hbase是Hadoop生态系统中重要的一员,他是基于google bigtable的思想开发出来的开源列簇数据库。hbase的运行环境依赖于hdfs,zookeeper,这里介绍完全分布式安装。
前提:jdk安装,ssh免秘钥登录,hadoop安装,zookeeper安装。
我这里的环境:3台centos7,jdk1.8,hadoop-2.8.0,zookeeper-3.4.10,这里hbase采用一主两从的集群方式。
一、下载并解压hbase(主节点linux-node1),http://mirrors.hust.edu.cn/apache/hbase
二、配置hbase,修改conf目录下的三个配置文件。
hbase-env.sh
export JAVA_HOME=/usr/java/latest
export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://linux-node1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>linux-node1,linux-node2,linux-node3</value>
</property>
</configuration>
regionservers
linux-node2
linux-node3
将配置好的hbase分别传输到linux-node2,linux-node3。
scp -rq hbase-1.0.0 root@linux-node2:/home/hadoop/
scp -rq hbase-1.0.0 root@linux-node3:/home/hadoop/
三、启动hbase
bin/start-hbase.sh
启动成功的话,可以看到本机多了HMaster进程,而另外两台机器上分别启动了HRegionServer进程。


四、通过hbase shell操作hbase
进入hbase命令行
bin/hbase shell
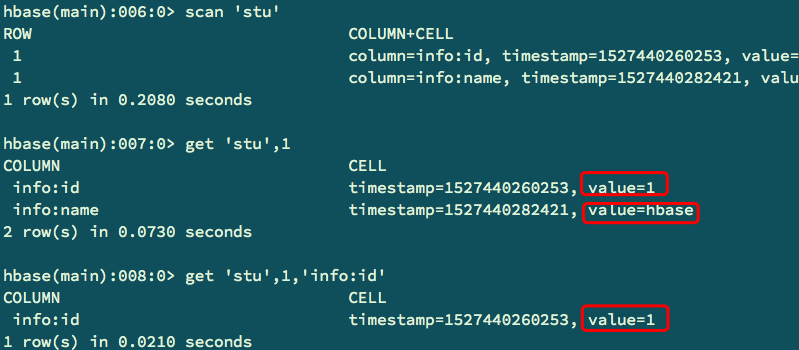
//创建表 直接 create 'stu','info',所有的表,列簇,均需要采用单引号。

//添加数据,put命令

//查看表,以及表数据 list scan get
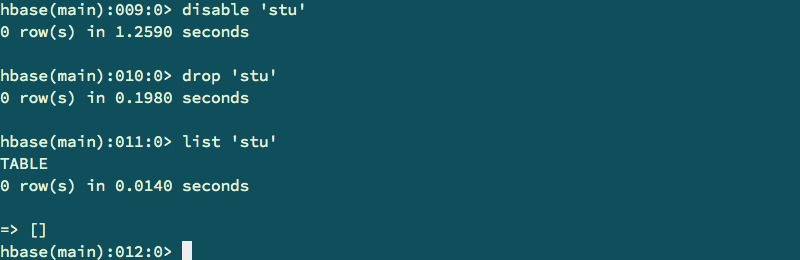
//删除表,需要先disable表,然后drop表。
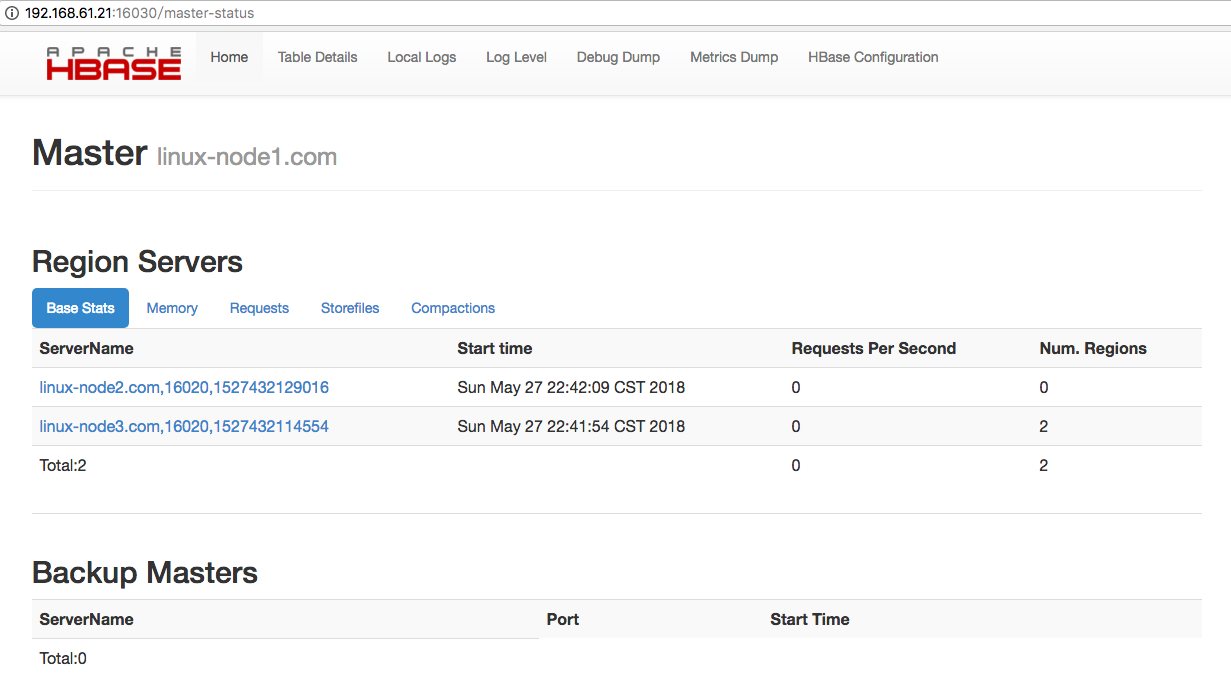
web ui界面,通过浏览器访问地址:http://192.168.61.21:16030
如果需要停止hbase集群,那么在master节点上运行bin/stop-hbase.sh。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)