????????????????
欢迎来到本博客
❤️❤️????????
????博主优势:
????????????
博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️
座右铭:
行百里者,半于九十。
????????????
本文目录如下:
????????????
目录
????1 概述
????2 运行结果
????3 参考文献
????4 Python代码、数据、文章
????1 概述
文献来源:

SARDE:连续和自适应资源需求估计框架
摘要 资源需求是建模和预测软件系统性能的关键参数。目前,资源需求估计器通常只在系统分析时执行一次。然而,在运行时环境中,监视的系统以及资源需求本身都会不断变化。这些变化会影响各种估计方法的适用性、所需的参数化以及估计结果的准确性。随着时间的推移,这将导致无效或过时的估计,进而对自适应系统的决策产生负面影响。本文介绍了SARDE,这是一个用于连续环境中自适应资源需求估计的框架。SARDE动态地、持续地调整、选择和执行一系列资源需求估计方法,以适应环境的变化。这创造了一种自主的、无监督的集成估计技术,在动态环境中提供可靠的资源需求估计。我们使用了两个真实数据集对SARDE进行评估。其中一个数据集包含反映不同可能系统状态的不同微基准,另一个数据集包含在不断变化的环境中运行的应用程序。我们的结果表明,通过不断应用在线优化、选择和估计,SARDE能够有效地适应在线跟踪,并使用得到的集成技术减少模型误差。
及时和精确的资源需求估计是自动扩展机制[2]或用于弹性资源配置的性能建模技术[36, 69]的关键输入。因此,已经证明资源需求的统计估计是实现精确弹性云资源管理的有效和有用工具[2, 92]。资源需求(或服务需求[79])是单位工作(例如请求或交易)在系统整体访问中获得服务所花费的平均时间,不包括任何等待时间[48, 59]。不幸的是,在大多数现实系统中,在系统运行期间测量资源需求是不可行的[79],这是由于仪器开销和可能的测量干扰。因此,多年来提出了许多资源需求估计方法,使用不同的统计估计技术(例如线性回归[8, 72]或卡尔曼滤波器[88, 98])并基于排队理论的不同建模方法。
在选择适合特定场景的方法时,用户必须考虑估计方法的不同特征,例如预期的输入参数、配置设置、准确性以及对测量异常的鲁棒性。不同方法的准确性在很大程度上取决于诸如系统负载、工作负载类型、部署结构、内部状态和监控粒度等因素[79]。此外,Spinner等人[79]表明,在所有情况下没有单一的最佳方法。这与机器学习[93]和优化[94]的无免费午餐定理相一致,该定理指出当性能在所有可能的问题上平均时,任何两种算法是等效的。
解决上述问题的第一步集中在将不同的估计方法结合成一个可用的工具[80],基于测量数据优化配置参数[27, 29],并使用机器学习推荐最有前途的方法[30]。然而,现有工作侧重于一次性估计和优化,忽略了系统变化的影响。随着DevOps和弹性云操作等现代软件范式的日益普及,随着越来越多的变量不断发生变化,及时和精确的资源需求估计变得越来越复杂,估计必须不断更新。例如,任何自动扩展器都在不断改变所考虑的软件系统的部署结构。此外,在任何在线应用程序中,应用的工作负载从未真正恒定。因此,所考虑的环境在设计时是未知的,并且在操作期间不断演变[10]。随着系统和测量数据的变化,最适合的估计方法也会发生变化。因此,任何人类用户都不可能在系统运行期间持续选择、参数化和监督资源需求估计器。
因此,在本文中,我们介绍了SARDE,这是一个用于连续自适应资源需求估计的框架。SARDE能够连续地操作、参数化和选择多种不同的资源需求估计方法,并能够自主地适应所研究系统的环境变化。本文侧重于将不同的构建模块结合起来,创建一个适应性强、可在任何连续环境中应用的坚固框架,而无需专业知识。
????
2 运行结果






保存运行结果:


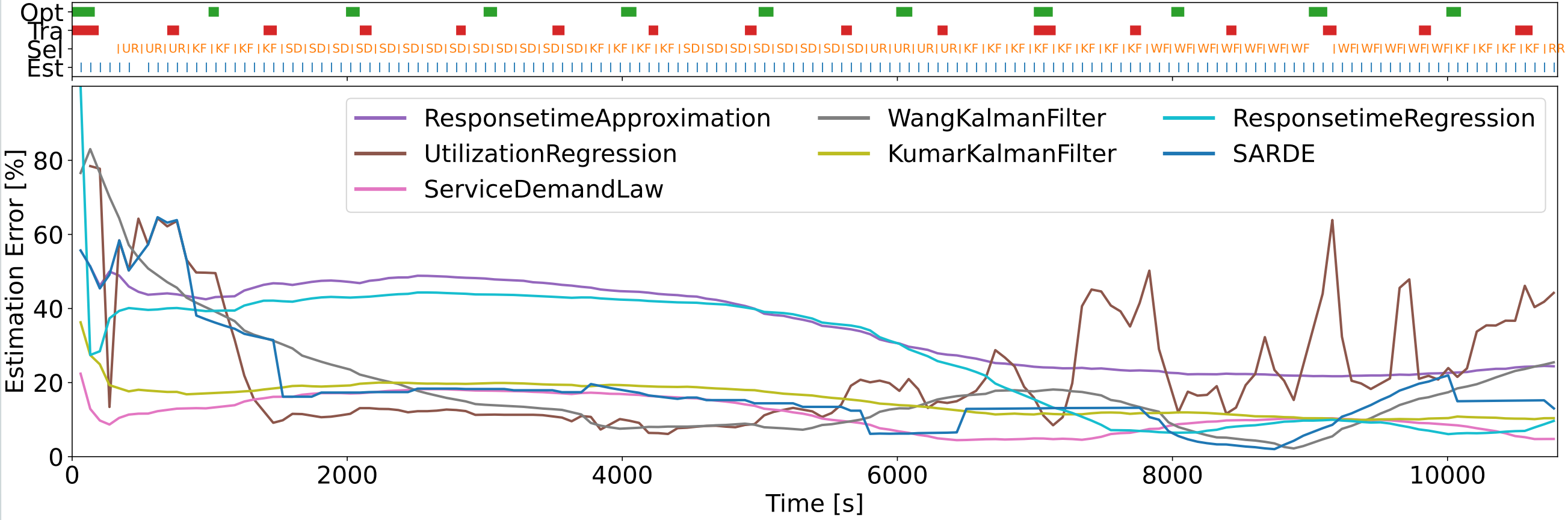
部分代码:
# Plot evaluation
respApprox = logs[(logs['Type'] == ' EVALUATION') & (
logs['Selected Approach'] == ' tools.descartes.librede.approach.ResponseTimeApproximationApproach')]
ax2.plot(respApprox['Finish time'], pd.to_numeric(respApprox[errorvec]) * 100, linewidth=plotwidth,
color=respApproxColor)
utilizationRegression = logs[(logs['Type'] == ' EVALUATION') & (
logs['Selected Approach'] == ' tools.descartes.librede.approach.UtilizationRegressionApproach')]
ax2.plot(utilizationRegression['Finish time'], pd.to_numeric(utilizationRegression[errorvec]) * 100,
linewidth=plotwidth,
color=utilizationRegressionColor)
serviceDemandLaw = logs[(logs['Type'] == ' EVALUATION') & (
logs['Selected Approach'] == ' tools.descartes.librede.approach.ServiceDemandLawApproach')]
ax2.plot(serviceDemandLaw['Finish time'], pd.to_numeric(serviceDemandLaw[errorvec]) * 100, linewidth=plotwidth,
color=serviceDemandLawColor)
wangKalmanFilter = logs[(logs['Type'] == ' EVALUATION') & (
logs['Selected Approach'] == ' tools.descartes.librede.approach.WangKalmanFilterApproach')]
ax2.plot(wangKalmanFilter['Finish time'], pd.to_numeric(wangKalmanFilter[errorvec]) * 100, linewidth=plotwidth,
color=wangKalmanFilterColor)
kumarKalmanFilter = logs[(logs['Type'] == ' EVALUATION') & (
logs['Selected Approach'] == ' tools.descartes.librede.approach.KumarKalmanFilterApproach')]
ax2.plot(kumarKalmanFilter['Finish time'], pd.to_numeric(kumarKalmanFilter[errorvec]) * 100, linewidth=plotwidth,
color=kumarKalmanFilterColor)
responsetimeRegression = logs[(logs['Type'] == ' EVALUATION') & (
logs['Selected Approach'] == ' tools.descartes.librede.approach.ResponseTimeRegressionApproach')]
ax2.plot(responsetimeRegression['Finish time'], pd.to_numeric(responsetimeRegression[errorvec]) * 100,
linewidth=plotwidth,
color=responsetimeRegressionColor)
ax2.set_xlabel("Time [s]")
ax2.set_ylabel("Estimation Error [%]")
ax2.set_xlim(xmin=0, xmax=10800)
ax2.set_yticks([0, 20, 40, 60, 80])
ax2.set_ylim(ymin=0, ymax=100)
names = ['ResponsetimeApproximation', 'UtilizationRegression', 'ServiceDemandLaw', 'WangKalmanFilter',
'KumarKalmanFilter', 'ResponsetimeRegression']
ncols = 3
ax2.legend(lines, names, ncol=ncols, loc="upper right")
# plt.xlim(0, 180)
# Finish up plot
fig.tight_layout(pad=0.1)
fig.savefig(filename)
plt.show()
????3
参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。

????
4 Python代码、数据、文章