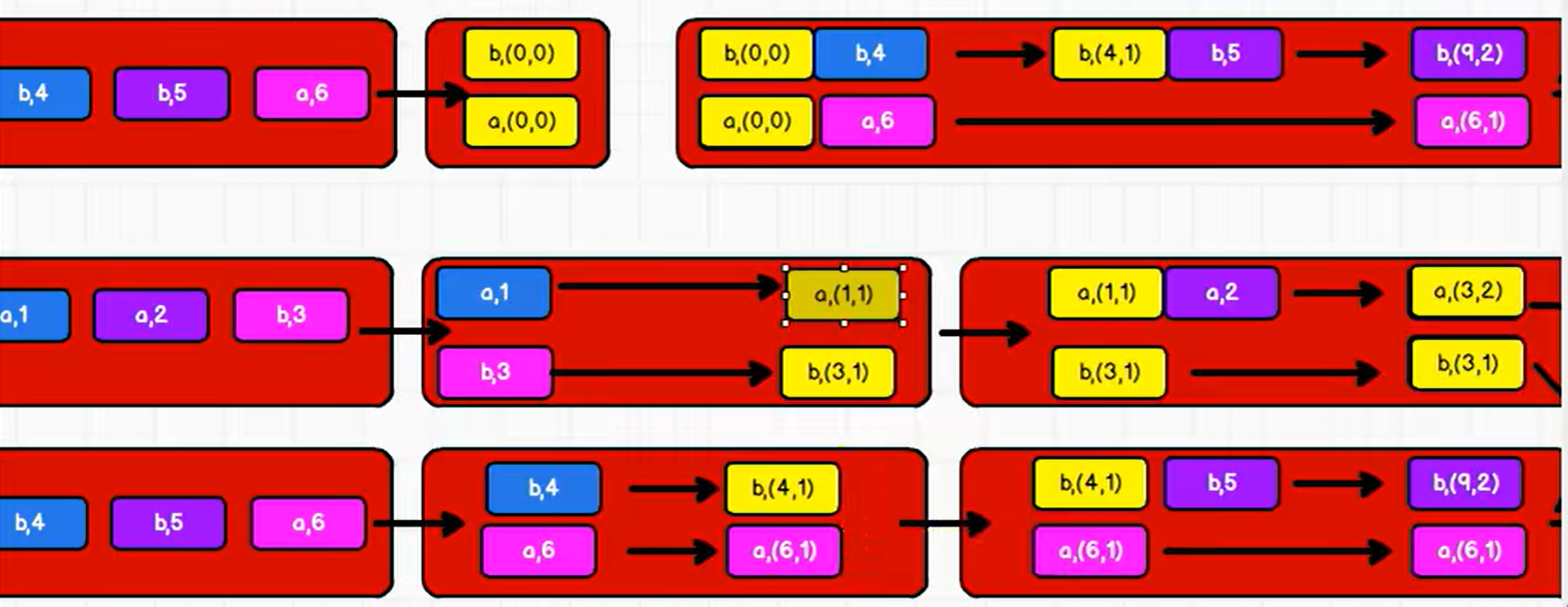

package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark19_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - combineByKey
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
// combineByKey:方法需要三个参数
// 第一个参数表示:将相同key的第一个数据进行结构的转换,实现操作
// 第二个参数表示:分区内的计算规则
// 第三个参数表示:分区间的计算规则
val newRDD: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val resultRDD: RDD[(String, Int)] = newRDD.mapValues {
case (num, cnt) => {
num / cnt
}
}
resultRDD.collect().foreach(println)
sc.stop()
}
}
P074【074.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - 聚合算子的区别】09:12
22) combineByKey
思考一个问题:reduceByKey、foldByKey、aggregateByKey、combineByKey的区别?
- reduceByKey:相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同。
- FoldByKey:相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相同。
- AggregateByKey:相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同。
- CombineByKey:当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区内和分区间计算规则不相同。
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark20_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)
), 2)
/*
reduceByKey:
combineByKeyWithClassTag[V](
(v: V) => v, // 第一个值不会参与计算
func, // 分区内计算规则
func, // 分区间计算规则
)
aggregateByKey:
combineByKeyWithClassTag[U](
(v: V) => cleanedSeqOp(createZero(), v), // 初始值和第一个key的value值进行的分区内数据操作
cleanedSeqOp, // 分区内计算规则
combOp, // 分区间计算规则
)
foldByKey:
combineByKeyWithClassTag[V](
(v: V) => cleanedFunc(createZero(), v), // 初始值和第一个key的value值进行的分区内数据操作
cleanedFunc, // 分区内计算规则
cleanedFunc, // 分区间计算规则
)
combineByKey:
combineByKeyWithClassTag(
createCombiner, // 相同key的第一条数据进行的处理函数
mergeValue, // 表示分区内数据的处理函数
mergeCombiners, // 表示分区间数据的处理函数
)
*/
rdd.reduceByKey(_ + _) // wordcount
rdd.aggregateByKey(0)(_ + _, _ + _) // wordcount
rdd.foldByKey(0)(_ + _) // wordcount
rdd.combineByKey(v => v, (x: Int, y) => x + y, (x: Int, y: Int) => x + y) // wordcount
sc.stop()
}
}
P075【075.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - join】07:00
23) sortByKey
...
24) join
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark21_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 算子 - join
val rdd1 = sc.makeRDD(List(
("a", 1), ("a", 2), ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 5), ("c", 6), ("a", 4)
))
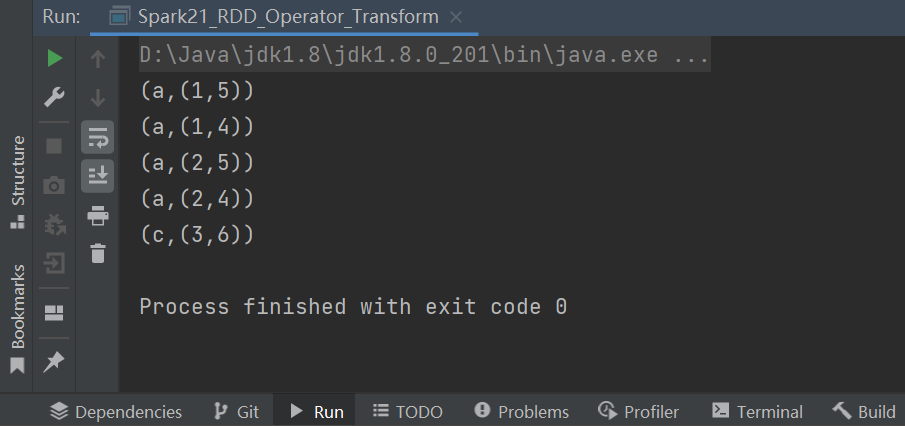
// join:两个不同数据源的数据,相同的key的value会连接在一起,形成元组
// 如果两个数据源中key没有匹配上,那么数据不会出现在结果中
// 如果两个数据源中key有多个相同的,会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长,会导致性能降低。
val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
sc.stop()
}
}
P076【076.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - leftOuterJoin & rightOuterJoin】03:25
25) leftOuterJoin
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark22_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2) //, ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6)
))
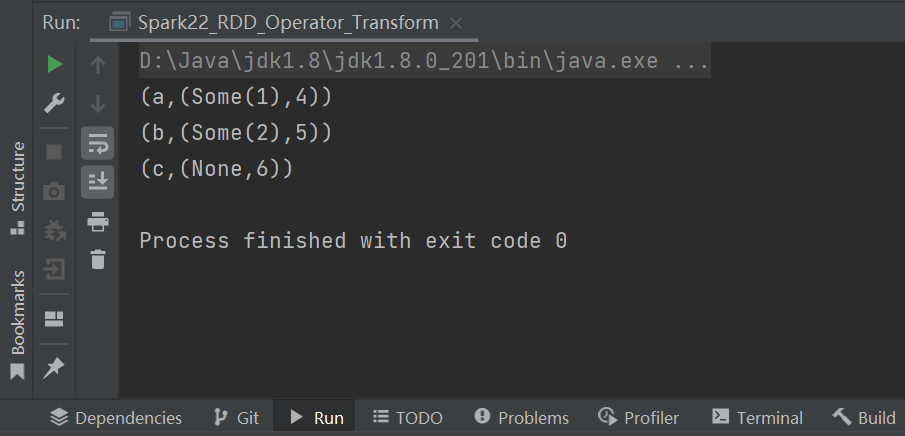
//val leftJoinRDD = rdd1.leftOuterJoin(rdd2)
val rightJoinRDD = rdd1.rightOuterJoin(rdd2)
//leftJoinRDD.collect().foreach(println)
rightJoinRDD.collect().foreach(println)
sc.stop()
}
}
P077【077.尚硅谷_SparkCore - 核心编程 - RDD - 转换算子 - cogroup】04:28
26) cogroup
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark23_RDD_Operator_Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2) //, ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6), ("c", 7)
))
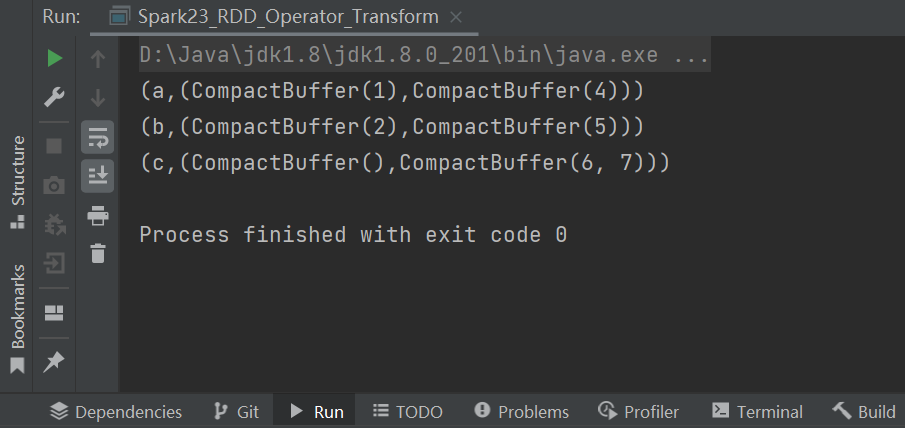
// cogroup:connect + group (分组,连接)
val cgRDD: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
cgRDD.collect().foreach(println)
sc.stop()
}
}
P078【078.尚硅谷_SparkCore - 核心编程 - RDD - 案例实操 - 需求介绍 & 分析】18:50
5.1.4.4 案例实操
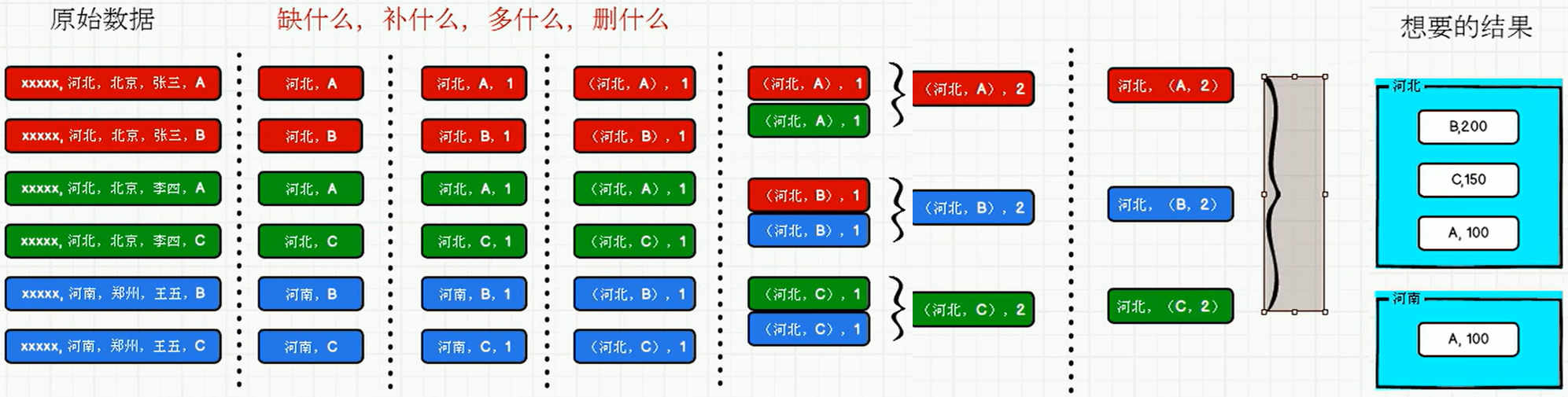
- 数据准备
- agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。
- 需求描述
- 需求分析
- 功能实现


P079【079.尚硅谷_SparkCore - 核心编程 - RDD - 案例实操 - 需求设计】06:41
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark24_RDD_Req {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 案例实操
// 1. 获取原始数据:时间戳,省份,城市,用户,广告
// 2. 将原始数据进行结构的转换。方便统计
// 时间戳,省份,城市,用户,广告
// =>
// ( ( 省份,广告 ), 1 )
// 3. 将转换结构后的数据,进行分组聚合
// ( ( 省份,广告 ), 1 ) => ( ( 省份,广告 ), sum )
// 4. 将聚合的结果进行结构的转换
// ( ( 省份,广告 ), sum ) => ( 省份, ( 广告, sum ) )
// 5. 将转换结构后的数据根据省份进行分组
// ( 省份, 【( 广告A, sumA ),( 广告B, sumB )】 )
// 6. 将分组后的数据组内排序(降序),取前3名
// 7. 采集数据打印在控制台
}
}
P080【080.尚硅谷_SparkCore - 核心编程 - RDD - 案例实操 - 功能实现】08:18
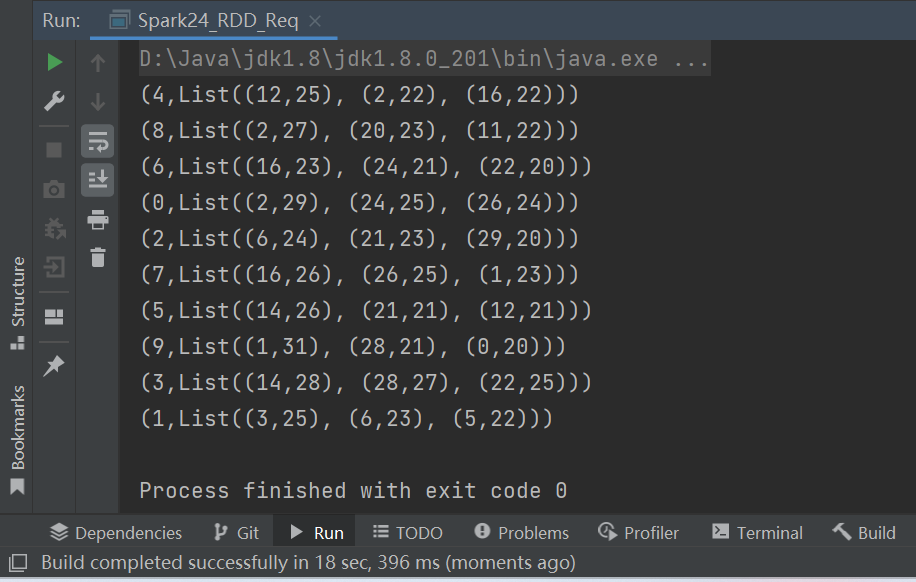
package com.atguigu.bigdata.spark.core.rdd.operator.transform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark24_RDD_Req {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO 案例实操
// 1. 获取原始数据:时间戳,省份,城市,用户,广告
val dataRDD = sc.textFile("datas/agent.log")
// 2. 将原始数据进行结构的转换。方便统计
// 时间戳,省份,城市,用户,广告
// =>
// ( ( 省份,广告 ), 1 )
val mapRDD = dataRDD.map(
line => {
val datas = line.split(" ")
((datas(1), datas(4)), 1)
}
)
// 3. 将转换结构后的数据,进行分组聚合
// ( ( 省份,广告 ), 1 ) => ( ( 省份,广告 ), sum )
val reduceRDD: RDD[((String, String), Int)] = mapRDD.reduceByKey(_ + _)
// 4. 将聚合的结果进行结构的转换
// ( ( 省份,广告 ), sum ) => ( 省份, ( 广告, sum ) )
val newMapRDD = reduceRDD.map {
case ((prv, ad), sum) => {
(prv, (ad, sum))
}
}
// 5. 将转换结构后的数据根据省份进行分组
// ( 省份, 【( 广告A, sumA ),( 广告B, sumB )】 )
val groupRDD: RDD[(String, Iterable[(String, Int)])] = newMapRDD.groupByKey()
// 6. 将分组后的数据组内排序(降序),取前3名
val resultRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
}
)
// 7. 采集数据打印在控制台
resultRDD.collect().foreach(println)
sc.stop()
}
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)