windows11编译OpenCV4.5.0 with CUDA

从OpenCV4.2.0 版本开始允许使用 Nvidia GPU 来加速推理。本文介绍最近使用windows11系统编译带CUDA的OpenCV4.5.0的过程。
- 文中使用【特别注意:…】为大家标识出容易出错的地方。
- 安装成功后,使用CPU与GPU调用yolov4模型进行推理的耗时测试结果:
- 从差距上看,还是值得花时间编译一下的:)
- 耗时测试环境:
- 调用笔记本自带摄像头获取视频
- Notebook GTX3080显卡
1.准备环境
1.1 下载OpenCV4.5.0
- 编译需要OpenCV4.5.0的源码
- 下载地址(3项可选):
https://opencv.org/releases/
https://github.com/opencv/opencv/releases/tag/4.5.0
https://sourceforge.net/projects/opencvlibrary/files/4.5.0/opencv-4.5.0-vc14_vc15.exe/download
- 下载完成后是一个exe程序,双击即可解压,解压后:
- source文件夹就是源码
- build文件夹是编译好的不带CUDA加速的OpenCV4.5.0(本文不使用)
1.2 下载OpenCV4.5.0 contrib
- Contrib Modules是OpenCV的扩展模块,包含了很多用于实现特定算法
- 编译OpenCV需要用到contirb模块
- 特别注意:务必下载与源码对应版本的contrib模块
- 下载地址(第1个为官方下载地址,第2个为国内某同学搭建的下载库,速度较快):
https://github.com/opencv/opencv_contrib/tags
https://www.raoyunsoft.com/opencv/opencv_contrib/opencv_contrib-4.5.0.zip
1.3 准备.cache文件
- 编译过程中需要联网下载一些依赖库,并存放于sourc.cache文件夹中
- 特别注意:因要连到外网,因此速度比较慢,有时断网造成编译失败,所以可以提前准备好这些文件
- OpenCV4.5.0的.cache文件下载地址:
https://download.csdn.net/download/iracer/85695997
- 使用方法:
- 将.cache文件夹拷贝到source文件夹下,与原.cache文件夹合并
1.4 安装Visual Studio 2019
- 安装CUDA需要vs,这里选择vs2019
- 安装步提要:
- Download Visual Studio 2019 Community Edition
- Select Desktop Development with C++ option and click on install
1.5 安装CUDA和cuDNN
- NVIDIA官方指南:
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-windows
- 本次在windows11上安装的CUDA和cuDNN版本为:
- CUDA 11.3:cuda_11.3.1_465.89_win10.exe
- duDNN 8.4:cudnn-windows-x86_64-8.4.0.27_cuda11.6-archive.zip
- 特别注意:zlib库需要下载并添加到系统环境变量path中,因为cdDNN需要调用该库。
- zlib库下载地址:
www.winimage.com/zLibDll/zlib123dllx64.zip
下载完成后解压zip文件,并将zlibwapi.dll所在目录添加到系统环境变量path中
- 查看CUDA安装结果:
C:\Users\irace>nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Mon_May__3_19:41:42_Pacific_Daylight_Time_2021
Cuda compilation tools, release 11.3, V11.3.109
Build cuda_11.3.r11.3/compiler.29920130_0
1.6 安装CMake
- 本次是用的是3.22版本,3.19以上版本应该都可以(未逐一测试)
- 下载地址:
https://github.com/Kitware/CMake/releases/download/v3.22.5/cmake-3.22.5-windows-x86_64.msi
2. 编译
2.1 CMake生成解决方案
-
双击解压OpenCV4.5.0.exe,解压后的source目录即OpenCV4.5.0的源码
-
解压opencv_contrib-4.5.0
-
新建一个编译目录
D:\opencv\oepncv4.5.0cuda\build
-
打开CMake
-
配置source code:
D:/opencv/opencv4.5.0/sources
-
配置目标目录:
D:\opencv\oepncv4.5.0cuda\build
-
第1次点击[Configure]
-
弹出窗口选择vs2019作为编译器:
Visual Studio 16 2019
-
generate平台选择x64
-
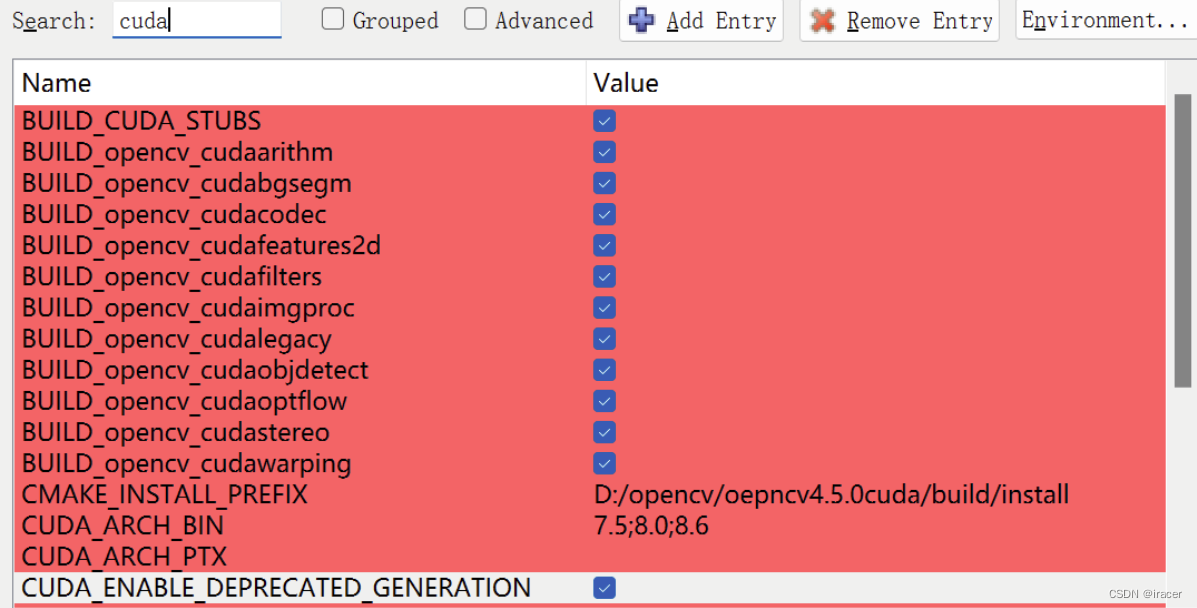
第2次点击[Configure]后,搜cuda带cuda的都勾选,
- CMake界面上Search栏搜modules,设置contrib模块路径
D:\opencv\oepncv4.5.0cuda\opencv_contrib-4.5.0\modules
-
第3次点击[Configure],完成后,再次搜索cuda,配置CUDA_ARCH_BIN中将显卡的算力内容改成自己显卡的算力,t如下网址查询自己显卡的算力,我保留了7.5;8.0;8.6
GeForce 笔记本
| GPU | Compute Capability |
|---|
| GeForce RTX 3080 | 8.6 |
| GeForce RTX 3070 | 8.6 |
| GeForce RTX 3060 | 8.6 |
| GeForce RTX 3050 Ti | 8.6 |
| GeForce RTX 3050 | 8.6 |
| Geforce RTX 2080 | 7.5 |
| Geforce RTX 2070 | 7.5 |
| Geforce RTX 2060 | 7.5 |
| GeForce GTX 1080 | 6.1 |
| GeForce GTX 1070 | 6.1 |
| GeForce GTX 1060 | 6.1 |
GeForce and TITAN 台式机
| GPU | Compute Capability |
|---|
| Geforce RTX 3060 Ti | 8.6 |
| Geforce RTX 3060 | 8.6 |
| GeForce RTX 3090 | 8.6 |
| GeForce RTX 3080 | 8.6 |
| GeForce RTX 3070 | 8.6 |
| GeForce GTX 1650 Ti | 7.5 |
| NVIDIA TITAN RTX | 7.5 |
| Geforce RTX 2080 Ti | 7.5 |
| Geforce RTX 2080 | 7.5 |
| Geforce RTX 2070 | 7.5 |
| Geforce RTX 2060 | 7.5 |
| NVIDIA TITAN V | 7.0 |
-
搜索并勾选
BUILD_opencv_world,可生成一个整的dll方便使用
OPENCV_ENABLE_NONFREF
-
解压.cache.rar,将.cache目录拷贝到source目录:
D:\opencv\oepncv4.5.0\source\.cache >
配置完成后CMake log中显示找到了CUDA和cuDNN:
NVIDIA CUDA: YES (ver 11.3, CUFFT CUBLAS FAST_MATH)
NVIDIA GPU arch: 75 80 86
NVIDIA PTX archs:
cuDNN: YES (ver 8.4.0)
-
点击[Open Project],会自动打开vs2019,开始编译
2.2 VS2019编译OpenCV
-
使用VS2019打开刚刚编译工程后,等待左下角显示的项全部加载完毕才可以继续操作
-
选择Release x64版本

-
找到解决方案资源管理器中的“CmakeTargets”下的“ALL_BUILD”,右键→“生成”,然后开始漫长的等待……
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nNqwu0Ta-1655631459263)(E:\software\opencv\opencv编译GPU\image-20220616221804612.png)]](https://img-blog.csdnimg.cn/be49d1456e334ffe99fe3a6e39df8113.png)
-
解决方案资源管理器—>CMakeTargets—>INSTALL—>生成”然后又是等,好在这次时间很短。完成后你的build文件夹中会出现一个install文件夹,这就是完成了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fVI9AP2K-1655631459263)(E:\software\opencv\opencv编译GPU\image-20220617072231198.png)]](https://img-blog.csdnimg.cn/36751ba55cf0461baf2dcc12a40f0eaa.png)
2.3 生成文件
D:\opencv\oepncv4.5.0cuda\build\install>tree
3. 测试
3.1 配置OpenCV with cuda
- 配置OpenCV4.5.0cuda,与一般OpenCV的配置方法一致,可参考:
- Win7系统Visual Studio 2013配置OpenCV3.1图文详解
3.2 YOLOv4 示例程序
- 测试程序可以直接用《OpenCV4机器学习算法原理与编程实战》书中的代码(部分):
#include<opencv2\opencv.hpp>
#include<opencv2\dnn.hpp>
#include<fstream>
#include<iostream>
using namespace std;
// 检测结果后处理
void postProcess(
cv::dnn::Net& net,
cv::Mat& frame,
const vector<cv::Mat>& outs,
vector<cv::Rect>& boxes,
vector<int>& classIds,
vector<int>& indices,
double confThreshold,
double nmsThreshold
);
// 检测绘制结果
void drawPred(
cv::Mat& frame,
vector<cv::Rect>& boxes,
vector<int>& classIds,
vector<int>& indices,
vector<string>& classNamesVec);
// 程序设置
bool USE_IMAGE = false; // true: 测试图像; false: 测试视频
bool USE_YOLOv4 = true; // true: YOLOv4; false: YOLOv4_tiny
bool USE_CUDA = true; // true: GPU, false: CPU
float confidenceThreshold = 0.3; // 置信度设置
float nmsThreshold = 0.2; // 置信MNS门限
int main()
{
// [1]模型文件路径设置
cv::String model, config;
if (USE_YOLOv4)
{
model = "D:/models/yolov4/yolov4.weights"; // 模型权重文件
config = "D:/models/yolov4/yolov4.cfg"; // 模型配置文件
}
else // use yolov4-tiny
{
model = "D:/models/yolov4/yolov4-tiny.weights";
config = "D:/models/yolov4/yolov4-tiny.cfg";
}
cv::String framework = "Darknet"; // 深度学习框架
cv::String label_file = "D:/models/yolov4/coco.names";// 类别标签文件
//[2] 加载类别
ifstream classNamesFile(label_file);
vector<string> classNamesVec;
if (classNamesFile.is_open())
{
string className = "";
while (std::getline(classNamesFile, className))
{
classNamesVec.push_back(className);
}
}
// [3]载入模型
cv::dnn::Net net = cv::dnn::readNet(config, model, framework);
if (USE_CUDA)
{
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
}
else
{
net.setPreferableTarget(cv::dnn::DNN_TARGET_OPENCL);
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
}
// ...
}
4. 相关链接
- OpenCV4机器学习算法原理与编程实战(附部分模型下载地址)
- 本文更新链接
- 转载请注明出处。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)