博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业
毕业设计
项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
1、项目介绍
技术栈:
Python语言、Flask框架、MySQL数据库、requests爬虫、前程无忧全国招聘信息爬虫
2、项目界面
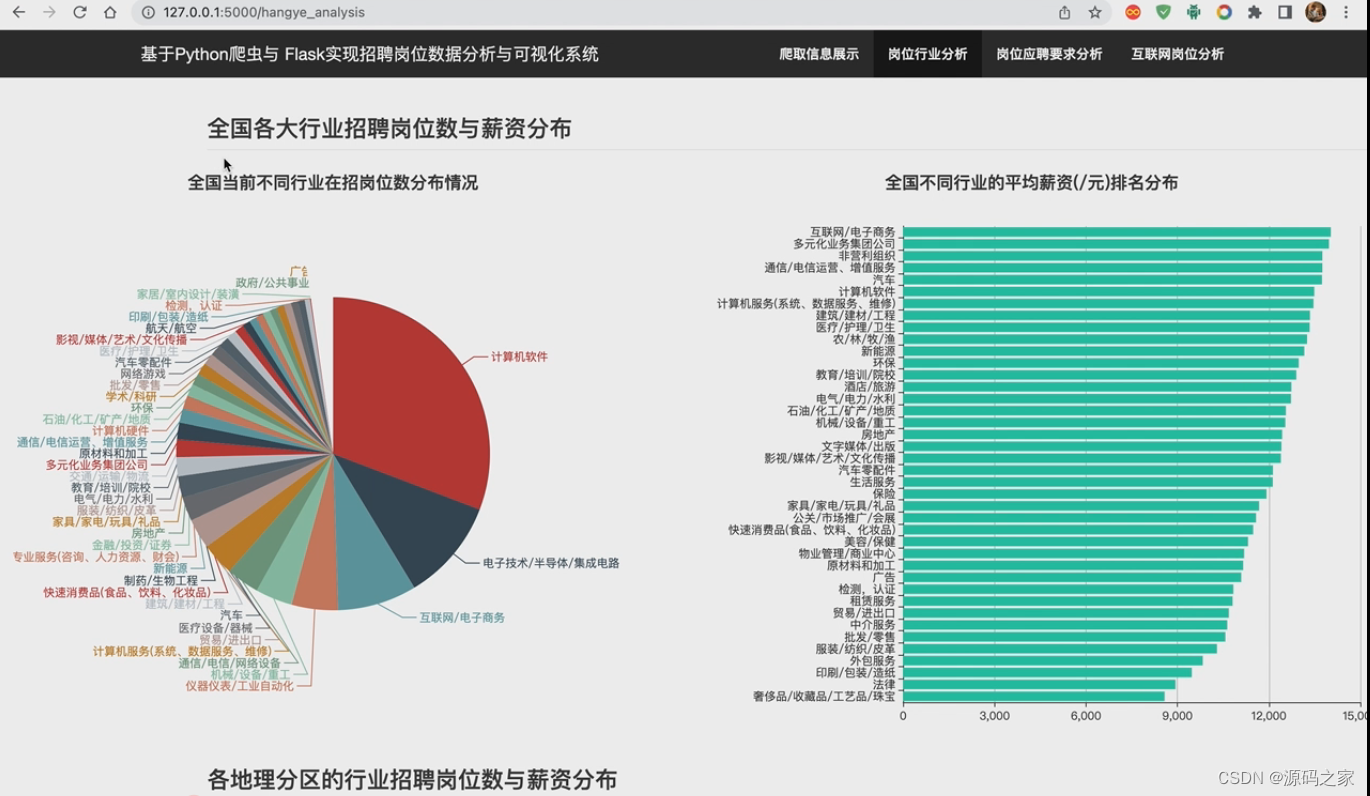
(1)岗位行业分析
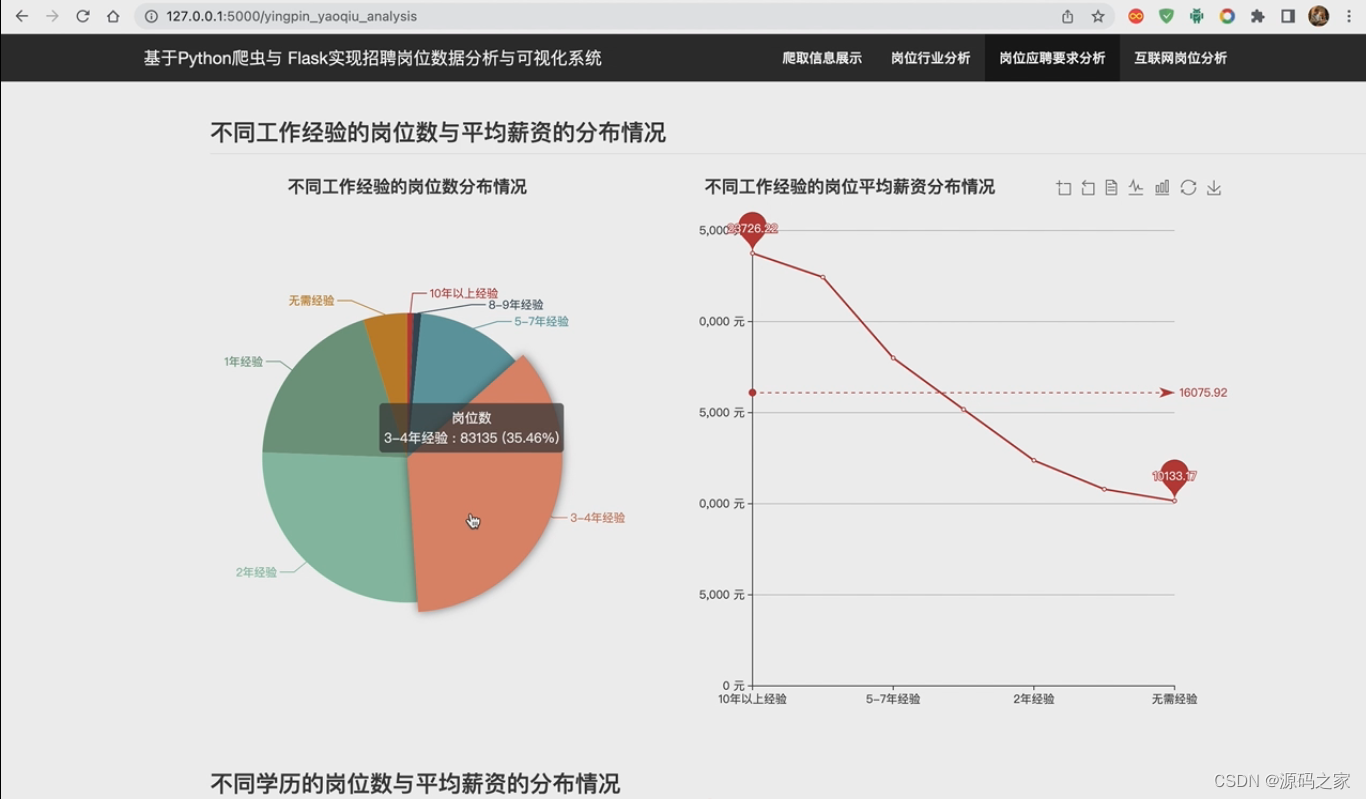
(2)岗位应聘要求分析
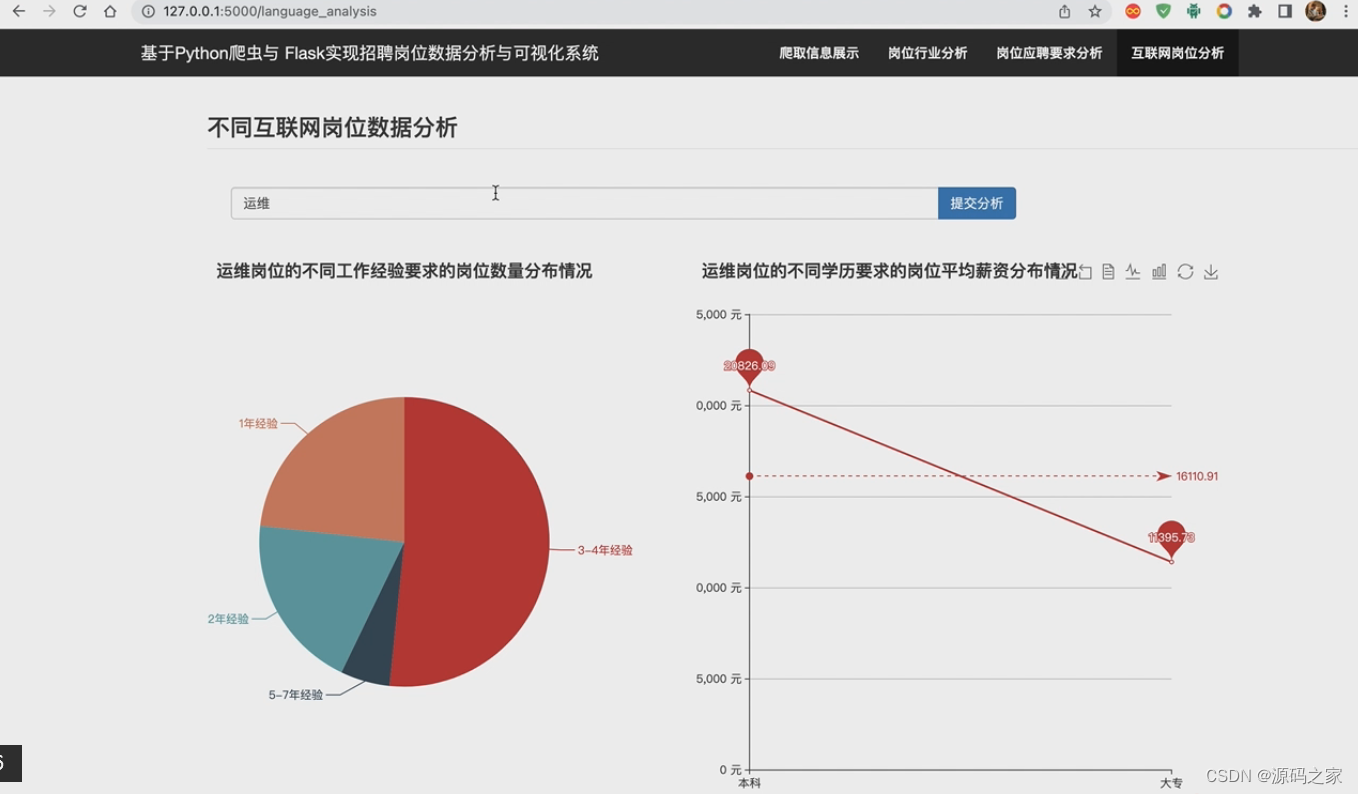
(3)互联网岗位分析
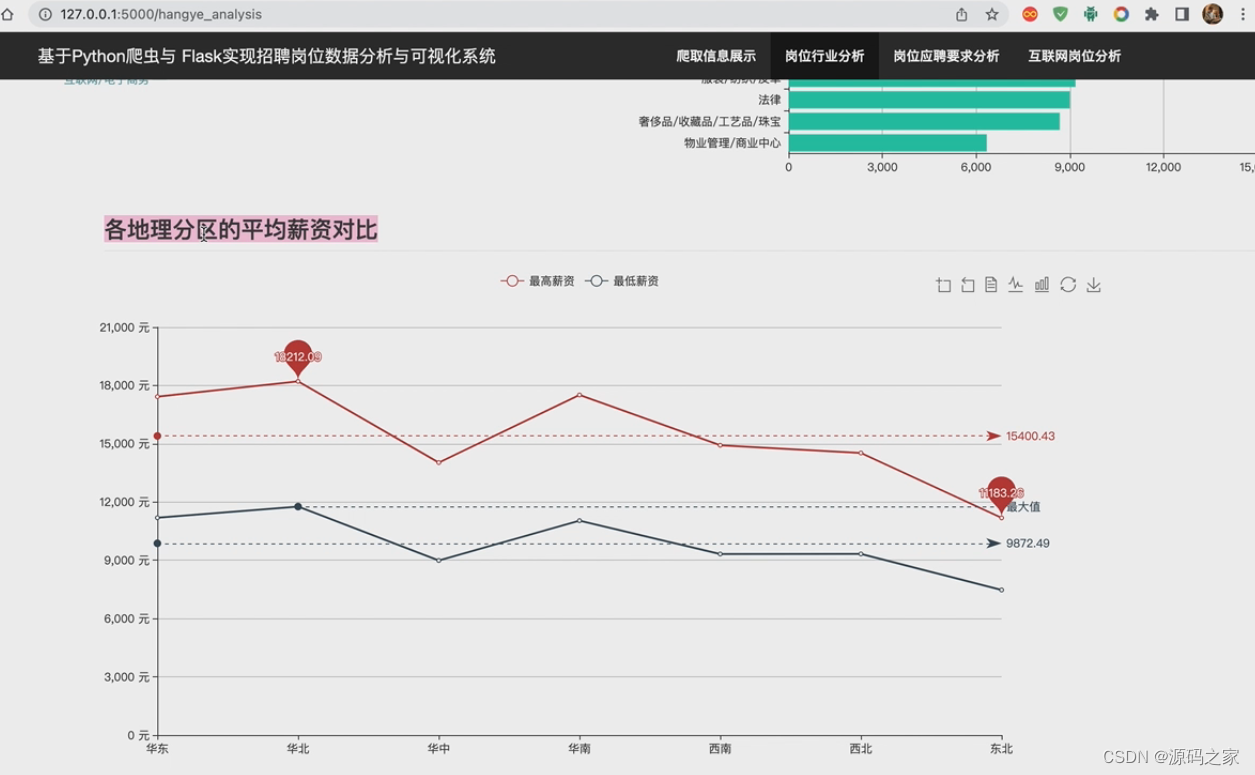
(4)各地区平均薪资分析
(5)首页注册登录界面
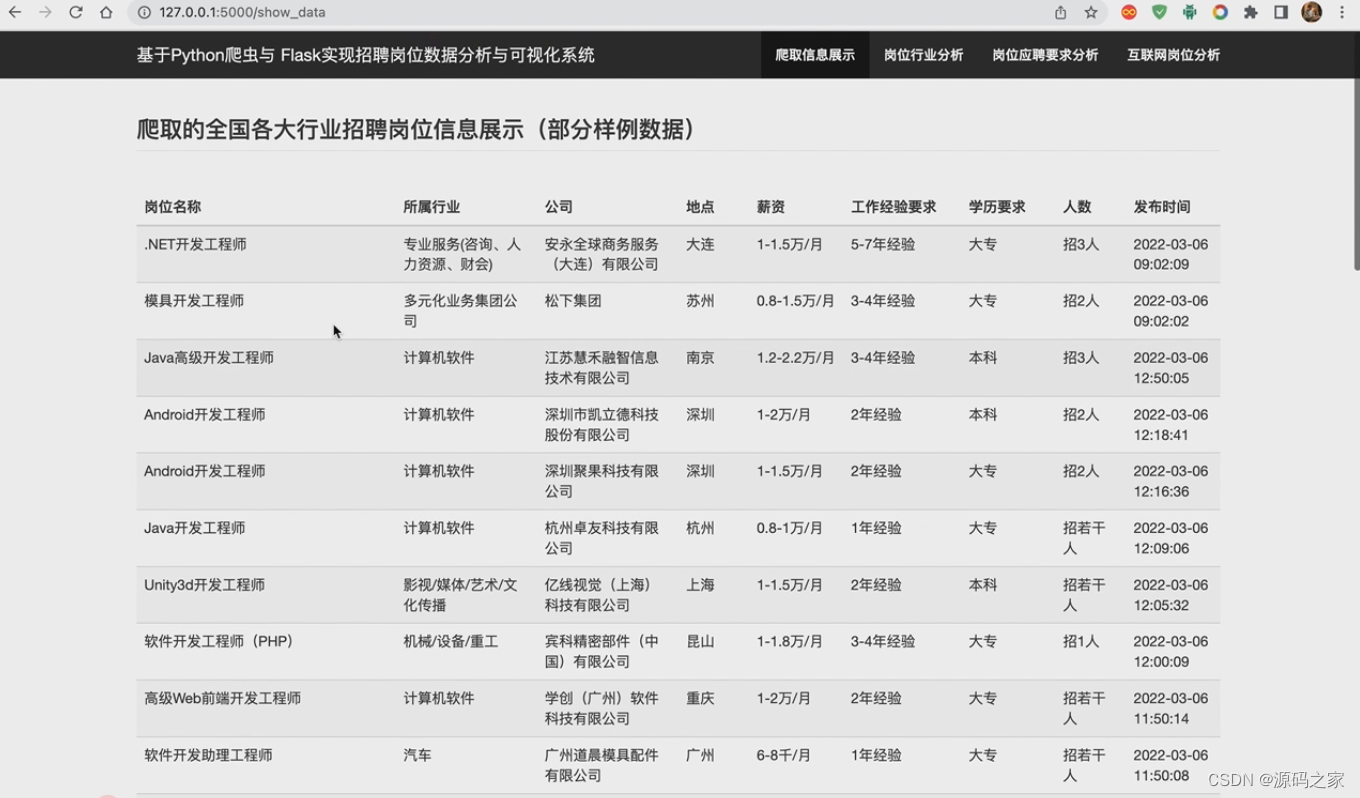
(6)招聘数据展示
3、项目说明
Flask前程无忧数据采集分析可视化系统是一个基于Flask框架开发的数据处理工具。它可以帮助用户采集、分析和可视化前程无忧网站上的就业数据。
该系统具有以下特点:
-
数据采集:系统通过爬虫技术,从前程无忧网站上获取就业数据。用户可以根据自己的需求,选择不同的搜索条件和筛选规则,获取特定的就业信息。
-
数据分析:系统提供了多种数据分析功能,帮助用户深入了解就业市场的趋势和变化。用户可以通过系统提供的统计图表和数据报告,分析不同行业、地区和职位的就业情况,从而做出更明智的职业决策。
-
可视化展示:系统通过可视化技术,将采集到的数据以图表和图形的形式展示出来。这样用户可以更直观地了解就业市场的状况,并发现潜在的就业机会。同时,系统还支持用户自定义展示方式,满足不同用户的需求。
-
用户友好性:系统注重用户体验,提供了简洁直观的界面和操作流程。用户可以快速上手,轻松完成数据采集、分析和可视化的工作。
总之,Flask前程无忧数据采集分析可视化系统是一个功能强大、易于使用的工具,帮助用户更好地了解就业市场,做出职业规划和决策。无论是求职者还是招聘方,都可以从中获得有价值的信息和洞察。
4、核心代码
#!/usr/bin/python
# coding=utf-8
import sqlite3
import pandas as pd
from flask import Flask, render_template, jsonify, request
import numpy as np
import json
import jieba
app = Flask(__name__)
app.config.from_object('config')
DATABASE = 'job_info.db'
# --------------------- html render ---------------------
login_name = None
@app.route('/')
def index():
return render_template('index.html')
@app.route('/show_data')
def show_data():
return render_template('show_data.html')
@app.route('/links')
def links():
return render_template('links.html')
@app.route('/hangye_analysis')
def hangye_analysis():
return render_template('hangye_analysis.html')
@app.route('/language_analysis')
def language_analysis():
return render_template('language_analysis.html')
@app.route('/yingpin_yaoqiu_analysis')
def yingpin_yaoqiu_analysis():
return render_template('yingpin_yaoqiu_analysis.html')
@app.route('/job_wordcloud')
def job_wordcloud():
return render_template('job_wordcloud.html')
# ------------------ ajax restful api -------------------
@app.route('/check_login')
def check_login():
"""判断用户是否登录"""
return jsonify({'username': login_name, 'login': login_name is not None})
@app.route('/register/<name>/<password>')
def register(name, password):
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
password CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "INSERT INTO user (name, password) VALUES (?,?);"
cursor.executemany(sql, [(name, password)])
conn.commit()
return jsonify({'info': '用户注册成功!', 'status': 'ok'})
@app.route('/login/<name>/<password>')
def login(name, password):
global login_name
conn = sqlite3.connect('user_info.db')
cursor = conn.cursor()
check_sql = "SELECT * FROM sqlite_master where type='table' and name='user'"
cursor.execute(check_sql)
results = cursor.fetchall()
# 数据库表不存在
if len(results) == 0:
# 创建数据库表
sql = """
CREATE TABLE user(
name CHAR(256),
password CHAR(256)
);
"""
cursor.execute(sql)
conn.commit()
print('创建数据库表成功!')
sql = "select * from user where name='{}' and password='{}'".format(name, password)
cursor.execute(sql)
results = cursor.fetchall()
login_name = name
if len(results) > 0:
print(results)
return jsonify({'info': name + '用户登录成功!', 'status': 'ok'})
else:
return jsonify({'info': '当前用户不存在!', 'status': 'error'})
# 地理分区 与 省份的映射
dili_fengqu_shengfen_maps = {
'华东': ['上海市', '江苏省', '浙江省', '安徽省', '江西省', '山东省', '福建省', '台湾省'],
'华北': ['北京市', '天津市', '山西省', '河北省', '内蒙古自治区'],
'华中': ['河南省', '湖北省', '湖南省'],
'华南': ['广东省', '广西壮族自治区', '海南省', '香港特别行政区', '澳门特别行政区'],
'西南': ['重庆市', '四川省', '贵州省', '云南省', '西藏自治区'],
'西北': ['陕西省', '甘肃省', '青海省', '宁夏回族自治区', '新疆维吾尔自治区'],
'东北': ['黑龙江省', '吉林省', '辽宁省']
}
# 省份与城市的映射
shengfen_city_dict = json.load(open('dili_fengqu.json', 'r', encoding='utf8'))
# 分区与城市的映射
dili_fengqu_cities_maps = {}
for fengqu in dili_fengqu_shengfen_maps:
cities = []
for shengfen in dili_fengqu_shengfen_maps[fengqu]:
# 省份下的所有城市
if shengfen in shengfen_city_dict:
cities.extend(shengfen_city_dict[shengfen])
dili_fengqu_cities_maps[fengqu] = set(cities)
# 城市 与 分区的映射
city_fenqu_maps = {}
for fengqu in dili_fengqu_shengfen_maps:
for shengfen in dili_fengqu_shengfen_maps[fengqu]:
if shengfen in shengfen_city_dict:
# 省份下的所有城市
for city in shengfen_city_dict[shengfen]:
city_fenqu_maps[city] = fengqu
# 加载经纬度数据
districts = json.load(open('china_region.json', 'r', encoding='utf8'))['districts']
city_region_dict = {}
for province in districts:
cities = province['districts']
for city in cities:
city_region_dict[city['name']] = {'longitude': city['center']['longitude'],
'latitude': city['center']['latitude']}
# ------------------ ajax restful api -------------------
@app.route('/query_spidered_data')
def query_spidered_data():
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
check_sql = "SELECT * FROM job"
cursor.execute(check_sql)
jobs = cursor.fetchall()
hotjobs = []
for job in jobs:
job_name, hangye, company, location, salary, jingyan, xueli, zhaopin_counts, pub_time = job
try:
tmp = float(jingyan)
jingyan = '{}年工作经验'.format(jingyan)
except:
pass
hotjobs.append((job_name, hangye, company, location, salary, jingyan, xueli, zhaopin_counts, pub_time))
return jsonify(hotjobs[:40])
@app.route('/job_hangye_analysis')
def job_hangye_analysis():
"""行业分析"""
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
check_sql = "SELECT hangye, salary FROM job"
cursor.execute(check_sql)
jobs = cursor.fetchall()
# 行业的个数
hangye_counts = {}
hangye_salary = {}
for job in jobs:
hangye, salary = job
if hangye not in hangye_counts:
hangye_counts[hangye] = 0
hangye_counts[hangye] += 1
if not salary.endswith('/月'):
continue
if salary.endswith('千/月'):
scale = 1000
elif salary.endswith('万/月'):
scale = 10000
else:
continue
salary = salary[:-3]
# 计算平均薪资
salary = sum(map(float, salary.split('-'))) / 2 * scale
if hangye not in hangye_salary:
hangye_salary[hangye] = []
hangye_salary[hangye].append(salary)
hangye_counts = list(zip(list(hangye_counts.keys()), list(hangye_counts.values())))
hangye_counts = sorted(hangye_counts, key=lambda k: k[1], reverse=True)
# 过滤掉一些在招岗位很少的行业
hangye_counts = [v for v in hangye_counts if v[1] > 10]
hangye1 = [v[0] for v in hangye_counts][:40]
counts = [v[1] for v in hangye_counts][:40]
# 计算行业的平均薪资
for hangye in hangye_salary:
hangye_salary[hangye] = np.mean(hangye_salary[hangye])
hangye_salary = list(zip(list(hangye_salary.keys()), list(hangye_salary.values())))
hangye_salary = sorted(hangye_salary, key=lambda k: k[1], reverse=False)
hangye2 = [v[0] for v in hangye_salary][:40]
salary = [v[1] for v in hangye_salary][:40]
return jsonify({'行业': hangye1, '岗位数': counts, '行业2': hangye2, '平均薪资': salary})
@app.route('/dili_fengqu_analysis/<fengqu>')
def dili_fengqu_analysis(fengqu):
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
check_sql = "SELECT hangye, location, salary FROM job"
cursor.execute(check_sql)
jobs = cursor.fetchall()
# 行业的个数
hangye_counts = {}
hangye_salary = {}
for job in jobs:
hangye, location, salary = job
if location + '市' not in city_fenqu_maps:
continue
if city_fenqu_maps[location + '市'] != fengqu:
continue
if hangye not in hangye_counts:
hangye_counts[hangye] = 0
hangye_counts[hangye] += 1
if not salary.endswith('/月'):
continue
if salary.endswith('千/月'):
scale = 1000
elif salary.endswith('万/月'):
scale = 10000
else:
continue
salary = salary[:-3]
# 计算平均薪资
salary = sum(map(float, salary.split('-'))) / 2 * scale
if hangye not in hangye_salary:
hangye_salary[hangye] = []
hangye_salary[hangye].append(salary)
hangye_counts = list(zip(list(hangye_counts.keys()), list(hangye_counts.values())))
hangye_counts = sorted(hangye_counts, key=lambda k: k[1], reverse=True)
# 过滤掉一些在招岗位很少的行业
hangye1 = [v[0] for v in hangye_counts][:20]
counts = [v[1] for v in hangye_counts][:20]
# 计算行业的平均薪资
for hangye in hangye_salary:
hangye_salary[hangye] = np.mean(hangye_salary[hangye])
hangye_salary = list(zip(list(hangye_salary.keys()), list(hangye_salary.values())))
hangye_salary = sorted(hangye_salary, key=lambda k: k[1], reverse=False)
hangye2 = [v[0] for v in hangye_salary][:20]
salary = [v[1] for v in hangye_salary][:20]
high_salary_hangyes = ' > '.join(hangye2[::-1][:3])
return jsonify({'行业': hangye1, '岗位数': counts, '行业2': hangye2, '平均薪资': salary,
'高薪行业推荐': high_salary_hangyes})
@app.route('/fengqu_salary_analysis')
def fengqu_salary_analysis():
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
check_sql = "SELECT hangye, location, salary FROM job"
cursor.execute(check_sql)
jobs = cursor.fetchall()
fengqu_high_salary = {'华东': [], '华北': [], '华中': [], '华南': [], '西南': [], '西北': [], '东北': []}
fengqu_low_salary = {'华东': [], '华北': [], '华中': [], '华南': [], '西南': [], '西北': [], '东北': []}
for job in jobs:
hangye, location, salary = job
if location + '市' not in city_fenqu_maps:
continue
if not salary.endswith('/月'):
continue
if salary.endswith('千/月'):
scale = 1000
elif salary.endswith('万/月'):
scale = 10000
else:
continue
fengqu = city_fenqu_maps[location + '市']
salary = salary[:-3]
low_salary, high_salary = map(float, salary.split('-'))
fengqu_high_salary[fengqu].append(high_salary * scale)
fengqu_low_salary[fengqu].append(low_salary * scale)
fengqu = ['华东', '华北', '华中', '华南', '西南', '西北', '东北']
high_salary = [np.mean(fengqu_high_salary[fq]) for fq in fengqu]
low_salary = [np.mean(fengqu_low_salary[fq]) for fq in fengqu]
return jsonify({'fengqu': fengqu, 'high_salary': high_salary, 'low_salary': low_salary})
@app.route('/query_yingpin_yaoqiu/<search>')
def query_yingpin_yaoqiu(search):
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
check_sql = "SELECT jingyan, xueli, salary, job_name FROM job"
cursor.execute(check_sql)
jobs = cursor.fetchall()
jingyan_salary = {}
xueli_salary = {}
for job in jobs:
jingyan, xueli, salary, job_name = job
if search != '无':
if search.lower() not in job_name.lower():
continue
try:
jingyan = int(jingyan)
jingyan = '{}年经验'.format(str(jingyan))
except:
pass
if jingyan not in jingyan_salary:
jingyan_salary[jingyan] = []
if xueli not in xueli_salary:
xueli_salary[xueli] = []
if not salary.endswith('/月'):
continue
if salary.endswith('千/月'):
scale = 1000
elif salary.endswith('万/月'):
scale = 10000
else:
continue
salary = salary[:-3]
# 计算平均薪资
salary = sum(map(float, salary.split('-'))) / 2 * scale
jingyan_salary[jingyan].append(salary)
xueli_salary[xueli].append(salary)
jingyan_job_counts = {}
for jingyan in jingyan_salary:
jingyan_job_counts[jingyan] = len(jingyan_salary[jingyan])
jingyan_salary[jingyan] = np.mean(jingyan_salary[jingyan])
jingyan_salary = list(zip(list(jingyan_salary.keys()), list(jingyan_salary.values())))
jingyan_salary = sorted(jingyan_salary, key=lambda k: k[1], reverse=True)
jingyan = [v[0] for v in jingyan_salary]
jingyan_salary = [v[1] for v in jingyan_salary]
jingyan_job_counts = [jingyan_job_counts[jy] for jy in jingyan]
xueli_job_counts = {}
for xueli in xueli_salary:
xueli_job_counts[xueli] = len(xueli_salary[xueli])
xueli_salary[xueli] = np.mean(xueli_salary[xueli] + [0])
xueli_salary = list(zip(list(xueli_salary.keys()), list(xueli_salary.values())))
xueli_salary = sorted(xueli_salary, key=lambda k: k[1], reverse=True)
xueli = [v[0] for v in xueli_salary if '人' not in v[0]]
xueli_salary = [v[1] for v in xueli_salary if '人' not in v[0]]
xueli_job_counts = [xueli_job_counts[xl] for xl in xueli]
results = {'经验': jingyan, '经验平均薪资': jingyan_salary, '经验岗位数': jingyan_job_counts,
'学历': xueli, '学历平均薪资': xueli_salary, '学历岗位数': xueli_job_counts}
return jsonify(results)
@app.route('/query_city_salary_region')
def query_city_salary_region():
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
check_sql = "SELECT location, salary FROM job"
cursor.execute(check_sql)
jobs = cursor.fetchall()
city_salary = {}
city_region = {}
for job in jobs:
location, salary = job
if not salary.endswith('/月'):
continue
if salary.endswith('千/月'):
scale = 1000
elif salary.endswith('万/月'):
scale = 10000
else:
continue
salary = salary[:-3]
# 计算平均薪资
salary = sum(map(float, salary.split('-'))) / 2 * scale
city = location + '市'
if city not in city_region_dict:
continue
if city not in city_salary:
city_salary[city] = []
city_salary[city].append(salary)
loc = city_region_dict[city]
city_region[city] = [loc['longitude'], loc['latitude']]
city_mean_salary = []
for city in city_salary:
city_mean_salary.append({'name': city, 'value': np.mean(city_salary[city])})
results = {'city_mean_salary': city_mean_salary, 'city_region': city_region}
print(results)
return jsonify(results)
@app.route('/get_all_hangye')
def get_all_hangye():
"""获取所有行业"""
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
sql = 'select distinct hangye from job'
cursor.execute(sql)
hangyes = cursor.fetchall()
hangyes = [h[0] for h in hangyes]
print(hangyes)
return jsonify(hangyes)
@app.route('/hangye_fengqu_salary')
def hangye_fengqu_salary():
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
hangye = request.args.get('hangye')
print(hangye)
check_sql = "SELECT hangye, location, salary FROM job where hangye=='{}'".format(hangye)
cursor.execute(check_sql)
jobs = cursor.fetchall()
fengqu_salary = {}
for job in jobs:
hangye, location, salary = job
if location + '市' not in city_fenqu_maps:
continue
fengqu = city_fenqu_maps[location + '市']
if not salary.endswith('/月'):
continue
if salary.endswith('千/月'):
scale = 1000
elif salary.endswith('万/月'):
scale = 10000
else:
continue
salary = salary[:-3]
# 计算平均薪资
salary = sum(map(float, salary.split('-'))) / 2 * scale
if fengqu not in fengqu_salary:
fengqu_salary[fengqu] = []
fengqu_salary[fengqu].append(salary)
# 计算平均薪资
for fengqu in fengqu_salary:
fengqu_salary[fengqu] = np.mean(fengqu_salary[fengqu])
fengqu_salary = list(zip(list(fengqu_salary.keys()), list(fengqu_salary.values())))
fengqu_salary = sorted(fengqu_salary, key=lambda k: k[1], reverse=False)
fengqu = [v[0] for v in fengqu_salary]
salary = [v[1] for v in fengqu_salary]
max_salary = max(salary)
return jsonify({'分区': fengqu, '平均薪资': salary, '最高薪资': max_salary})
if __name__ == "__main__":
app.run(host='127.0.0.1')
????✌
感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!
????✌
源码获取:
????
由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。
????
点赞、收藏、关注,不迷路,
下方查看
????????
获取联系方式
????????